2024-10-28 08:00:00
There's a common narrative that Microsoft was moribund under Steve Ballmer and then later saved by the miraculous leadership of Satya Nadella. This is the dominant narrative in every online discussion about the topic I've seen and it's a commonly expressed belief "in real life" as well. While I don't have anything negative to say about Nadella's leadership in this post, this narrative underrates Ballmer's role in Microsoft's success. Not only did Microsoft's financials, revenue and profit, look great under Ballmer, Microsoft under Ballmer made deep, long-term bets that set up Microsoft for success in the decades after his reign. At the time, the bets were widely panned, indicating that they weren't necessarily obvious, but we can see in retrospect that the company made very strong bets despite the criticism at the time.
In addition to overseeing deep investments in areas that people would later credit Nadella for, Ballmer set Nadella up for success by clearing out political barriers for any successor. Much like Gary Bernhardt's talk, which was panned because he made the problem statement and solution so obvious that people didn't realize they'd learned something non-trivial, Ballmer set up Microsoft for future success so effectively that it's easy to criticize him for being a bum because his successor is so successful.
For people who weren't around before the turn of the century, in the 90s, Microsoft used to be considered the biggest, baddest, company in town. But it wasn't long before people's opinions on Microsoft changed — by 2007, many people thought of Microsoft as the next IBM and Paul Graham wrote Microsoft is Dead, in which he noted that Microsoft being considered effective was ancient history:
A few days ago I suddenly realized Microsoft was dead. I was talking to a young startup founder about how Google was different from Yahoo. I said that Yahoo had been warped from the start by their fear of Microsoft. That was why they'd positioned themselves as a "media company" instead of a technology company. Then I looked at his face and realized he didn't understand. It was as if I'd told him how much girls liked Barry Manilow in the mid 80s. Barry who?
Microsoft? He didn't say anything, but I could tell he didn't quite believe anyone would be frightened of them.
These kinds of comments often came with comments that Microsoft's revenue was destined to fall, such as these comments by Graham:
Actors and musicians occasionally make comebacks, but technology companies almost never do. Technology companies are projectiles. And because of that you can call them dead long before any problems show up on the balance sheet. Relevance may lead revenues by five or even ten years.
Graham names Google and the web as primary causes of Microsoft's death, which we'll discuss later. Although Graham doesn't name Ballmer or note his influence in Microsoft is Dead, Ballmer has been a favorite punching bag of techies for decades. Ballmer came up on the business side of things and later became EVP of Sales and Support; techies love belittling non-technical folks in tech1. A common criticism, then and now, is that Ballmer didn't understand tech and was a poor leader because all he knew was sales and the bottom line and all he can do is copy what other people have done. Just for example, if you look at online comments on tech forums (minimsft, HN, slashdot, etc.) when Ballmer pushed Sinofsky out in 2012, Ballmer's leadership is nearly universally panned2. Here's a fairly typical comment from someone claiming to be an anonymous Microsoft insider:
Dump Ballmer. Fire 40% of the workforce starting with the loser online services (they are never going to get any better). Reinvest the billions in start-up opportunities within the puget sound that can be accretive to MSFT and acquisition targets ... Reset Windows - Desktop and Tablet. Get serious about business cloud (like Salesforce ...)
To the extent that Ballmer defended himself, it was by pointing out that the market appeared to be undervaluing Microsoft. Ballmer noted that Microsoft's market cap at the time was extremely low relative to its fundamentals/financials relative to Amazon, Google, Apple, Oracle, IBM, and Salesforce. This seems to have been a fair assessment by Ballmer as Microsoft has outperformed all of those companies since then.
When Microsoft's market cap took off after Nadella became CEO, it was only natural the narrative would be that Ballmer was killing Microsoft and that the company was struggling until Nadella turned it around. You can pick other discussions if you want, but just for example, if we look at the most recent time Microsoft is Dead hit #1 on HN, a quick ctrl+F has Ballmer's name showing up 24 times. Ballmer has some defenders, but the standard narrative that Ballmer was holding Microsoft back is there, and one of the defenders even uses part of the standard narrative: Ballmer was an unimaginative hack, but he at least set up Microsoft well financially. If you look at high ranking comments, they're all dunking on Ballmer.
And if you look on less well informed forums, like Twitter or Reddit, you see the same attacks, but Ballmer has fewer defenders. On Twitter, when I search for "Ballmer", the first four results are unambiguously making fun of Ballmer. The fifth hit could go either way, but from the comments, seems to generally be taken as making of Ballmer, and as I far as I scrolled down, all but one of the remaining videos was making fun of Ballmer (the one that wasn't was an interview where Ballmer notes that he offered Zuckerberg "$20B+, something like that" for Facebook in 2009, which would've been the 2nd largest tech acquisition ever at the time, second only to Carly Fiorina's acquisition of Compaq for $25B in 2001). Searching reddit (incognito window with no history) is the same story (excluding the stories about him as an NBA owner, where he's respected by fans). The top story is making fun of him, the next one notes that he's wealthier than Bill Gates and the top comment on his performance as a CEO starts with "The irony is that he is Microsofts [sic] worst CEO" and then has the standard narrative that the only reason the company is doing well is due to Nadella saving the day, that Ballmer missed the boat on all of the important changes in the tech industry, etc.
To sum it up, for the past twenty years, people having been dunking on Ballmer for being a buffoon who doesn't understand tech and who was, at best, some kind of bean counter who knew how to keep the lights on but didn't know how to foster innovation and caused Microsoft to fall behind in every important market.
The common view is at odds with what actually happened under Ballmer's leadership. In financially material positive things that happened under Ballmer since Graham declared Microsoft dead, we have:
There are certainly plenty of big misses as well. From 2010-2015, HoloLens was one of Microsoft's biggest bets, behind only Azure and then Bing, but no one's big AR or VR bets have had good returns to date. Microsoft failed to capture the mobile market. Although Windows Phone was generally well received by reviewers who tried it, depending on who you ask, Microsoft was either too late or wasn't willing to subsidize Windows Phone for long enough. Although .NET is still used today, in terms of marketshare, .NET and Silverlight didn't live up to early promises and critical parts were hamstrung or killed as a side effect of internal political battles. Bing is, by reputation, a failure and, at least given Microsoft's choices at the time, probably needed antitrust action against Google to succeed, but this failure still resulted in a business unit worth hundreds of billions of dollars. And despite all of the failures, the biggest bet, Azure, is probably worth on the order of a trillion dollars.
The enterprise sales arm of Microsoft was built out under Ballmer before he was CEO (he was, for a time, EVP for Sales and Support, and actually started at Microsoft as the first business manager) and continued to get built out when Ballmer was CEO. Microsoft's sales playbook was so effective that, when I was Microsoft, Google would offer some customers on Office 365 Google's enterprise suite (Docs, etc.) for free. Microsoft salespeople noted that they would still usually be able to close the sale of Microsoft's paid product even when competing against a Google that was giving their product away. For the enterprise, the combination of Microsoft's offering and its enterprise sales team was so effective that Google couldn't even give its product away.
If you're reading this and you work at a "tech" company, the company is overwhelmingly likely to choose the Google enterprise suite over the Microsoft enterprise suite and the enterprise sales pitch Microsoft sales people have probably sounds ridiculous to you.
An acquaintance of mine who ran a startup had a Microsoft Azure salesperson come in and try to sell them on Azure, opening with "You're on AWS, the consumer cloud. You need Azure, the enterprise cloud". For most people in tech companies, enterprise is synonymous with overpriced, unreliable, junk. In the same way it's easy to make fun of Ballmer because he came up on the sales and business side of the house, it's easy to make fun of an enterprise sales pitch when you hear it but, overall, Microsoft's enterprise sales arm does a good job. When I worked in Azure, I looked into how it worked and, having just come from Google, there was a night and day difference. This was in 2015, under Nadella, but the culture and processes that let Microsoft scale this up were built out under Ballmer. I think there were multiple months where Microsoft hired and onboarded more salespeople than Google employed in total and every stage of the sales pipeline was fairly effective.
When people point to a long list of failures like Bing, Zune, Windows Phone, and HoloLens as evidence that Ballmer was some kind of buffoon who was holding Microsoft back, this demonstrates a lack of understanding of the tech industry. This is like pointing to a list of failed companies a VC has funded as evidence the VC doesn't know what they're doing. But that's silly in a hits based industry like venture capital. If you want to claim the VC is bad, you need to point out poor total return or a lack of big successes, which would imply poor total return. Similarly, a large company like Microsoft has a large portfolio of bets and one successful bet can pay for a huge number of failures. Ballmer's critics can't point to a poor total return because Microsoft's total return was very good under his tenure. Revenue increased from $14B or $22B to $83B, depending on whether you want to count from when Ballmer became President in July 1998 or when Ballmer became CEO in January 2000. The company was also quite profitable when Ballmer left, recording $27B in profit the previous four quarters, more than the revenue of the company he took over. By market cap, Azure alone would be in the top 10 largest public companies in the world and the enterprise software suite minus Azure would probably just miss being in the top 10.
As a result, critics also can't point to a lack of hits when Ballmer presided over the creation of Azure, the conversion of Microsoft's enterprise software from set of local desktop apps to Office 365 et al., the creation of the world's most effective enterprise sales org, the creation of Microsoft's video game empire (among other things, Ballmer was CEO when Microsoft acquired Bungie and made Halo the Xbox's flagship game on launch in 2001), etc. Even Bing, widely considered a failure, on last reported revenue and current P/E ratio, would be 12th most valuable tech company in the world, between Tencent and ASML. When attacking Ballmer, people cite Bing as a failure that occurred on Ballmer's watch, which tells you something about the degree of success Ballmer had. Most companies would love to have their successes be as successful as Bing, let alone their failures. Of course it would be better if Ballmer was prescient and all of his bets succeeded, making Microsoft worth something like $10T instead of the lowly $3T market cap it has today, but the criticism of Ballmer that says that he had some failures and some $1T successes is a criticism that he wasn't the greatest CEO of all time by a gigantic margin. True, but not much of a criticism.
And, unlike Nadella, Ballmer didn't inherit a company that was easily set up for success. As we noted earlier, it wasn't long into Ballmer's tenure that Microsoft was considered a boring, irrelevant company and the next IBM, mostly due to decisions made when Bill Gates was CEO. As a very senior Microsoft employee from the early days, Ballmer was also partially responsible for the state of Microsoft at the time, so Microsoft's problems are also at least partially attributable to him (but that also means he should get some credit for the success Microsoft had through the 90s). Nevertheless, he navigated Microsoft's most difficult problems well and set up his successor for smooth sailing.
Earlier, we noted that Paul Graham cited Google and the rise of the web as two causes for Microsoft's death prior to 2007. As we discussed in this look at antitrust action in tech, these both share a common root cause, antitrust action against Microsoft. If we look at the documents from the Microsoft antitrust case, it's clear that Microsoft knew how important the internet was going to be and had plans to control the internet. As part of these plans, they used their monopoly power on the desktop to kill Netscape. They technically lost an antirust case due to this, but if you look at the actual outcomes, Microsoft basically got what they wanted from the courts. The remedies levied against Microsoft are widely considered to have been useless (the initial decision involved breaking up Microsoft, but they were able to reverse this on appeal), and the case dragged on for long enough that Netscape was doomed by the time the case was decided, and the remedies that weren't specifically targeted at the Netscape situation were meaningless.
A later part of the plan to dominate the web, discussed at Microsoft but never executed, was to kill Google. If we're judging Microsoft by how "dangerous" it is, how effectively it crushes its competitors, like Paul Graham did when he judged Microsoft to be dead, then Microsoft certainly became less dangerous, but the feeling at Microsoft was that their hand was forced due to the circumstances. One part of the plan to kill Google was to redirect users who typed google.com into their address bar to MSN search. This was before Chrome existed and before mobile existed in any meaningful form. Windows desktop marketshare was 97% and IE had between 80% to 95% marketshare depending on the year, with most of the rest of the marketshare belonging to the rapidly declining Netscape. If Microsoft makes this move, Google is killed before it can get Chrome and Android off the ground and, barring extreme antitrust action, such as a breakup of Microsoft, Microsoft owns the web to this day. And then for dessert, it's not clear there wouldn't be a reason to go after Amazon.
After internal debate, Microsoft declined to kill Google not due to fear of antitrust action, but due to fear of bad PR from the ensuing antitrust action. Had Microsoft redirected traffic away from Google, the impact on Google would've been swifter and more severe than their moves against Netscape and in the time it would take for the DoJ to win another case against Microsoft, Google would suffer the same fate as Netscape. It might be hard to imagine this if you weren't around at the time, but the DoJ vs. Microsoft case was regular front-page news in a way that we haven't seen since (in part because companies learned their lesson on this one — Google supposedly killed the 2011-2012 FTC against them with lobbying and has cleverly maneuvered the more recent case so that it doesn't dominate the news cycle in the same way). The closest thing we've seen since the Microsoft antitrust media circus was the media response to the Crowdstrike outage, but that was a flash in the pan compared to the DoJ vs. Microsoft case.
If there's a criticism of Ballmer here, perhaps it's something like Microsoft didn't pre-emptively learn the lessons its younger competitors learned from its big antitrust case before the big antitrust case. A sufficiently prescient executive could've advocated for heavy lobbying to head the antitrust case off at pass, like Google did in 2011-2012, or maneuvered to make the antitrust case just another news story, like Google has been doing for the current case. Another possible criticism is that Microsoft didn't correctly read the political tea leaves and realize that there wasn't going to be serious US tech antitrust for at least two decades after the big case against Microsoft. In principle, Ballmer could've overridden the decision to not kill Google if he had the right expertise on staff to realize that the United States was entering a two decade period of reduced antitrust scrutiny in tech.
As criticisms go, I think the former criticism is correct, but not an indictment of Ballmer unless you expect CEOs to be infallible, so as evidence that Ballmer was a bad CEO, this would be a very weak criticism. And it's not clear that the latter criticism is correct. While Google was able to get away with things like hardcoding the search engine in Android to prevent users from changing their search engine setting to having badware installers trick users into making Chrome the default browser, they were considered the "good guys" and didn't get much scrutiny for these sorts of actions, Microsoft wasn't treated with kid gloves in the same way by the press or the general public. Google didn't trigger a serious antitrust investigation until 2011, so it's possible the lack of serious antitrust action between 2001 and 2010 was an artifact of Microsoft being careful to avoid antitrust scrutiny and Google being too small to draw scrutiny and that a move to kill Google when it was still possible would've drawn serious antitrust scrutiny and another PR circus. That's one way in which the company Ballmer inherited was in a more difficult situation than its competitors — Microsoft's hands were perceived to be tied and may have actually been tied. Microsoft could and did get severe criticism for taking an action when the exact same action taken by Google would be lauded as clever.
When I was at Microsoft, there was a lot of consternation about this. One funny example was when, in 2011, Google officially called out Microsoft for unethical behavior and the media jumped on this as yet another example of Microsoft behaving badly. A number of people I talked to at Microsoft were upset by this because, according to them, Microsoft got the idea to do this when they noticed that Google was doing it, but reputations take a long time to change and actions taken while Gates was CEO significantly reduced Microsoft's ability to maneuver.
Another difficulty Ballmer had to deal with on taking over was Microsoft's intense internal politics. Again, as a very senior Microsoft employee going back to almost the beginning, he bears some responsibility for this, but Ballmer managed to clear the board of the worst bad actors so that Nadella didn't inherit such a difficult situation. If we look at why Microsoft didn't dominate the web under Ballmer, in addition to concerns that killing Google would cause a PR backlash, internal political maneuvering killed most of Microsoft's most promising web products and reduced the appeal and reach of most of the rest of its web products. For example, Microsoft had a working competitor to Google Docs in 1997, one year before Google was founded and nine years before Google acquired Writely, but it was killed for political reasons. And likewise for NetMeeting and other promising products. Microsoft certainly wasn't alone in having internal political struggles, but it was famous for having more brutal politics than most.
Although Ballmer certainly didn't do a perfect job at cleaning house, when I was at Microsoft and asked about promising projects that were sidelined or killed due to internal political struggles, the biggest recent sources of those issues were shown the door under Ballmer, leaving a much more functional company for Nadella to inherit.
Stepping back to look at the big picture, Ballmer inherited a company that was a financially strong position that was hemmed in by internal and external politics in a way that caused outside observers to think the company was overwhelmingly likely to slide into irrelevance, leading to predictions like Graham's famous prediction that Microsoft is dead, with revenues expected to decline in five to ten years. In retrospect, we can see that moves made under Gates limited Microsoft's ability to use its monopoly power to outright kill competitors, but there was no inflection point at which a miraculous turnaround was mounted. Instead, Microsoft continued its very strong execution on enterprise products and continued making reasonable bets on the future in a successful effort to supplant revenue streams that were internally viewed as long-term dead ends, even if they were going to be profitable dead ends, such as Windows and boxed (non-subscription) software.
Unlike most companies in that position, Microsoft was willing to very heavily subsidize a series of bets that leadership thought could power the company for the next few decades, such as Windows Phone, Bing, Azure, Xbox, and HoloLens. From the internal and external commentary on these bets, you can see why it's so hard for companies to use their successful lines of business to subsidize new lines of business when the writing is on the wall for the successful businesses. People panned these bets as stupid moves that would kill the company, saying the company should focus is efforts on its most profitable businesses, such as Windows. Even when there's very clear data showing that bucking the status quo is the right thing, people usually don't do it, in part because you look like an idiot when it doesn't pan out, but Ballmer was willing to make the right bets in the face of decades of ridicule.
Another reason it's hard for companies to make these bets is that companies are usually unable to launch new things that are radically different from their core business. When yet another non-acquisition Google consumer product fails, every writes this off as a matter of course — of course Google failed there, they're a technical-first company that's bad at product. But Microsoft made this shift multiple times and succeeded. Once was with Xbox. If you look at the three big console manufacturers, two are hardware companies going way back and one is Microsoft, a boxed software company that learned how to make hardware. Another time was with Azure. If you look at the three big cloud providers, two are online services companies going back to their founding and one is Microsoft, a boxed software company that learned how to get into the online services business. Other companies with different core lines of business than hardware and online services saw these opportunities and tried to make the change and failed.
And if you look at the process of transitioning here, it's very easy to make fun of Microsoft in the same way it's easy to make fun of Microsoft's enterprise sales pitch. The core Azure folks came from Windows, so in the very early days of Azure, they didn't have an incident management process to speak of and during their first big global outages, people were walking around the hallways asking "is it Azure down?" and trying to figure out what to do. Azure would continue to have major global outages for years while learning how to ship somewhat reliable software, but they were able to address the problems well enough to build a trillion dollar business. Another time, before Azure really knew how to build servers, a Microsoft engineer pulled up Amazon's pricing page and noticed that AWS's retail price for disk was cheaper than Azure's cost to provision disks. When I was at Microsoft, a big problem for Azure was building out datacenter fast enough. People joked that the recent hiring of a ton of sales people worked too well and the company sold too much Azure, which was arguably true and also a real emergency for the company. In the other cases, Microsoft mostly learned how to do it themselves and in this case they brought in some very senior people from Amazon who had deep expertise in supply chain and building out datacenters. It's easy to say that, when you have a problem and a competitor has the right expertise, you should hire some experts and listen to them but most companies fail when they try to do this. Sometimes, companies don't recognize that they need help but, more frequently, they do bring in senior expertise that people don't listen to. It's very easy for the old guard at a company to shut down efforts to bring in senior outside expertise, especially at a company as fractious at Microsoft, but leadership was able to make sure that key initiatives like this were successful3.
When I talked to Google engineers about Azure during Azure's rise, they were generally down on Azure and would make fun of it for issues like the above, which seemed comical to engineers working at a companies that grew up as large scale online services companies with deep expertise in operating large scale services, building efficient hardware, and building out datacenter, but despite starting in a very deep hole technically, operationally, and culturally, Microsoft built a business unit worth a trillion dollars with Azure.
Not all of the bets panned out, but if we look at comments from critics who were saying that Microsoft was doomed because it was subsidizing the wrong bets or younger companies would surpass it, well, today, Microsoft is worth 50% more than Google and twice as much as Meta. If we look at the broader history of the tech industry, Microsoft has had sustained strong execution from its founding in 1975 until today, a nearly fifty year run, a run that's arguably been unmatched in the tech industry. Intel's been around as bit longer, but they stumbled very badly around the turn of the century and they've had a number of problems over the past decade. IBM has a long history, but it just wasn't all that big during its early history, e.g., when T.J. Watson renamed Computing-Tabulating-Recording Company to International Business Machines, its revenue was still well under $10M a year (inflation adjusted, on the order of $100M a year). Computers started becoming big and IBM was big for a tech company by the 50s, but the antitrust case brought against IBM in 1969 that dragged on until it was dropped for being "without merit" in 1982 hamstrung the company and its culture in ways that are still visible when you look at, for example, why IBM's various cloud efforts have failed and, in the 90s, the company was on its deathbed and only managed to survive at all due to Gerstner's turnaround. If we look at older companies that had long sustained runs of strong execution, most of them are gone, like DEC and Data General, or had very bad stumbles that nearly ended the company, like IBM and Apple. There are companies that have had similarly long periods of strong execution, like Oracle, but those companies haven't been nearly as effective as Microsoft in expanding their lines of business and, as a result, Oracle is worth perhaps two Bings. That makes Oracle the 20th most valuable public company in the world, which certainly isn't bad, but it's no Microsoft.
If Microsoft stumbles badly, a younger company like Nvidia, Meta, or Google could overtake Microsoft's track record, but that would be no fault of Ballmer's and we'd still have to acknowledge that Ballmer was a very effective CEO, not just in terms of bringing the money in, but in terms of setting up a vision that set Microsoft up for success for the next fifty years.
Besides the headline items mentioned above, off the top of my head, here are a few things I thought were interesting that happened under Ballmer since Graham declared Microsoft to be dead
One response to Microsoft's financial success, both the direct success that happened under Ballmer as well as later success that was set up by Ballmer, is that Microsoft is financially successful but irrelevant for trendy programmers, like IBM. For one thing, rounded to the nearest Bing, IBM is probably worth either zero or one Bings. But even if we put aside the financial aspect and we just look at how much each $1T tech company (Apple, Nvidia, Microsoft, Google, Amazon, and Meta) has impacted programmers, Nvidia, Apple, and Microsoft all have a lot of programmers who are dependent on the company due to some kind of ecosystem dependence (CUDA; iOS; .NET and Windows, the latter of which is still the platform of choice for many large areas, such as AAA games).
You could make a case for the big cloud vendors, but I don't think that companies have a nearly forced dependency on AWS in the same way that a serious English-language consumer app company really needs an iOS app or an AAA game company has to release on Windows and overwhelmingly likely develops on Windows.
If we look at programmers who aren't pinned to an ecosystem, Microsoft seems highly relevant to a lot of programmers due to the creation of tools like vscode and TypeScript. I wouldn't say that it's necessarily more relevant than Amazon since so many programmers use AWS, but it's hard to argue that the company that created (among many other things) vscode and TypeScript under Ballmer's watch is irrelevant to programmers.
Shortly after joining Microsoft in 2015, I bet Derek Chiou that Google would beat Microsoft to $1T market cap. Unlike most external commentators, I agreed with the bets Microsoft was making, but when I looked around at the kinds of internal dysfunction Microsoft had at the time, I thought that would cause them enough problems that Google would win. That was wrong — Microsoft beat Google to $1T and is now worth $1T more than Google.
I don't think I would've made the bet even a year later, after seeing Microsoft from the inside and how effective Microsoft sales was and how good Microsoft was at shipping things that are appealing to enterprises and the comparing that to Google's cloud execution and strategy. But you could say that I made a mistake that was fairly analogous to what external commentators made until I saw how Microsoft operated in detail.
Thanks to Laurence Tratt, Yossi Kreinin, Heath Borders, Justin Blank, Fabian Giesen, Justin Findlay, Matthew Thomas, Seshadri Mahalingam, and Nam Nguyen for comments/corrections/discussion
Here's the top HN comment on a story about Sinofsky's ousting:
The real culprit that needs to be fired is Steve Ballmer. He was great from the inception of MSFT until maybe the turn of the century, when their business strategy of making and maintaining a Windows monopoly worked beautifully and extremely profitably. However, he is living in a legacy environment where he believes he needs to protect the Windows/Office monopoly BY ANY MEANS NECESSARY, and he and the rest of Microsoft can't keep up with everyone else around them because of innovation.
This mindset has completely stymied any sort of innovation at Microsoft because they are playing with one arm tied behind their backs in the midst of trying to compete against the likes of Google, Facebook, etc. In Steve Ballmer's eyes, everything must lead back to the sale of a license of Windows/Office, and that no longer works in their environment.
If Microsoft engineers had free rein to make the best search engine, or the best phone, or the best tablet, without worries about how will it lead to maintaining their revenue streams of Windows and more importantly Office, then I think their offerings would be on an order of magnitude better and more creative.
This is wrong. At the time, Microsoft was very heavily subsidizing Bing. To the extent that one can attribute the subsidy, it would be reasonable to say that the bulk of the subsidy was coming from Windows. Likewise, Azure was a huge bet that was being heavily subsidized from the profit that was coming from Windows. Microsoft's strategy under Ballmer was basically the opposite of what this comment is saying.
Funnily enough, if you looked at comments on minimsft (many of which were made by Microsoft insiders), people noted the huge spend on things like Azure and online services, but most thought this was a mistake and that Microsoft needed to focus on making Windows and Windows hardware (like the Surface) great.
Basically, no matter what people think Ballmer is doing, they say it's wrong and that he should do the opposite. That means people call for different actions since most commenters outside of Microsoft don't actually know what Microsoft is up to, but from the way the comments are arrayed against Ballmer and not against specific actions of the company, we can see that people aren't really making a prediction about any particular course of action and they're just ragging on Ballmer.
BTW, the #2 comment on HN says that Ballmer missed the boat on the biggest things in tech in the past 5 years and that Ballmer has deemphasized cloud computing (which was actually Microsoft's biggest bet at the time if you look at either capital expenditure or allocated headcount). The #3 comment says "Steve Ballmer is a sales guy at heart, and it's why he's been able to survive a decade of middling stock performance and strategic missteps: He must have close connections to Microsoft's largest enterprise customers, and were he to be fired, it would be an invitation for those customers to reevaluate their commitment to Microsoft's platforms.", and the rest of the top-level comments aren't about Ballmer.
[return]2024-08-11 08:00:00
About eight years ago, I was playing a game of Codenames where the game state was such that our team would almost certainly lose if we didn't correctly guess all of our remaining words on our turn. From the given clue, we were unable to do this. Although the game is meant to be a word guessing game based on word clues, a teammate suggested that, based on the physical layout of the words that had been selected, most of the possibilities we were considering would result in patterns that were "too weird" and that we should pick the final word based on the location. This worked and we won.
[Click to expand explanation of Codenames if you're not familiar with the game]
Codenames is played in two teams. The game has a 5x5 grid of words, where each word is secretly owned by one of {blue team, red team, neutral, assassin}. Each team has a "spymaster" who knows the secret word <-> ownership mapping. The spymaster's job is to give single-word clues that allow their teammates to guess which words belong to their team without accidentally guessing words of the opposing team or the assassin. On each turn, the spymaster gives a clue and their teammates guess which words are associated with the clue. The game continues until one team's words have all been guessed or the assassin's word is guessed (immediate loss). There are some details that are omitted here for simplicity, but for the purposes of this post, this explanation should be close enough. If you want more of an explanation, you can try this video, or the official rules
Ever since then, I've wondered how good someone would be if all they did was memorize all 40 setup cards that come with the game. To simulate this, we'll build a bot that plays using only position information would be (you might also call this an AI, but since we'll discuss using an LLM/AI to write this bot, we'll use the term bot to refer to the automated codenames playing agent to make it easy to disambiguate).
At the time, after the winning guess, we looked through the configuration cards to see if our teammate's idea of guessing based on shape was correct, and it was — they correctly determined the highest probability guess based on the possible physical configurations. Each card layout defines which words are your team's and which words belong to the other team and, presumably to limit the cost, the game only comes with 40 cards (160 configurations under rotation). Our teammate hadn't memorized the cards (which would've narrowed things down to only one possible configuration), but they'd played enough games to develop an intuition about what patterns/clusters might be common and uncommon, enabling them to come up with this side-channel attack against the game. For example, after playing enough games, you might realize that there's no card where a team has 5 words in a row or column, or that only the start player color ever has 4 in a row, and if this happens on an edge and it's blue, the 5th word must belong to the red team, or that there's no configuration with six connected blue words (and there is one with red, one with 2 in a row centered next to 4 in a row). Even if you don't consciously use this information, you'll probably develop a subconscious aversion to certain patterns that feel "too weird".
Coming back to the idea of building a bot that simulates someone who's spent a few days memorizing the 40 cards, below, there's a simple bot you can play against that simulates a team of such players. Normally, when playing, you'd provide clues and the team would guess words. But, in order to provide the largest possible advantage to you, the human, we'll give you the unrealistically large advantage of assuming that you can, on demand, generate a clue that will get your team to select the exact squares that you'd like, which is simulated by letting you click on any tile that you'd like to have your team guess that tile.
By default, you also get three guesses a turn, which would put you well above 99%-ile among Codenames players I've seen. While good players can often get three or more correct moves a turn, averaging three correct moves and zero incorrect moves a turn would be unusually good in most groups. You can toggle the display of remaining matching boards on, but if you want to simulate what it's like to be a human player who hasn't memorized every board, you might want to try playing a few games with the display off.
If, at any point, you finish a turn and it's the bot's turn and there's only one matching board possible, the bot correctly guesses every one of its words and wins. The bot would be much stronger if it ever guessed words before it can guess them all, either naively or to strategically reduce the search space, or if it even had a simple heuristic where it would randomly guess among the possible boards if it could deduce that you'd win on your next turn, but even when using the most naive "board memorization" bot possible has been able to beat every Codenames player who I handed this to in most games where they didn't toggle the remaining matching boards on and use the same knowledge the bot has access to.
2024-06-16 08:00:00
There've been regular viral stories about ML/AI bias with LLMs and generative AI for the past couple years. One thing I find interesting about discussions of bias is how different the reaction is in the LLM and generative AI case when compared to "classical" bugs in cases where there's a clear bug. In particular, if you look at forums or other discussions with lay people, people frequently deny that a model which produces output that's sort of the opposite of what the user asked for is even a bug. For example, a year ago, an Asian MIT grad student asked Playground AI (PAI) to "Give the girl from the original photo a professional linkedin profile photo" and PAI converted her face to a white face with blue eyes.
The top "there's no bias" response on the front-page reddit story, and one of the top overall comments, was
Sure, now go to the most popular Stable Diffusion model website and look at the images on the front page.
You'll see an absurd number of asian women (almost 50% of the non-anime models are represented by them) to the point where you'd assume being asian is a desired trait.
How is that less relevant that "one woman typed a dumb prompt into a website and they generated a white woman"?
Also keep in mind that she typed "Linkedin", so anyone familiar with how prompts currently work know it's more likely that the AI searched for the average linkedin woman, not what it thinks is a professional women because image AI doesn't have an opinion.
In short, this is just an AI ragebait article.
Other highly-ranked comments with the same theme include
Honestly this should be higher up. If you want to use SD with a checkpoint right now, if you dont [sic] want an asian girl it’s much harder. Many many models are trained on anime or Asian women.
and
Right? AI images even have the opposite problem. The sheer number of Asians in the training sets, and the sheer number of models being created in Asia, means that many, many models are biased towards Asian outputs.
Other highly-ranked comments noted that this was a sample size issue
"Evidence of systemic racial bias"
Shows one result.
Playground AI's CEO went with the same response when asked for an interview by the Boston Globe — he declined the interview and replied with a list of rhetorical questions like the following (the Boston Globe implies that there was more, but didn't print the rest of the reply):
If I roll a dice just once and get the number 1, does that mean I will always get the number 1? Should I conclude based on a single observation that the dice is biased to the number 1 and was trained to be predisposed to rolling a 1?
We could just have easily picked an example from Google or Facebook or Microsoft or any other company that's deploying a lot of ML today, but since the CEO of Playground AI is basically asking someone to take a look at PAI's output, we're looking at PAI in this post. I tried the same prompt the MIT grad student used on my Mastodon profile photo, substituting "man" for "girl". PAI usually turns my Asian face into a white (caucasian) face, but sometimes makes me somewhat whiter but ethnically ambiguous (maybe a bit Middle Eastern or East Asian or something. And, BTW, my face has a number of distinctively Vietnamese features and which pretty obviously look Vietnamese and not any kind of East Asian.



My profile photo is a light-skinned winter photo, so I tried a darker-skinned summer photo and PAI would then generally turn my face into a South Asian or African face, with the occasional Chinese (but never Vietnamese or kind of Southeast Asian face), such as the following:


A number of other people also tried various prompts and they also got results that indicated that the model (where “model” is being used colloquially for the model and its weights and any system around the model that's responsible for the output being what it is) has some preconceptions about things like what ethnicity someone has if they have a specific profession that are strong enough to override the input photo. For example, converting a light-skinned Asian person to a white person because the model has "decided" it can make someone more professional by throwing out their Asian features and making them white.
Other people have tried various prompts to see what kind of pre-conceptions are bundled into the model and have found similar results, e.g., Rob Ricci got the following results when asking for "linkedin profile picture of X professor" for "computer science", "philosophy", "chemistry", "biology", "veterinary science", "nursing", "gender studies", "Chinese history", and "African literature", respectively. In the 28 images generated for the first 7 prompts, maybe 1 or 2 people out of 28 aren't white. The results for the next prompt, "Chinese history" are wildly over-the-top stereotypical, something we frequently see from other models as well when asking for non-white output. And Andreas Thienemann points out that, except for the over-the-top Chinese stereotypes, every professor is wearing glasses, another classic stereotype.



Like I said, I don't mean to pick on Playground AI in particular. As I've noted elsewhere, trillion dollar companies regularly ship AI models to production without even the most basic checks on bias; when I tried ChatGPT out, every bias-checking prompt I played with returned results that were analogous to the images we saw here, e.g., when I tried asking for bios of men and women who work in tech, women tended to have bios indicating that they did diversity work, even for women who had no public record of doing diversity work and men tended to have degrees from name-brand engineering schools like MIT and Berkeley, even people who hadn't attended any name-brand schools, and likewise for name-brand tech companies (the link only has 4 examples due to Twitter limitations, but other examples I tried were consistent with the examples shown).
This post could've used almost any publicly available generative AI. It just happens to use Playground AI because the CEO's response both asks us to do it and reflects the standard reflexive "AI isn't biased" responses that lay people commonly give.
Coming back to the response about how it's not biased for professional photos of people to be turned white because Asians feature so heavily in other cases, the high-ranking reddit comment we looked at earlier suggested "go[ing] to the most popular Stable Diffusion model website and look[ing] at the images on the front page". Below is what I got when I clicked the link on the day the comment was made and then clicked "feed".
[Click to expand / collapse mildly NSFW images]
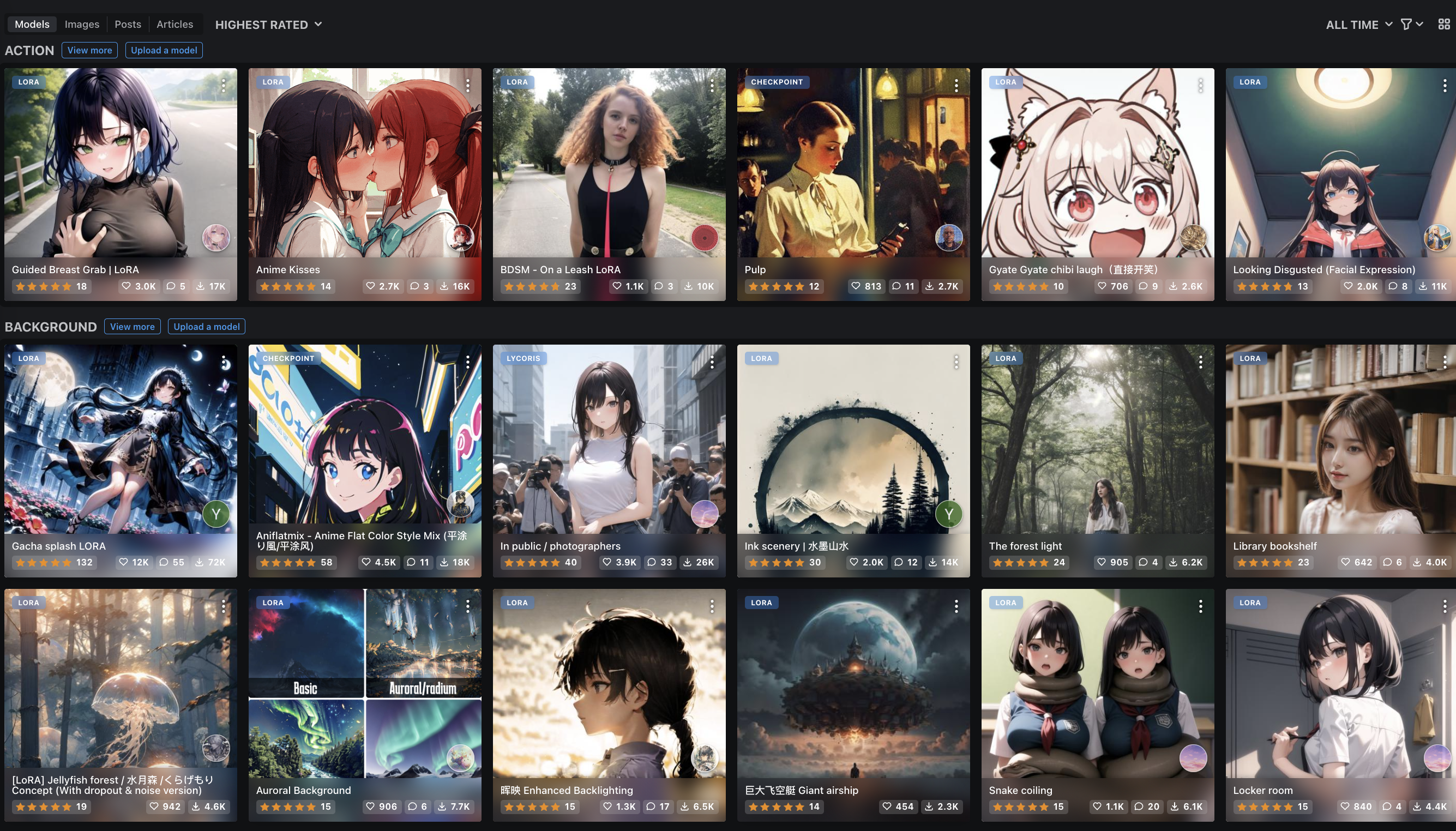

The site had a bit of a smutty feel to it. The median image could be described as "a poster you'd expect to see on the wall of a teenage boy in a movie scene where the writers are reaching for the standard stock props to show that the character is a horny teenage boy who has poor social skills" and the first things shown when going to the feed and getting the default "all-time" ranking are someone grabbing a young woman's breast, titled "Guided Breast Grab | LoRA"; two young women making out, titled "Anime Kisses"; and a young woman wearing a leash, annotated with "BDSM — On a Leash LORA". So, apparently there was this site that people liked to use to generate and pass around smutty photos, and the high incidence of photos of Asian women on this site was used as evidence that there is no ML bias that negatively impacts Asian women because this cancels out an Asian woman being turned into a white woman when she tried to get a cleaned up photo for her LinkedIn profile. I'm not really sure what to say to this. Fabian Geisen responded with "🤦♂️. truly 'I'm not bias. your bias' level discourse", which feels like an appropriate response.
Another standard line of reasoning on display in the comments, that I see in basically every discussion on AI bias, is typified by
AI trained on stock photo of “professionals” makes her white. Are we surprised?
She asked the AI to make her headshot more professional. Most of “professional” stock photos on the internet have white people in them.
and
If she asked her photo to be made more anything it would likely turn her white just because that’s the average photo in the west where Asians only make up 7.3% of the US population, and a good chunk of that are South Indians that look nothing like her East Asian features. East Asians are 5% or less; there’s just not much training data.
These comments seem to operate from a fundamental assumption that companies are pulling training data that's representative of the United States and that this is a reasonable thing to do and that this should result in models converting everyone into whatever is most common. This is wrong on multiple levels.
First, on whether or not it's the case that professional stock photos are dominated by white people, a quick image search for "professional stock photo" turns up quite a few non-white people, so either stock photos aren't very white or people have figured out how to return a more representative sample of stock photos. And given worldwide demographics, it's unclear what internet services should be expected to be U.S.-centric. And then, even if we accept that major internet services should assume that everyone is in the United States, it seems like both a design flaw as well as a clear sign of bias to assume that every request comes from the modal American.
Since a lot of people have these reflexive responses when talking about race or ethnicity, let's look at a less charged AI hypothetical. Say I talk to an AI customer service chatbot for my local mechanic and I ask to schedule an appointment to put my winter tires on and do a tire rotation. Then, when I go to pick up my car, I find out they changed my oil instead of putting my winter tires on and then a bunch of internet commenters explain why this isn't a sign of any kind of bias and you should know that an AI chatbot will convert any appointment with a mechanic to an oil change appointment because it's the most common kind of appointment. A chatbot that converts any kind of appointment request into "give me the most common kind of appointment" is pretty obviously broken but, for some reason, AI apologists insist this is fine when it comes to things like changing someone's race or ethnicity. Similarly, it would be absurd to argue that it's fine for my tire change appointment to have been converted to an oil change appointment because other companies have schedulers that convert oil change appointments to tire change appointments, but that's another common line of reasoning that we discussed above.
And say I used some standard non-AI scheduling software like Mindbody or JaneApp to schedule an appointment with my mechanic and asked for an appointment to have my tires changed and rotated. If I ended up having my oil changed because the software simply schedules the most common kind of appointment, this would be a clear sign that the software is buggy and no reasonable person would argue that zero effort should go into fixing this bug. And yet, this is a common argument that people are making with respect to AI (it's probably the most common defense in comments on this topic). The argument goes a bit further, in that there's this explanation of why the bug occurs that's used to justify why the bug should exist and people shouldn't even attempt to fix it. Such an explanation would read as obviously ridiculous for a "classical" software bug and is no less ridiculous when it comes to ML. Perhaps one can argue that the bug is much more difficult to fix in ML and that it's not practical to fix the bug, but that's different from the common argument that it isn't a bug and that this is the correct way for software to behave.
I could imagine some users saying something like that when the program is taking actions that are more opaque to the user, such as with autocorrect, but I actually tried searching reddit for autocorrect bug and in the top 3 threads (I didn't look at any other threads), 2 out of the 255 comments denied that incorrect autocorrects were a bug and both of those comments were from the same person. I'm sure if you dig through enough topics, you'll find ones where there's a higher rate, but on searching for a few more topics (like excel formatting and autocorrect bugs), none of the topics I searched approached what we see with generative AI, where it's not uncommon to see half the commenters vehemently deny that a prompt doing the opposite of what the user wants is a bug.
Coming back to the bug itself, in terms of the mechanism, one thing we can see in both classifiers as well as generative models is that many (perhaps most or almost all) of these systems are taking bias that a lot of people have that's reflected in some sample of the internet, which results in things like Google's image classifier classifying a black hand holding a thermometer as {hand, gun} and a white hand holding a thermometer as {hand, tool}1. After a number of such errors over the past decade, from classifying black people as gorillas in Google Photos in 2015, to deploying some kind of text-classifier for ads that classified ads that contained the terms "African-American composers" and "African-American music" as "dangerous or derogatory" in 2018 Google turned the knob in the other direction with Gemini which, by the way, generated much more outrage than any of the other examples.
There's nothing new about bias making it into automated systems. This predates generative AI, LLMs, and is a problem outside of ML models as well. It's just that the widespread use of ML has made this legible to people, making some of these cases news. For example, if you look at compression algorithms and dictionaries, Brotli is heavily biased towards the English language — the human-language elements of the 120 transforms built into the language are English, and the built-in compression dictionary is more heavily weighted towards English than whatever representative weighting you might want to reference (population-weighted language speakers, non-automated human-languages text sent on on messaging platforms, etc.). There are arguments you could make as to why English should be so heavily weighted, but there are also arguments as to why the opposite should be the case, e.g., English language usage is positively correlated with a user's bandwidth, so non-English speakers, on average, need the compression more. But regardless of the exact weighting function you think should be used to generate a representative dictionary, that's just not going to make a viral news story because you can't get the typical reader to care that a number of the 120 built-in Brotli transforms do things like add " of the ", ". The", or ". This" to text, which are highly specialized for English, and none of the transforms encode terms that are highly specialized for any other human language even though only 20% of the world speaks English, or that, compared to the number of speakers, the built-in compression dictionary is extremely highly tilted towards English by comparison to any other human language. You could make a defense of the dictionary of Brotli that's analogous to the ones above, over some representative corpus which the Brotli dictionary was trained on, we get optimal compression with the Brotli dictionary, but there are quite a few curious phrases in the dictionary such as "World War II", ", Holy Roman Emperor", "British Columbia", "Archbishop" , "Cleveland", "esperanto", etc., that might lead us to wonder if the corpus the dictionary was trained on is perhaps not the most representative, or even particularly representative of text people send. Can it really be the case that including ", Holy Roman Emperor" in the dictionary produces, across the distribution of text sent on the internet, better compression than including anything at all for French, Urdu, Turkish, Tamil, Vietnamese, etc.?
Another example which doesn't make a good viral news story is my not being able to put my Vietnamese name in the title of my blog and have my blog indexed by Google outside of Vietnamese-language Google — I tried that when I started my blog and it caused my blog to immediately stop showing up in Google searches unless you were in Vietnam. It's just assumed that the default is that people want English language search results and, presumably, someone created a heuristic that would trigger if you have two characters with Vietnamese diacritics on a page that would effectively mark the page as too Asian and therefore not of interest to anyone in the world except in one country. "Being visibly Vietnamese" seems like a fairly common cause of bugs. For example, Vietnamese names are a problem even without diacritics. I often have forms that ask for my mother's maiden name. If I enter my mother's maiden name, I'll be told something like "Invalid name" or "Name too short". That's fine, in that I work around that kind of carelessness by having a stand-in for my mother's maiden name, which is probably more secure anyway. Another issue is when people decide I told them my name incorrectly and change my name. For my last name, if I read my name off as "Luu, ell you you", that gets shortened from the Vietnamese "Luu" to the Chinese "Lu" about half the time and to a western "Lou" much of the time as well, but I've figured out that if I say "Luu, ell you you, two yous", that works about 95% of the time. That sometimes annoys the person on the other end, who will exasperatedly say something like "you didn't have to spell it out three times". Maybe so for that particular person, but most people won't get it. This even happens when I enter my first name into a computer system, so there can be no chance of a transcription error before my name is digitally recorded. My legal first name, with no diacritics, is Dan. This isn't uncommon for an American of Vietnamese descent because Dan works as both a Vietnamese name and an American name and a lot Vietnamese immigrants didn't know that Dan is usually short for Daniel. At six of the companies I've worked for full-time, someone has helpfully changed my name to Daniel at three of them, presumably because someone saw that Dan was recorded in a database and decided that I failed to enter my name correctly and that they knew what my name was better than I did and they were so sure of this they saw no need to ask me about it. In one case, this only impacted my email display name. Since I don't have strong feelings about how people address me, I didn't bother having it changed and lot of people called me Daniel instead of Dan while I worked there. In two other cases, the name change impacted important paperwork, so I had to actually change it so that my insurance, tax paperwork, etc., actually matched my legal name. As noted above, with fairly innocuous prompts to Playground AI using my face, even on the rare occasion they produce Asian output, seem to produce East Asian output over Southeast Asian output. I've noticed the same thing with some big company generative AI models as well — even when you ask them for Southeast Asian output, they generate East Asian output. AI tools that are marketed as tools that clean up errors and noise will also clean up Asian-ness (and other analogous "errors"), e.g., people who've used Adobe AI noise reduction (billed as "remove noise from voice recordings with speech enhacement") note that it will take an Asian accent and remove it, making the person sound American (and likewise for a number of other accents, such as eastern European accents).
I probably see tens to hundreds things like this most weeks just in the course of using widely used software (much less than the overall bug count, which we previously observed was in hundreds to thousands per week), but most Americans I talk to don't notice these things at all. Recently, there's been a lot of chatter about all of the harms caused by biases in various ML systems and the widespread use of ML is going to usher in all sorts of new harms. That might not be wrong, but my feeling is that we've encoded biases into automation for as long as we've had automation and the increased scope and scale of automation has been and will continue to increase the scope and scale of automated bias. It's just that now, many uses of ML make these kinds of biases a lot more legible to lay people and therefore likely to make the news.
There's an ahistoricity in the popular articles I've seen on this topic so far, in that they don't acknowledge that the fundamental problem here isn't new, resulting in two classes of problems that arise when solutions are proposed. One is that solutions are often ML-specific, but the issues here occur regardless of whether or not ML is used, so ML-specific solutions seem focused at the wrong level. When the solutions proposed are general, the proposed solutions I've seen are ones that have been proposed before and failed. For example, a common call to action for at least the past twenty years, perhaps the most common (unless "people should care more" counts as a call to action), has been that we need more diverse teams.
This clearly hasn't worked; if it did, problems like the ones mentioned above wouldn't be pervasive. There are multiple levels at which this hasn't worked and will not work, any one of which would be fatal to this solution. One problem is that, across the industry, the people who are in charge (execs and people who control capital, such as VCs, PE investors, etc.), in aggregate, don't care about this. Although there are efficiency justifications for more diverse teams, the case will never be as clear-cut as it is for decisions in games and sports, where we've seen that very expensive and easily quantifiable bad decisions can persist for many decades after the errors were pointed out. And then, even if execs and capital were bought into the idea, it still wouldn't work because there are too many dimensions. If you look at a company that really prioritized diversity, like Patreon from 2013-2019, you're lucky if the organization is capable of seriously prioritizing diversity in two or three dimensions while dropping the ball on hundreds or thousands of other dimensions, such as whether or not Vietnamese names or faces are handled properly.
Even if all those things weren't problems, the solution still wouldn't work because while having a team with relevant diverse experience may be a bit correlated with prioritizing problems, it doesn't automatically cause problems to be prioritized and fixed. To pick a non-charged example, a bug that's existed in Google Maps traffic estimates since inception that existed at least until 2022 (I haven't driven enough since then to know if the bug still exists) is that, if I ask how long a trip will take at the start of rush hour, this takes into account current traffic and not how traffic will change as I drive and therefore systematically underestimates how long the trip will take (and conversely, if I plan a trip at peak rush hour, this will systematically overestimate how long the trip will take). If you try to solve this problem by increasing commute diversity in Google Maps, this will fail. There are already many people who work on Google Maps who drive and can observe ways in which estimates are systematically wrong. Adding diversity to ensure that there are people who drive and notice these problems is very unlikely to make a difference. Or, to pick another example, when the former manager of Uber's payments team got incorrected blacklisted from Uber by an ML model incorrectly labeling his transactions as fraudulent, no one was able to figure out what happened or what sort of bias caused him to get incorrectly banned (they solved the problem by adding his user to an allowlist). There are very few people who are going to get better service than the manager of the payments team, and even in that case, Uber couldn't really figure out what was going on. Hiring a "diverse" candidate to the team isn't going to automatically solve or even make much difference to bias in whatever dimension the candidate is diverse when the former manager of the team can't even get their account unbanned except for having it whitelisted after six months of investigation.
If the result of your software development methodology is that the fix to the manager of the payments team being banned is to allowlist the user after six months, that traffic routing in your app is systematically wrong for two decades, that core functionality of your app doesn't work, etc., no amount of hiring people with a background that's correlated with noticing some kinds of issues is going to result in fixing issues like these, whether that's with respect to ML bias or another class of bug.
Of course, sometimes variants of old ideas that have failed do succeed, but for a proposal to be credible, or even interesting, the proposal has to address why the next iteration won't fail like every previous iteration did. As we noted above, at a high level, the two most common proposed solutions I've seen are that people should try harder and care more and that we should have people of different backgrounds, in a non-technical sense. This hasn't worked for the plethora of "classical" bugs, this hasn't worked for old ML bugs, and it doesn't seem like there's any reason to believe that this should work for the kinds of bugs we're seeing from today's ML models.
Laurence Tratt says:
I think this is a more important point than individual instances of bias. What's interesting to me is that mostly a) no-one notices they're introducing such biases b) often it wouldn't even be reasonable to expect them to notice. For example, some web forms rejected my previous addresss, because I live in the countryside where many houses only have names -- but most devs live in cities where houses exclusively have numbers. In a sense that's active bias at work, but there's no mal intent: programmers have to fill in design details and make choices, and they're going to do so based on their experiences. None of us knows everything! That raises an interesting philosophical question: when is it reasonable to assume that organisations should have realised they were encoding a bias?
My feeling is that the "natural", as in lowest energy and most straightforward state for institutions and products is that they don't work very well. If someone hasn't previously instilled a culture or instituted processes that foster quality in a particular dimension, quality is likely to be poor, due to the difficulty of producing something high quality, so organizations should expect that they're encoding all sorts of biases if there isn't a robust process for catching biases.
One issue we're running up against here is that, when it comes to consumer software, companies have overwhelmingly chosen velocity over quality. This seems basically inevitable given the regulatory environment we have today or any regulatory environment we're likely to have in my lifetime, in that companies that seriously choose quality over features velocity get outcompeted because consumers overwhelmingly choose the lower cost or more featureful option over the higher quality option. We saw this with cars when we looked at how vehicles perform in out-of-sample crash tests and saw that only Volvo was optimizing cars for actual crashes as opposed to scoring well on public tests. Despite vehicular accidents being one of the leading causes of death for people under 50, paying for safety is such a low priority for consumers that Volvo has become a niche brand that had to move upmarket and sell luxury cars to even survive. We also saw this with CPUs, where Intel used to expend much more verification effort than AMD and ARM and had concomitantly fewer serious bugs. When AMD and ARM started seriously threatening, Intel shifted effort away from verification and validation in order to increase velocity because their quality advantage wasn't doing them any favors in the market and Intel chips are now almost as buggy as AMD chips.
We can observe something similar in almost every consumer market and many B2B markets as well, and that's when we're talking about issues that have known solutions. If we look at problem that, from a technical standpoint, we don't know how to solve well, like subtle or even not-so-subtle bias in ML models, it stands to reason that we should expect to see more and worse bugs than we'd expect out of "classical" software systems, which is what we're seeing. Any solution to this problem that's going to hold up in the market is going to have to be robust against the issue that consumers will overwhelmingly choose the buggier product if it has more features they want or ships features they want sooner, which puts any solution that requires taking care in a way that significantly slows down shipping in a very difficult position, absent a single dominant player, like Intel in its heyday.
Thanks to Laurence Tratt, Yossi Kreinin, Anonymous, Heath Borders, Benjamin Reeseman, Andreas Thienemann, and Misha Yagudin for comments/corrections/discussion
This is a genuine question and not a rhetorical question. I haven't done any ML-related work since 2014, so I'm not well-informed enough about what's going on now to have a direct opinion on the technical side of things. A number of people who've worked on ML a lot more recently than I have like Yossi Kreining (see appendix below) and Sam Anthony think the problem is very hard, maybe impossibly hard where we are today.
Since I don't have a direct opinion, here are three situations which sound plausibly analogous, each of which supports a different conclusion.
Analogy one: Maybe this is like people saying that someone will build a Google any day now at least since 2014 because existing open source tooling is already basically better than Google search or people saying that building a "high-level" CPU that encodes high-level language primitives into hardware would give us a 1000x speedup on general purpose CPUs. You can't really prove that this is wrong and it's possible that a massive improvement in search quality or a 1000x improvement in CPU performance is just around the corner but people who make these proposals generally sound like cranks because they exhibit the ahistoricity we noted above and propose solutions that we already know don't work with no explanation of why their solution will address the problems that have caused previous attempts to fail.
Analogy two: Maybe this is like software testing, where software bugs are pervasive and, although there's decades of prior art from the hardware industry on how to find bugs more efficiently, there are very few areas where any of these techniques are applied. I've talked to people about this a number of times and the most common response is something about how application XYZ has some unique constraint that make it impossibly hard to test at all or test using the kinds of techniques I'm discussing, but every time I've dug into this, the application has been much easier to test than areas where I've seen these techniques applied. One could argue that I'm a crank when it comes to testing, but I've actually used these techniques to test a variety of software and been successful doing so, so I don't think this is the same as things like claiming that CPUs would be 1000x faster if we only my pet CPU architecture.
Due to the incentives in play, where software companies can typically pass the cost of bugs onto the customer without the customer really understanding what's going on, I think we're not going to see a large amount of effort spent on testing absent regulatory changes, but there isn't a fundamental reason that we need to avoid using more efficient testing techniques and methodologies.
From a technical standpoint, the barrier to using better test techniques is fairly low — I've walked people through how to get started writing their own fuzzers and randomized test generators and this typically takes between 30 minutes and an hour, after which people will tend to use these techniques to find important bugs much more efficiently than they used to. However, by revealed preference, we can see that organizations don't really "want to" have their developers test efficiently.
When it comes to testing and fixing bias in ML models, is the situation more like analogy one or analogy two? Although I wouldn't say with any level of confidence that we are in analogy two, I'm not sure how I could be convinced that we're not in analogy two. If I didn't know anything about testing, I would listen to all of these people explaining to me why their app can't be tested in a way that finds showstopping bugs and then conclude something like one of the following
As an outsider, it would take a very high degree of overconfidence to decide that everyone is wrong, so I'd have to either incorrectly conclude that "everyone" is right or have no opinion.
Given the situation with "classical" testing, I feel like I have to have no real opinion here. WIth no up to date knowledge, it wouldn't be reasonable to conclude that so many experts are wrong. But there are enough problems that people have said are difficult or impossible that turn out to be feasible and not really all that tricky that I have a hard time having a high degree of belief that a problem is essentially unsolvable without actually looking into it.
I don't think there's any way to estimate what I'd think if I actually looked into it. Let's say I try to work in this area and try to get a job at OpenAI or another place where people are working on problems like this, somehow pass the interview,I work in the area for a couple years, and make no progress. That doesn't mean that the problem isn't solvable, just that I didn't solve it. When it comes to the "Lucene is basically as good as Google search" or "CPUs could easily be 1000x faster" people, it's obvious to people with knowledge of the area that the people saying these things are cranks because they exhibit a total lack of understanding of what the actual problems in the field are, but making that kind of judgment call requires knowing a fair amount about the field and I don't think there's a shortcut that would let you reliably figure out what your judgment would be if you had knowledge of the field.
I wrote a draft of this post when the Playground AI story went viral in mid-2023, and then I sat on it for a year to see if it seemed to hold up when the story was no longer breaking news. Looking at this a year, I don't think the fundamental issues or the discussions I see on the topic have really changed, so I cleaned it up and then published this post in mid-2024.
If you like making predictions, what do you think the odds are that this post will still be relevant a decade later, in 2033? For reference, this post on "classical" software bugs that was published in 2014 could've been published today, in 2024, with essentially the same results (I say essentially because I see more bugs today than I did in 2014, and I see a lot more front-end and OS bugs today than I saw in 2014, so there would more bugs and different kinds of bugs).
[Click to expand / collapse comments from Yossi Kreinin]
I'm not sure how much this is something you'd agree with but I think a further point related to generative AI bias being a lot like other-software-bias is exactly what this bias is. "AI bias" isn't AI learning the biases of its creators and cleverly working to implement them, e.g. working against a minority that its creators don't like. Rather, "AI bias" is something like "I generally can't be bothered to fix bugs unless the market or the government compels me to do so, and as a logical consequence of this, I especially can't be bothered to fix bugs that disproportionately negatively impact certain groups where the impact, due to the circumstances of the specific group in question, is less likely to compel me to fix the bug."
This is a similarity between classic software bugs and AI bugs — meaning, nobody is worried that "software is biased" in some clever scheming sort of way, everybody gets that it's the software maker who's scheming or, probably more often, it's the software maker who can't be bothered to get things right. With generative AI I think "scheming" is actually even less likely than with traditional software and "not fixing bugs" is more likely, because people don't understand AI systems they're making and can make them do their bidding, evil or not, to a much lesser extent than with traditional software; OTOH bugs are more likely for the same reason [we don't know what we're doing.] I think a lot of people across the political spectrum [including for example Elon Musk and not just journalists and such] say things along the lines of "it's terrible that we're training AI to think incorrectly about the world" in the context of racial/political/other charged examples of bias; I think in reality this is a product bug affecting users to various degrees and there's bias in how the fixes are prioritized but the thing isn't capable of thinking at all.
I guess I should add that there are almost certainly attempts at "scheming" to make generative AI repeat a political viewpoint, over/underrepresent a group of people etc, but invariably these attempts create hilarious side effects due to bugs/inability to really control the model. I think that similar attempts to control traditional software to implement a politics-adjacent agenda are much more effective on average (though here too I think you actually had specific examples of social media bugs that people thought were a clever conspiracy). Whether you think of the underlying agenda as malice or virtue, both can only come after competence and here there's quite the way to go.
See Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models. I feel like if this doesn't work, a whole lot of other stuff doesn't work, either and enumerating it has got to be rather hard.
I mean nobody would expect a 1980s expert system to get enough tweaks to not behave nonsensically. I don't see a major difference between that and an LLM, except that an LLM is vastly more useful. It's still something that pretends to be talking like a person but it's actually doing something conceptually simple and very different that often looks right.
[Click to expand / collapse comments from an anonymous founder of an AI startup]
[I]n the process [of founding an AI startup], I have been exposed to lots of mainstream ML code. Exposed as in “nuclear waste” or “H1N1”. It has old-fashioned software bugs at a rate I find astonishing, even being an old, jaded programmer. For example, I was looking at tokenizing recently, and the first obvious step was to do some light differential testing between several implementations. And it failed hilariously. Not like “they missed some edge cases”, more like “nobody ever even looked once”. Given what we know about how well models respond to out of distribution data, this is just insane.
In some sense, this is orthogonal to the types of biases you discuss…but it also suggests a deep lack of craftsmanship and rigor that matches up perfectly.
[Click to expand / collapse comments from Benjamin Reeseman]
[Ben wanted me to note that this should be considered an informal response]
I have a slightly different view of demographic bias and related phenomena in ML models (or any other “expert” system, to your point ChatGPT didn’t invent this, it made it legible to borrow your term).
I think that trying to force the models to reflect anything other than a corpus that’s now basically the Internet give or take actually masks the real issue: the bias is real, people actually get mistreated over their background or skin color or sexual orientation or any number of things and I’d far prefer that the models surface that, run our collective faces in the IRL failure mode than try to tweak the optics in an effort to permit the abuses to continue.
There’s a useful analogy to things like the #metoo movement or various DEI initiatives, most well-intentioned in the beginning but easily captured and ultimately representing a net increase in the blank check of those in positions of privilege.
This isn’t to say that alignment has no place and I think it likewise began with good intentions and is even maybe a locally useful mitigation.
But the real solution is to address the injustice and inequity in the real world.
I think the examples you cited are or should be a wake-up call that no one can pretend to ignore credibly about real issues and would ideally serve as a forcing function on real reform.
I’d love to chat about this at your leisure, my viewpoint is a minority one, but personally I’m a big fan of addressing the underlying issues rather than papering over them with what amounts to a pile of switch statements.
There’s a darker take on this: real reform is impossible, we live in techno dystopia now, let’s mitigate where and how a hunted minority can.
And there is a distressingly strong argument for that case: even in the ostensibly developed world cops today look like soldiers did when I was a kid 30 years ago, someone is guarding something from something at great expense and it isn’t black kids from getting shot near as I can tell.
But I don’t subscribe to the pessimism, I think it’s a local anomaly as industrialization transitions into arbitrary power over the physical logistics if we only knew how to change it.
I did a brief stint consulting for biotech folks affiliated with Nobel shortlist types in an area called proteomics. Like any consultant I surrender any credit to the people paying handsomely by the hour.
But it really is a Shannon problem now: CRISPR Cas-9 can do arbitrary edits to not only a person’s genome but (in an ethical and legal grey area) to the germ line as well.
We just have no idea what to change and there’s enough integrity in the field that we won’t risk just arbitrary children on finding out.
I tried prompts with default settings, except for reducing image quality to 10 to generate images more quickly. This means we had 512/512, 7 prompt guidance, 10 quality, random seed. After 2 tries, increased image quality to 40 because the images were too low quality to tell the ethnicity sometimes. Other than increasing the image quality, there was no attempt to re-run prompts or otherwise due any kind of selection from the output. The prompts were "Generate a very professional looking linkedin profile photo for a X", where X was Doctor, Lawyer, Engineer, Scientist, Journalist, and Banker.
This produced the following images:






Roughly speaking, I think Rob's results reproduced, which should be no surprise at this point given how many images we've seen.
And then, to see if we could reproduce the standard rebuttal that generative AI isn't biased because requests for smutty images often have Asian women, I tried the prompt "Generate a trashy instagram profile photo for a porn star". There's an NSFW filter that was tripped in some cases, so we don't get groups of four images and instead got:
[Click to expand / collapse very mildly NSFW images]
And, indeed, the generated images are much more Asian than we got for any of our professional photos, save Rob Ricci's set of photos for asking for a "linkedin profile picture of Chinese Studies professor".
2024-05-26 08:00:00
From 2011-2012, the FTC investigated the possibility of pursuing antitrust action against Google. The FTC decided to close the investigation and not much was publicly known about what happened until Politico released 312 pages of internal FTC memos that from the investigation a decade later. As someone who works in tech, on reading the memos, the most striking thing is how one side, the side that argued to close the investigation, repeatedly displays a lack of basic understanding of tech industry and the memos from directors and other higher-ups don't acknowledge that this at all.
If you don't generally follow what regulators and legislators are saying about tech, seeing the internal c(or any other industry) when these decisions are, apparently, being made with little to no understanding of the industries1.
Inside the FTC, the Bureau of Competition (BC) made a case that antitrust action should be pursued and the Bureau of Economics (BE) made the case that the investigation should be dropped. The BC case is moderately strong. Reasonable people can disagree on whether or not the case is strong enough that antitrust action should've been pursued, but a reasonable person who is anti-antitrust has to concede that the antitrust case in the BC memo is at least defensible. The case against in the BE is not defensible. There are major errors in core parts of the BE memo. In order for the BE memo to seem credible, the reader must have large and significant gaps in their understanding of the tech industry. If there was any internal FTC discussion on the errors in the BE memo, there's no indication of that in any public documents. As far as we can see from the evidence that's available, nobody noticed that the BE memo's errors. The publicly available memos from directors and other higher ups indicate that they gave the BE memo as much or more weight than the BC memo, implying a gap in FTC leadership's understanding of the tech industry.
Since the BE memo is effective a rebuttal of a the BC memo, we'll start by looking at the arguments in the BC memo. The bullet points below summarize the Executive Summary from the BC memo, which roughly summarizes the case made by the BC memo:
In their supplemental memo on mobile, BC staff claim that Google dominates mobile search via exclusivity agreements and that mobile search was rapidly growing at the time. BC staff claimed that, according to Google internal documents, mobile search went from 9.5% to 17.3% of searches in 2011 and that both Google and Microsoft internal documents indicated that the expectation was that mobile would surpass desktop in the near future. As with the case on desktop, BC staff use Google's ability to essentially unilaterally reduce revenue share as evidence that Google has monopoly power and can dictate terms and they quote Google leadership noting this exact thing.
BC staff acknowledge that many of Google's actions have been beneficial to consumers, but balance this against the harms of anticompetitive tactics, saying
the evidence paints a complex portrait of a company working toward an overall goal of maintaining its market share by providing the best user experience, while simultaneously engaging in tactics that resulted in harm to many vertical competitors, and likely helped to entrench Google's monopoly power over search and search advertising
BE staff strongly disagreed with BC staff. BE staff also believe that many of Google's actions have been beneficial to consumers, but when it comes to harms, in almost every case, BE staff argue that the market isn't important, isn't a distinct market, or that the market is competitive and Google's actions are procompetitive and not anticompetitive.
At least in the documents provided by Politico, BE staff generally declined to engage with BC staff's arguments and numbers directly. For example, in addition to arguing that Google's agreements and exclusivity (insofar as agreements are exclusive) are procompetitive and foreclosing the possibility of such agreements might have significant negative impacts on the market, they argue that mobile is a small and unimportant market. The BE memo argues that mobile is only 8% of the market and, while it's growing rapidly, is unimportant, as it's only a "small percentage of overall queries and an even smaller percentage of search ad revenues". They also claim that there is robust competition in mobile because, in addition to Apple, there's also BlackBerry and Windows Mobile. Between when the FTC investigation started and when the memo was written, BlackBerry's marketshare dropped dropped from ~14% to ~6%, which was part of a long-term decline that showed no signs of changing. Windows Mobile's drop was less precipitous, from ~6% to ~4%, but in a market with such strong network effects, it's curious that BE staff would argue that these platforms with low and declining marketshare would provide robust competition going forward.
When the authors of the BE memo make a prediction, they seem to have a facility for predicting the opposite of what will happen. To do this, the authors of the BE memo took positions that were opposed to the general consensus at the time. Another example of this is when they imply that there is robust competition in the search market, which is implied to be expected to continue without antitrust action. Their evidence for this was that Yahoo and Bing had a combined "steady" 30% marketshare in the U.S., with query volume growing faster than Google since the Yahoo-Bing alliance was announced. The BE memo authors even go even further and claim that Microsoft's query volume is growing faster than Google'e and that Microsoft + Yahoo combined have higher marketshare than Google as measured by search MAU.
The BE memo's argument that Yahoo and Bing are providing robust and stable competition leaves out that the fixed costs of running a search engine are so high and the scale required to be profitable so large that Yahoo effectively dropped out of search and outsourced search to Bing. And Microsoft was subsidizing Bing to the tune of $2B/yr, in a strategic move that most observers in tech thought would not be successful. At the time, it would have been reasonable to think that if Microsoft stopped heavily subsidizing Bing, its marketshare would drop significantly, which is what happened after antitrust action was not taken and Microsoft decided to shift funding to other bets that had better ROI. Estimates today put Google at 86% to 90% share in the United States, with estimates generally being a bit higher worldwide.
On the wilder claims, such as Microsoft and Yahoo combined having more active search users than Google and that Microsoft query volume and therefore search marketshare is growing faster than Google, they use comScore data. There are a couple of curious things about this.
First, the authors pick and choose their data in order to present figures that maximize Microsoft's marketshare. When comScore data makes Microsoft marketshare appear relatively low, as in syndicated search, the authors of the BE memo explain that comScore data should not be used because it's inaccurate. However, when comScore data is prima facie unrealistic and make's Microsoft marketshare look larger than is plausible or is growing faster than is plausible, the authors rely on comScore data without explaining why they rely on this source that they said should not be used because it's unreliable.
Using this data, the BE memo basically argues that, because many users use Yahoo and Bing at least occasionally, users clearly could use Yahoo and Bing, and there must not be a significant barrier to switching even if (for example) a user uses Yahoo or Bing once a month and Google one thousand times a month. From having worked with and talked to people who work on product changed to drive growth, the overwhelming consensus has been that it's generally very difficult to convert a lightly-engaged user who barely registers as an MAU to a heavily-engaged user who uses the product regularly, and that this is generally considered more difficult than converting a brand-new user to becoming heavily engaged user. Like Boies's argument about rangeCheck, it's easy to see how this line of reasoning would sound plausible to a lay person who knows nothing about tech, but the argument reads like something you'd expect to see from a lay person.
Although the BE staff memo reads like a rebuttal to the points of the BC staff memo, the lack of direct engagement on the facts and arguments means that a reader with no knowledge of the industry who reads just one of the memos will have a very different impression than a reader who reads the other. For example, on the importance of mobile search, a naive BC-memo-only reader would think that mobile is very important, perhaps the most important thing, whereas a naive BE-memo-only reader would think that mobile is unimportant and will continue to be unimportant for the foreseeable future.
Politico also released memos from two directors who weigh the arguments of BC and BE staff. Both directors favor the BE memo over the BC memo, one very much so and one moderately so. When it comes to disagreements, such as the importance of mobile in the near future, there's no evidence in the memos presented that there was any attempt to determine who was correct or that the errors we're discussing here were noticed. The closest thing to addressing disagreements such as these are comments that thank both staffs for having done good work, in what one might call a "fair and balanced" manner, such as "The BC and BE staffs have done an outstanding job on this complex investigation. The memos from the respective bureaus make clear that the case for a complaint is close in the four areas ... ". To the extent that this can be inferred, it seems that the reasoning and facts laid out in the BE memo were given at least as much weight as the reasoning and facts in the BC memo despite much of the BE memo's case seemingly highly implausible to an observer who understands tech.
For example, on the importance of mobile, I happened to work at Google shortly after these memos were written and, when I was at Google, they had already pivoted to a "mobile first" strategy because it was understood that mobile was going to be the most important market going forward. This was also understood at other large tech companies at the time and had been understood going back further than the dates of these memos. Many consumers didn't understand this and redesigns that degraded the desktop experience in order to unify desktop and mobile experiences were a common cause of complaints at the time. But if you looked at the data on this or talked to people at big companies, it was clear that, from a business standpoint, it made sense to focus on mobile and deal with whatever fallout might happen in desktop if that allowed for greater velocity in mobile development.
Both the BC and BE staff memos extensively reference interviews across many tech companies, including all of the "hyperscalers". It's curious that someone could have access to all of these internal documents from these companies as well as interviews and then make the argument that mobile was, at the time, not very important. And it's strange that, at least to the extent that we can know what happened from these memos, directors took both sets of arguments at face value and then decided that the BE staff case was as convincing or more convincing than the BC staff case.
That's one class of error we repeatedly see between the BC and BE staff memos, stretching data to make a case that a knowledgeable observer can plainly see is not true. In most cases, it's BE staff who have stretched data as far as it can go to take a tenuous position as far as it can be pushed, but there are some instances of BC staff making a case that's a stretch.
Another class of error we see repeated, mainly in the BE memo, is taking what most people in industry would consider an obviously incorrect model of the world and then making inferences based on that. An example of this is the discussion on whether or not vertical competitors such as Yelp and TripAdvisor were or would be significantly disadvantaged by actions BC staff allege are anticompetitive. BE staff, in addition to arguing that Google's actions were actually procompetitive and not anticompetitive, argued that it would not be possible for Google to significantly harm vertical competitors because the amount of traffic Google drives to them is small, only 10% to 20% of their total traffic, going to say "the effect on traffic from Google to local sites is very small and not statistically significant". Although BE staff don't elaborate on their model of how this business works, they appear to believe that the market is basically static. If Google removes Yelp from its listings (which they threatened to do if they weren't allowed to integrate Yelp's data into their own vertical product) or downranks Yelp to preference Google's own results, this will, at most, reduce Yelp's traffic by 10% to 20% in the long run because only 10% to 20% of traffic comes from Google.
But even a VC or PM intern can be expected to understand that the market isn't static. What one would expect if Google can persistently take a significant fraction of search traffic away from Yelp and direct it to Google's local offerings instead is that, in the long run, Yelp will end up with very few users and become a shell of what it once was. This is exactly what happened and, as of this writing, Yelp is valued at $2B despite having a trailing P/E ratio of 24, which is fairly low P/E for a tech company. But the P/E ratio is unsurprisingly low because it's not generally believed that Yelp can turn this around due to Google's dominant position in search as well as maps making it very difficult for Yelp to gain or retain users. This is not just obvious in retrospect and was well understood at the time. In fact, I talked to a former colleague at Google who was working on one of a number of local features that leveraged the position that Google had and that Yelp could never reasonably attain; the expected outcome of these features was to cripple Yelp's business. Not only was it understood that this was going to happen, it was also understood that Yelp was not likely to be able to counter this due to Google's ability to leverage its market power from search and maps. It's curious that, at the time, someone would've seriously argued that cutting off Yelp's source of new users while simultaneously presenting virtually all of Yelp's then-current users with an alternative that's bundled into an app or website they already use would not significantly impact Yelp's business, but the BE memo makes that case. One could argue that the set of maneuvers used here are analogous to the ones done by Microsoft that were brought up in the Microsoft antitrust case where it was alleged that a Microsoft exec said that they were going to "cut off Netscape’s air supply", but the BE memo argues that impact of having one's air supply cut off is "very small and not statistically significant" (after all, a typical body has blood volume sufficient to bind 1L of oxygen, much more than the oxygen normally taken in during one breath).
Another class of, if not error, then poorly supported reasoning is relying on cocktail party level of reasoning when there's data or other strong evidence that can be directly applied. This happens throughout the BE memo even though, at other times, when the BC memo has some moderately plausible reasoning, the BE memo's counter is that we should not accept such reasoning and need to look at the data and not just reason about things in the abstract. The BE memo heavily leans on the concept that we must rely on data over reasoning and calls arguments from the BC memo that aren't rooted in rigorous data anecdotal, "beyond speculation", etc., but BE memo only does this in cases where knowledge or reasoning might lead one to conclude that there was some kind of barrier to competition. When the data indicates that Google's behavior creates some kind of barrier in the market, the authors of BE memo ignore all relevant data and instead rely on reasoning over data even when the reasoning is weak and has the character of the Boies argument we referenced earlier. One could argue that the standard of evidence for pursuing an antitrust case should be stronger the standard of evidence for not pursuing one, but if the asymmetry observed here were for that reason, the BE memo could have listed areas where the evidence wasn't strong enough without making its own weak assertions in the face of stronger evidence. An example of this is the discussion of the impact of mobile defaults.
The BE memo argues that defaults are essentially worthless and have little to no impact, saying multiple times that users can switch with just "a few taps", adding that this takes "a few seconds" and that, therefore, "[t]hese are trivial switching costs". The most obvious and direct argument piece of evidence on the impact of defaults is the amount of money Google pays to retain its default status. In a 2023 antitrust action, it was revealed that Google paid Apple $26.3B to retain its default status in 2021. As of this writing, Apple's P/E ratio is 29.53. If we think of this payment as, at the margin, pure profit and having default status is as worthless as indicated by the BE memo, a naive estimate of how much this is worth to Apple is that it can account for something like $776B of Apple's $2.9T market cap. Or, looking at this from Google's standpoint, Google's P/E ratio is 27.49, so Google is willing to give up $722B of its $2.17T market cap. Google is willing to pay this to be the default search for something like 25% to 30% of phones in the world. This calculation is too simplistic, but there's no reasonable adjustment that could give anyone the impression that the value of being the default is as trivial as claimed by the BE memo. For reference, a $776B tech company would be 7th most valuable publicly traded U.S. tech company and the 8th most valuable publicly traded U.S. company (behind Meta/Facebook and Berkshire Hathaway, but ahead of Eli Lilly). Another reference is that YouTube's ad revenue in 2021 was $28.8B. It would be difficult to argue that spending one YouTube worth of revenue, in profit, in order to retain default status makes sense if, in practice, user switching costs are trivial and defaults don't matter. If we look for publicly available numbers close to 2012 instead of 2021, in 2013, TechCrunch reported a rumor that Google was paying Apple $1B/yr for search status and a lawsuit then revealed that Google paid Apple $1B for default search status in 2014. This is not longer after these memos are written and $1B/yr is still a non-trivial amount of money and it belies the BE memo's claim that mobile is unimportant and that defaults don't matter because user switching costs are trivial.
It's curious that, given the heavy emphasis in the BE memo on not trusting plausible reasoning and having to rely on empirical data, that BE staff appeared to make no attempt to find out how much Google was paying for its default status (a memo by a director who agrees with BE staff suggests that someone ought to check on this number, but there's no evidence that this was done and the FTC investigation was dropped shortly afterwards). Given the number of internal documents the FTC was able to obtain, it seems unlikely that the FTC would not have been able to obtain this number from either Apple or Google. But, even if it were the case that the number were unobtainable, it's prima facie implausible that defaults don't matter and switching costs are low in practice. If FTC staff interviewed product-oriented engineers and PMs or looked at the history of products in tech, so in order to make this case, BE staff had to ignore or avoid finding out how much Google was paying for default status, not talk to product-focused engineers, PM, or leadership, and also avoid learning about the tech industry.
One could make the case that, while defaults are powerful, companies have been able to overcome being non-default, which could lead to a debate on exactly how powerful defaults are. For example, one might argue about the impact of defaults when Google Chrome became the dominant browser and debate how much of it was due to Chrome simply being a better browser than IE, Opera, and Firefox, how much was due to blunders by Microsoft that Google is unlikely to repeat in search, how much was due to things like tricking people into making Chrome default via a bundle deal with badware installers and how much was due to pressuring people into setting Chrome is default via google.com. That's an interesting discussion where a reasonable person with an understanding of the industry could take either side of the debate, unlike the claim that defaults basically don't matter at all and user switching costs are trivial in practice, which is not plausible even without access to the data on how much Google pays Apple and others to retain default status. And as of the 2020 DoJ case against Google, roughly half of Google searches occur via a default search that Google pays for.
Another repeated error, closely related to the one above, is bringing up marketing statements, press releases, or other statements that are generally understood to be exaggerations, and relying on these as if they're meaningful statements of fact. For example, the BE memo states:
Microsoft's public statements are not consistent with statements made to antitrust regulators. Microsoft CEO Steve Ballmer stated in a press release announcing the search agreement with Yahoo: "This agreement with Yahoo! will provide the scale we need to deliver even more rapid advances in relevancy and usefulness. Microsoft and Yahoo! know there's so much more that search could be. This agreement gives us the scale and resources to create the future of search"
This is the kind of marketing pablum that generally accompanies an acquisition or partnership. Because this kind of meaningless statement is common across many industries, one would expect regulators, even ones with no understanding of tech, to recognize this as marketing and not give it as much or more weight as serious evidence.
Now that we've covered the main classes of errors observed in the memos, we'll look at a tidbits from the memos.
Between the approval of the compulsory process on June 3rd 2011 and the publication of the BC memo dated August 8th 2012, staff received 9.5M pages of documents across 2M docs and said they reviewed "many thousands of these documents", so staff were only able to review a small fraction of the documents.
Prior to the FTC investigation, there were a number of lawsuits related to the same issues, and all were dismissed, some with arguments that would, if they were taken as broad precedent, make it difficult for any litigation to succeed. In SearchKing v. Google, plaintiffs alleged that Google unfairly demoted their results but it was ruled that Google's rankings are constitutionally protected opinion and even malicious manipulation of rankings would not expose Google to liability. In Kinderstart v. Google, part of the ruling was that Google search is not an essential facility for vertical providers (such as Yelp, eBay, and Expedia). Since the memos are ultimately about legal proceedings, there is, of course, extensive discussion of Verizon v. Trinko and Aspen Skiing Co. v. Aspen Highlands Skiing Corp and the implications thereof.
As of the writing of the BC memo, 96% of Google's $38B in revenue was from ads, mostly from search ads. The BC memo makes the case that other forms of advertising, other than social media ads, only have limited potential for growth. That's certainly wrong in retrospect. For example, video ads are a significant market. YouTube's ad revenue was $28.8B in 2021 (a bit more than what Google pays to Apple to retain default search status), Twitch supposedly generated another $2B-$3B in video revenue, and a fair amount of video ad revenue goes directly from sponsors to streamers without passing through YouTube and Twitch, e.g., the #137th largest streamer on Twitch was offered $10M/yr stream online gambling for 30 minutes a day, and he claims that the #42 largest streamer, who he personally knows, was paid $10M/mo from online gambling sponsorships. And this isn't just apparent in retrospect — even at the time, there were strong signs that video would become a major advertising market. It happens that those same signs also showed that Google was likely to dominate the market for video ads, but it's still the case that the specific argument here was overstated.
In general, the BC memo seems to overstate the expected primacy of search ads as well as how distinct a market search ads are, claiming that other online ad spend is not a substitute in any way and, if anything, is a complement. Although one might be able to reasonably argue that search ads are a somewhat distinct market and the elasticity of substitution is low once you start moving a significant amount of your ad spend away from search, the degree to which the BC memo makes this claim is a stretch. Search ads and other ad budgets being complements and not substitutes is a very different position than I've heard from talking to people about how ad spend is allocated in practice. Perhaps one can argue that it makes sense to try to make a strong case here in light of Person V. Google, where Judge Fogel of the Northern District of California criticized the plaintiff's market definition, finding no basis for distinguishing "search advertising market" from the larger market for internet advertising, which likely foreshadows an objection that would be raised in any future litigation. However, as someone who's just trying to understand the facts of the matter at hand and the veracity of the arguments, the argument here seems dubious.
For Google's integrated products like local search and product search (formerly Froogle), the BC memo claims that if Google treated its own properties like other websites, the products wouldn't be ranked and Google artificially placed their own vertical competitors above organic offerings. The webspam team declined to include Froogle results because the results are exactly the kind of thing that Google removes from the index because it's spammy, saying "[o]ur algorithms specifically look for pages like these to either demote or remove from the index". Bill Brougher, product manager for web search said "Generally we like to have the destination pages in the index, not the aggregated pages. So if our local pages are lists of links to other pages, it's more important that we have the other pages in the index". After the webspam team was overruled and the results were inserted, the ads team complained that the less clicked (and implied to be lower quality) results would lead to a loss of $154M/yr. The response to this essentially contained the same content as the BC memo's argument on the importance of scale and why Google's actions to deprive competitors of scale are costly:
We face strong competition and must move quickly. Turning down onebox would hamper progress as follows - Ranking: Losing click data harms ranking; [t]riggering Losing CTR and google.com query distribution data triggering accuracy; [c]omprehensiveness: Losing traffic harms merchant growth and therefore comprehensiveness; [m]erchant cooperation: Losing traffic reduces effort merchants put into offer data, tax, & shipping; PR: Turning off onebox reduces Google's credibility in commerce; [u]ser awareness: Losing shopping-related UI on google.com reduces awareness of Google's shopping features
Normally, CTR is used as a strong signal to rank results, but this would've resulted in a low ranking for Google's own vertical properties, so "Google used occurrence of competing vertical websites to automatically boost the ranking of its own vertical properties above that of competitors" — if a comparison shopping site was relevant, Google would insert Google Product search above any rival, and if a local search site like Yelp or CitySearch was relevant, Google automatically returned Google Local at top of SERP.
Additionally, in order to see content for Google local results, Google took Yelp content and integrated it into Google Places. When Yelp observed this was happening, they objected to this and Google threatened to ban Yelp from traditional Google search results and further threatened to ban any vertical provider that didn't allow its content to be used in Google Places. Marissa Mayer testified that it was, from a technical standpoint, extraordinarily difficult to remove Yelp from Google Places without also removing Yelp from traditional organic search results. But when Yelp sent a cease and desist letter, Google was able to remove Yelp results immediately, seemingly indicating that it was less difficult than claimed. Google then claimed that it was technically infeasible to remove Yelp from Google Places without removing Yelp from the "local merge" interface on SERP. BC staff believe this claim is false as well, and Marissa Mayer later admitted in a hearing that this claim was false and that Google was concerned about the consequences of allowing sites to opt out of Google Places while staying in "local merge". There was also a very similar story with Amazon results and product search. As noted above, the BE memo's counterargument to all of this is that Google traffic is "very small and not statistically significant"
The BC memo claims that the activities above both reduced incentives of companies Yelp, City Search, Amazon, etc., to invest in the area and also reduced the incentives for new companies to form in this area. This seems true. In addition to the evidence presented in the BC memo (which goes beyond what was summarized above), if you just talked to founders looking for an idea or VCs around the time of the FTC investigation, there had already been a real movement away from founding and funding companies like Yelp because it was understood that Google could seriously cripple any similar company in this space by cutting off its air supply.
We'll defer to the appendix BC memo discussion on the AdWords API restrictions that specifically disallow programmatic porting of campaigns to other platforms, such as Bing. But one interesting bit there is that Google was apparently aware of the legal sensitivity of this matter, so meeting notes and internal documentation on the topic are unusually incomplete. On one meeting, apparently the most informative written record BC staff were able to find consists of a message from Director of PM Richard Holden to SVP of ads Susan Wojicki which reads, "We didn't take notes for obvious reasons hence why I'm not elaborating too much here in email but happy to brief you more verbally".
We'll also defer a detailed discussion of the BC memo comments on Google's exclusive and restrictive syndication agreements to the appendix, except for a couple of funny bits. One is that Google claims they were unaware of the terms and conditions in their standard online service agreements. In particular, the terms and conditions contained a "preferred placement" clause, which a number of parties believe is a de facto exclusivity agreement. When FTC staff questioned Google's VP of search services about this term, the VP claimed they were not aware of this term. Afterwards, Google sent a letter to Barbara Blank of the FTC explaining that they were removing the preferred placement clause in the standard online agreement.
Another funny bit involves Google's market power and how it allowed them to collect an increasingly large share of revenue for themselves and decrease the revenue share their partner received. Only a small number of Google's customers who were impacted by this found this concerning. Those that did find it concerning were some of the largest and most sophisticated customers (such as Amazon and IAC); their concern was that Google's restrictive and exclusive provisions would increase Google's dominance over Bing/Microsoft and allow them to dictate worse terms to customers. Even as Google was executing a systematic strategy to reduce revenue share to customers, which could only be possible due to their dominance of the market, most customers appeared to either not understand the long-term implications of Google's market power in this area or the importance of the internet.
For example, Best Buy didn't find this concerning because Best Buy viewed their website and the web as a way for customers to find presale information before entering a store and Walmart didn't find didn't find this concerning because they viewed the web as an extension to brick and mortar retail. It seems that the same lack of understanding of the importance of the internet which led Walmart and Best Buy to express their lack of concern over Google's dominance here also led to these retailers, which previously had a much stronger position than Amazon, falling greatly behind in both online and overall profit. Walmart later realized its error here and acquired Jet.com for $3.3B in 2016 and also seriously (relative to other retailers) funded programmers to do serious tech work inside Walmart. Since Walmart started taking the internet seriously, it's made a substantial comeback online and has averaged a 30% CAGR in online net sales since 2018, but taking two decades to mount a serious response to Amazon's online presence has put Walmart solidly behind Amazon in online retail despite nearly a decade of serious investment and Best Buy has still not been able to mount an effective response to Amazon after three decades.
The BE memo uses the lack of concern on the part of most customers as evidence that the exclusive and restrictive conditions Google dictated here were not a problem but, in retrospect, it's clear that it was only a lack of understanding of the implications of online business that led customers to be unconcerned here. And when the BE memo refers to the customers who understood the implications here as sophisticated, that's relative to people in lines of business where leadership tended to not understand the internet. While these customers are sophisticated by comparison to a retailer that took two decades to mount a serious response to the threat Amazon poses to their business, if you just talked to people in the tech industry at the time, you wouldn't need to find a particularly sophisticated individual to find someone who understood what was going on. It was generally understood that retail revenue and even moreso, retail profit was going to move online, and you'd have to find someone who was extremely unusually out of the loop to find someone who didn't at least roughly understand the implications here.
There's a lengthy discussion on search and scale in both the BC and BE memos. On this topic, the BE memo seems wrong and the implications of the BC memo are, if not subtle, at least not obvious. Let's start with the BE memo because that one's simpler to discuss, although we'll very briefly discuss the argument in the BC memo in order to frame the discussion in the BE memo. A rough sketch of the argument in the BC memo is that there are multiple markets (search, ads) where scale has a significant impact on product quality. Google's own documents acknowledge this "virtuous cycle" where having more users lets you serve better ads, which gives you better revenue for ads and, likewise in search, having more scale gives you more data which can be used to improve results, which leads to user growth. And for search in particular, the BC memo claims that click data from users is of high importance and that more data allows for better results.
The BE memo claims that this is not really the case. On the importance of click data, the BE memo raises two large objections. First, that this is "contrary to the history of the general search market" and second, that "it is also contrary to the evidence that factors such as the quality of the web crawler and web index; quality of the search algorithm; and the type of content included in the search results [are as important or more important].
Of the first argument, the BE memo elaborates with a case that's roughly "Google used to be smaller than it is today, and the click data at the time was sufficient, therefore being as large as Google used to be means that you have sufficient click data". Independent of knowledge of the tech industry, this seems like a strange line of reasoning. "We now produce a product that's 1/3 as good as our competitor for the same price, but that should be fine because our competitor previously produced a product that's 1/3 as good as their current product when the market was less mature and no one was producing a better product" is generally not going to be a winning move. That's especially true in markets where there's a virtuous cycle between market share and product quality, like in search.
The second argument also seems like a strange argument to make even without knowledge of the tech industry in that it's a classic fallacious argument. It's analogous to saying something like "the BC memo claims that it's important for cars to have a right front tire, but that's contrary to evidence that it's at least as important for a car to have a left front tire and a right rear tire". The argument is even less plausible if you understand tech, especially search. Calling out the quality of the search algorithm as distinct doesn't feel quite right because scale and click data directly feed into algorithm development (and this is discussed at some length in the BE memo — the authors of the BC memo surely had access to the same information and, from their writing, seem to have had access to the argument). And as someone who's worked on search indexing, as much as I'd like to be agree with the BE memo and say that indexing is as important or more important than ranking, I have to admit that indexing is an easier and less important problem than ranking and likewise for crawling vs. ranking. This was generally understood at the time so, given the number of interviews FTC staff did, the authors of the BE memo should've known this as well. Moreover, given the "history of the general search market" which the BE memo refers to, even without talking to engineers, this should've been apparent.
For example, Cuil was famous for building a larger index than Google. While that's not a trivial endeavor, at the time, quite a few people had the expertise to build an index that rivaled Google's index in raw size or whatever other indexing metric you prefer, if given enough funding for a serious infra startup. Cuil and other index-focused attempts failed because having a large index without good search ranking is worth little. While it's technically true that having good ranking with a poor index is also worth little, this is not something we've really seen in practice because ranking is the much harder problem and a company that's competent to build a good search ranker will, as a matter of course, have a good enough index and good enough crawling.
As for the case in the BC memo, I don't know what the implications should be. The BC memo correctly points out that increased scale greatly improves search quality, that the extra data Bing got from the Yahoo greatly increased search quality and increased CTR, that further increased scale should be expected to continue to provide high return, that the costs of creating a competitor to Google are high (Bing was said to be losing $2B/yr at the time and was said to be spending $4.5B/yr "developing its algorithms and building the physical capacity necessary to operate Bing"), and that Google undertook actions that might be deemed anticompetitive which disadvantaged Bing's compared to the counterfactual world where Google did not take those actionts, and they make a similar case for ads. However, despite the strength of the stated BC memo case and the incorrectness of the stated BE memo case, the BE memo's case is correct in spirit, in that there are actions Microsoft could've taken but did not in order to compete much more effectively in search and one could argue that the FTC shouldn't be in the business of rescuing a company from competing ineffectively.
Personally, I don't think it's too interesting to discuss the position of the BC memo vs. the BE memo at length because the positions the BE memo takes seem extremely weak. It's not fair to call it a straw man because it's a real position, and one that carried the day at the FTC, but the decision to take action or not seemed more about philosophy than the arguments in the memos. But we can discuss what else might've been done.
What happened after the FTC declined to pursue antitrust action was that Microsoft effectively defunded Bing as a serious bet, taking resources that could've gone to continuing to fund a very expensive fight against Google, and moving them to other bets that it deemed to be higher ROI. The big bets Microsoft pursued were Azure, Office, and HoloLens (and arguably Xbox). Hololens was a pie-in-the-sky bet, but Azure and Office were lines of business where Microsoft could, instead of fighting an uphill battle where their competitor can use its dominance in related markets to push around competitors, Microsoft could fight downhill battles where they can use their dominance in related markets to push around competitors, resulting in a much higher return per dollar invested. As someone who worked on Bing and thought that BIng had the potential to seriously compete with Google given sustained, unprofitable, heavy investment, I find that disappointing but also likely the correct business decision. If you look at any particular submarket, like Teams vs. Slack, the Microsoft product doesn't need to be nearly as good as the competing product to take over the market, which is the opposite of the case in search, where Google's ability to push competitors around means that Bing would have to be much better than Google to attain marketshare parity.
Based on their public statements, Biden's DoJ Antitrust AAG appointee, Jonathan Kanter, would argue for pursuing antitrust action under the circumstances, as would Biden's FTC commissioner and chair appointee Lina Khan. Prior to her appointment as FTC commissioner and chair, Khan was probably best known for writing Amazon's Antitrust Paradox, which has been influential as well as controversial. Obama appointees, who more frequently agreed with the kind of reasoning from the BE memo, would have argued against antitrust action and the investigation under discussion was stopped on their watch. More broadly, they argued against the philosophy driving Kanter and Khan. Obama's FTC Commissioner appointee, GMU economist and legal scholar Josh Wright actually wrote a rebuttal titled "Requiem for a Paradox: The Dubious Rise and Inevitable Fall of Hipster Antitrust", a scathing critique of Khan's position.
If, in 2012, the FTC and DoJ were run by Biden appointees instead of Obama appointees, what difference would that have made? We can only speculate, but one possibility would be that they would've taken action and then lost, as happened with the recent cases against Meta and Microsoft which seem like they would not have been undertaken under an Obama FTC and DoJ. Under Biden appointees, there's been much more vigorous use of the laws that are on the books, the Sherman Act, the Clayton Act, the FTC Act, the Robinson–Patman Act, as well as "smaller" antitrust laws, but the opinion of the courts hasn't changed under Biden and this has led to a number of unsuccessful antitrust cases in tech. Both the BE and BC memos dedicate significant space to whether or not a particular line of reasoning will hold up in court. Biden's appointees are much less concerned with this than previous appointees and multiple people in the DoJ and the FTC are on the record saying things like "it is our duty to enforce the law", meaning that when they see violations of the antitrust laws that were put into place by elected officials, it's their job to pursue these violations even if courts may not agree with the law.
Another possibility is that there would've been some action, but the action would've been in line with most corporate penalties we see. Something like a small fine that costs the company an insignificant fraction of marginal profit they made from their actions, or some kind of consent decree (basically a cease and desist), where the company will be required to stop doing specific actions while keeping their marketshare, keeping the main thing they wanted to gain, a massive advantage in a market dominated by network effects. Perhaps there will be a few more meetings where "[w]e didn't take notes for obvious reasons" to work around the new limitations and business as usual will continue. Given the specific allegations in the FTC memos and the attitudes of the courts at the time, my guess is that something like this second set of possibilities would've been the most likely outcome had the FTC proceeded with their antitrust investigation instead of dropping it, some kind of nominal victory that makes little to no difference in practice. Given how long it takes for these cases to play out, it's overwhelmingly likely that Microsoft would've already scaled back its investment in Bing and moved Bing from a subsidized bet it was trying to grow to a profitable business it wanted to keep by the time any decision was made. There are a number of cases that were brought by other countries which had remedies that were in line with what we might've expected if the FTC investigation continued. On Google using market power in mobile to push software Google wants to nearly all Android phones, an EU and was nominally successful but made little to no difference in practice. Cristina Caffara of the Centre for Economic Policy Research characterized this as
Europe has failed to drive change on the ground. Why? Because we told them, don't do it again, bad dog, don't do it again. But in fact, they all went and said 'ok, ok', and then went out, ran back from the back door and did it again, because they're smarter than the regulator, right? And that's what happens.
So, on the tying case, in Android, the issue was, don't tie again so they say, "ok, we don't tie". Now we got a new system. If you want Google Play Store, you pay $100. But if you want to put search in every entry point, you get a discount of $100 ... the remedy failed, and everyone else says, "oh, that's a nice way to think about it, very clever"
Another pair of related cases are Yandex's Russian case on mobile search defaults and a later EU consent decree. In 2015, Yandex brought a suit about mobile default status on Android in Russia, which was settled by adding a "choice screen" which has users pick their search engine without preferencing a default. This immediately caused Yandex to start gaining marketshare on Google and Yandex eventually surpassed Google in marketshare in Russia according to statcounter. In 2018, the EU required a similar choice screen in Europe, which didn't make much of a difference, except maybe sort of in the Czech republic. There are a number of differences between the situation in Russia and in the EU. One, arguably the most important, is that when Yandex brought the case against Google in Russia, Yandex was still fairly competitive, with marketshare in the high 30% range. At the time of the EU decision in 2018, Bing was the #2 search engine in Europe, with about 3.6% marketshare. Giving consumers a choice when one search engine completely dominates the market can be expected to have fairly little impact. One argument the BE memo heavily relies on is the idea that, if we intervene in any way, that could have bad effects down the line, so we should be very careful and probably not do anything, just in case. But in these winner-take-most markets with such strong network effects, there's a relatively small window in which you can cheaply intervene. Perhaps, and this is highly speculative, if the FTC required a choice screen in 2012, Bing would've continued to invest enough to at least maintain its marketshare against Google.
For verticals, in shopping, the EU required some changes to how Google presents results in 2017. This appears to have had little to no impact, being both perhaps 5-10 years too late and also a trivial change that wouldn't have made much difference even if enacted a decade earlier. The 2017 ruling came out of a case that started in 2010, and in the 7 years it took to take action, Google managed to outcompete its vertical competitors, making them barely relevant at best.
Another place we could look is at the Microsoft antitrust trial. That's a long story, at least as long as this document, but to very briefly summarize, in 1990, the FTC started an investigation over Microsoft's allegedly anticompetitive conduct. A vote to continue the investigation ended up in a 2-2 tie, causing the investigation to be closed. The DoJ then did its own investigation, which led to a consent decree that was generally considered to not be too effective. There was then a 1998 suit by the DoJ about Microsoft's use of monopoly power in the browser market, which initially led to a decision to break Microsoft up. But, on appeal, the breakup was overturned, which led to a settlement in 2002. A major component of the 1998 case was about browser bundling and Microsoft's attack on Netscape. By the time the case was settled, in 2002, Netscape was effectively dead. The parts of the settlements having to do with interoperability were widely regarded as ineffective at the time, not only because Netscape was dead, but because they weren't going to be generally useful. A number of economists took the same position as the BE memo, that no intervention should've happened at the time and that any intervention is dangerous and could lead to a fettering of innovation. Nobel Prize winning economist Milton Friedman wrote a Cato Policy Forum essay titled "The Business Community's Suicidal Impulse", predicting that tech companies calling for antitrust action against Microsoft were committing suicide, and that a critical threshold had been passed and that this would lead to the bureaucratization of Silicon Valley
When I started in this business, as a believer in competition, I was a great supporter of antitrust laws; I thought enforcing them was one of the few desirable things that the government could do to promote more competition. But as I watched what actually happened, I saw that, instead of promoting competition, antitrust laws tended to do exactly the opposite, because they tended, like so many government activities, to be taken over by the people they were supposed to regulate and control. And so over time I have gradually come to the conclusion that antitrust laws do far more harm than good and that we would be better off if we didn’t have them at all, if we could get rid of them. But we do have them.
Under the circumstances, given that we do have antitrust laws, is it really in the self-interest of Silicon Valley to set the government on Microsoft? ... you will rue the day when you called in the government. From now on the computer industry, which has been very fortunate in that it has been relatively free of government intrusion, will experience a continuous increase in government regulation. Antitrust very quickly becomes regulation. Here again is a case that seems to me to illustrate the suicidal impulse of the business community.
In retrospect, we can see that this wasn't correct and, if anything, was the opposite of correct. On the idea that even attempting antirust action against Microsoft would lead to an inevitable increase in government intervention, we saw the opposite, a two-decade long period of relatively light regulation and antitrust activity. And in terms of the impacts on innovation, although the case against Microsoft was too little and too late to save Netscape, Google's success appears to be causally linked to the antitrust trial. At one point, in the early days of Google, when Google had no market power and Microsoft effectively controlled how people access the internet, Microsoft internally discussed proposals aimed at killing Google. One proposal involved redirecting users who tried to navigate to Google to Bing (at the time, called MSN Search, and of course this was before Chrome existed and IE dominated the browser market). Another idea was to put up a big scary warning that warned users that Google was dangerous, much like the malware warnings browsers have today. Gene Burrus, a lawyer for Microsoft at the time, stated that Microsoft chose not to attempt to stop users from navigating to google.com due to concerns about further antitrust action after they'd been through nearly a decade of serious antitrust scrutiny. People at both Google and Microsoft who were interviewed about this both believe that Microsoft would've killed Google had they done this so, in retrospect, we can see that Milton Friedman was wrong about the impacts of the Microsoft antitrust investigations and that one can make the case that it's only because of the antitrust investigations that web 1.0 companies like Google and Facebook were able to survive, let alone flourish.
Another possibility is that a significant antitrust action would've been undertaken, been successful, and been successful quickly enough to matter. It's possible that, by itself, a remedy wouldn't have changed the equation for Bing vs. Google, but if a reasonable remedy was found and enacted, it still could've been in time to keep Yelp and other vertical sites as serious concerns and maybe even spur more vertical startups. And in the hypothetical universe where people with the same philosophy as Biden's appointees were running the FTC and the DoJ, we might've also seen antitrust action against Microsoft in markets where they can leverage their dominance in adjacent markets, making Bing a more appealing area for continued heavy investment. Perhaps that would've resulted in Bing being competitive with Google and the aforementioned concerns that "sophisticated customers" like Amazon and IAC had may not have come to pass. With antitrust against Microsoft and other large companies that can use their dominance to push competitors around, perhaps Slack would still be an independent product and we'd see more startups in enterprise tools (a number of commenters believe that Slack was basically forced into being acquired because it's too difficult to compete with Teams given Microsoft's dominance in related markets). And Slack continuing to exist and innovate is small potatoes — the larger hypothetical impact would be all of the new startups and products that would be created that no one even bothers to attempt because they're concerned that a behemoth with an integrated bundle like Microsoft would crush their standalone product. If you add up all of these, if not best-case, at least very-good-case outcomes for antitrust advocates, one could argue that consumers and businesses would be better off. But, realistically, it's hard to see how this very-good-case set of outcomes could have come to pass.
Coming back to the FTC memo, if we think about what it would take to put together a set of antitrust actions that actually fosters real competition, that seems extraordinarily difficult. A number of the more straightforward and plausible sounding solutions are off the table for political reasons, due to legal precedent, or due to arguments like the Boies argument we referenced or some of the arguments in the BE memo that are clearly incorrect, but appear to be convincing to very important people.
For the solutions that seem to be on the table, weighing the harms caused by them is non-trivial. For example, let's say the FTC mandated a mobile and desktop choice screen in 2012. This would've killed Mozilla in fairly short order unless Mozilla completely changed its business model because Mozilla basically relies on payments from Google for default status to survive. We've seen with Opera that even when you have a superior browser that introduces features that other browsers later copy, which has better performance than other browsers, etc., you can't really compete with free browsers when you have a paid browser. So then we would've quickly been down to IE/Edge and Chrome. And in terms of browser engines, just Chrome after not too long as Edge is now running Chrome under the hood. Maybe we can come up with another remedy that allows for browser competition as well, but the BE memo isn't wrong to note that antitrust remedies can cause other harms.
Another example which highlights the difficulty of crafting a politically suitable remedy are the restrictions the Bundeskartellamt imposed against Facebook, which have to do with user privacy and use of data (for personalization, ranking, general ML training, etc.), which is considered an antitrust issue in Germany. Michal Gal, Professor and Director of the Forum on Law and Markets at the University of Haifa pointed out that, of course Facebook, in response to the rulings, is careful to only limit its use of data if Facebook detects that you're German. If the concern is that ML models are trained on user data, this doesn't do much to impair Facebook's capability. Hypothetically, if Germany had a tech scene that was competitive with American tech and German companies were concerned about a similar ruling being leveled against them, this would be disadvantageous to nascent German companies that initially focus on the German market before expanding internationally. For Germany, this is only a theoretical concern as, other than SAP, no German company has even approached the size and scope of large American tech companies. But when looking at American remedies and American regulation, this isn't a theoretical concern, and some lawmakers will want to weigh the protection of American consumers against the drag imposed on American firms when compared to Korean, Chinese, and other foreign firms that can grow in local markets with fewer privacy concerns before expanding to international markets. This concern, if taken seriously, could be used to argue against nearly any pro-antitrust action argument.
This document is already long enough, so we'll defer a detailed discussion of policy specifics for another time, but in terms of high-level actions, one thing that seems like it would be helpful is to have tech people intimately involved in crafting remedies and regulation as well as during investigations2. From the directors memos on the 2011-2021 FTC investigation that are publicly available, it would appear this was not done because the arguments from the BE memos that wouldn't pass the sniff test for a tech person appear to have been taken seriously. Another example is the one EU remedy that Cristina Caffara noted was immediately worked around by Google, in a way that many people in tech would find to be a delightful "hack".
There's a long history of this kind of "hacking the system" being lauded in tech going back to before anyone called it "tech" and it was just physics and electrical engineering. To pick a more recent example, one of the reasons Sam Altman become President of Y Combinator, which eventually led to him becoming CEO of Open AI was that Paul Graham admired his ability to hack systems; in his 2010 essay on founders, under the section titled "Naughtiness", Paul wrote:
Though the most successful founders are usually good people, they tend to have a piratical gleam in their eye. They're not Goody Two-Shoes type good. Morally, they care about getting the big questions right, but not about observing proprieties. That's why I'd use the word naughty rather than evil. They delight in breaking rules, but not rules that matter. This quality may be redundant though; it may be implied by imagination.
Sam Altman of Loopt is one of the most successful alumni, so we asked him what question we could put on the Y Combinator application that would help us discover more people like him. He said to ask about a time when they'd hacked something to their advantage—hacked in the sense of beating the system, not breaking into computers. It has become one of the questions we pay most attention to when judging applications.
Or, to pick one of countless examples from Google, in order to reduce travel costs at Google, Google engineers implemented a system where they computed some kind of baseline "expected cost for flights, and then gave people a credit for taking flights that came in under the baseline costs that could be used to upgrade future flights and travel accommodations. This was a nice experience for employees compared to what stodgier companies were doing in terms of expense limits and Google engineers were proud of creating a system that made things better for everyone, which was one kind of hacking the system. The next level of hacking the system was when some employees optimized their flights and even set up trips to locations that were highly optimizable (many engineers would consider this a fun challenge, a variant of classic dynamic programming problems that are given in interviews, etc.), allowing them to upgrade to first class flights and the nicest hotels.
When I've talked about this with people in management in traditional industries, they've frequently been horrified and can't believe that these employees weren't censured or even fired for cheating the system. But when I was at Google, people generally found this to be admirable, as it exemplified the hacker spirit.
We can see, from the history of antitrust in tech going back at least two decades, that courts, regulators, and legislators have not been prepared for the vigor, speed, and delight with which tech companies hack the system.
And there's precedent for bringing in tech folks to work on the other side of the table. For example, this was done in the big Microsoft antitrust case. But there are incentive issues that make this difficult at every level that stem from, among other things, the sheer amount of money that tech companies are willing to pay out. If I think about tech folks I know who are very good at the kind of hacking the system described here, the ones who want to be employed at big companies frequently make seven figures (or more) annually, a sum not likely to be rivaled by an individual consulting contract with the DoJ or FTC. If we look at the example of Microsoft again, the tech group that was involved was managed by Ron Schnell, who was taking a break from working after his third exit, but people like that are relatively few and far between. Of course there are people who don't want to work at big companies for a variety of reasons, often moral reasons or a dislike of big company corporate politics, but most people I know who fit that description haven't spent enough time at big companies to really understand the mechanics of how big companies operate and are the wrong people for this job even if they're great engineers and great hackers.
At an antitrust conference a while back, a speaker noted that the mixing and collaboration between the legal and economics communities was a great boon for antitrust work. Notably absent from the speech as well as the conference were practitioners from industry. The conference had the feel of an academic conference, so you might see CS academics at the conference some day, but even if that were to happen, many of the policy-level discussions are ones that are outside the area of interest of CS academics. For example, one of the arguments from the BE memo that we noted as implausible was the way they used MAU to basically argue that switching costs were low. That's something outside the area of research of almost every CS academic, so even if the conference were to expand and bring in folks who work closely with tech, the natural attendees would still not be the right people to weigh in on the topic when it comes to the plausibility of nitty gritty details.
Besides the aforementioned impact on policy discussions, the lack of collaboration with tech folks also meant that, when people spoke about the motives of actors, they would often make assumptions that were unwarranted. On one specific example of what someone might call a hack of the system, the speaker described an exec's reaction (high-fives, etc.), and inferred a contempt for lawmakers and the law that was not in evidence. It's possible the exec in question does, in fact, have a contempt and disdain for lawmakers and the law, but that celebration is exactly what you might've seen after someone at Google figured out how to get upgraded to first class "for free" on almost all their flights by hacking the system at Google, which wouldn't indicate contempt or disdain at all.
Coming back to the incentive problem, it goes beyond getting people who understand tech on the other side of the table in antitrust discussions. If you ask Capitol Hill staffers who were around at the time, the general belief is that the primary factor that scuttled the FTC investigation was Google's lobbying, and of course Google and other large tech companies spend more on lobbying than entities that are interested in increased antitrust scrutiny.
And in the civil service, if we look at the lead of the BC investigation and the first author on the BC memo, they're now Director and Associate General Counsel of Competition and Regulatory Affairs at Facebook. I don't know them, so I can't speak to their motivations, but if I were offered as much money as I expect they make to work on antitrust and other regulatory issues at Facebook, I'd probably take the offer. Even putting aside the pay, if I was a strong believer in the goals of increased antitrust enforcement, that would still be a very compelling offer. Working for the FTC, maybe you lead another investigation where you write a memo that's much stronger than the opposition memo, which doesn't matter when a big tech company pours more lobbying money into D.C. and the investigation is closed. Or maybe your investigation leads to an outcome like the EU investigation that led to a "choice screen" that was too little and far too late. Or maybe it leads to something like the Android Play Store untying case where, seven years after the investigation was started, an enterprising Google employee figures out a "hack" that makes the consent decree useless in about five minutes. At least inside Facebook, you can nudge the company towards what you think is right and have some impact on how Facebook treats consumers and competitors.
Looking at it from the standpoint of people in tech (as opposed to people working in antitrust), in my extended social circles, it's common to hear people say "I'd never work at company X for moral reasons". That's a fine position to take but, almost everyone I know who does this ends up working at a much smaller company that has almost no impact on the world. If you want to take a moral stand, you're more likely to make a difference by working from the inside or finding a smaller direct competitor and helping it become more successful.
Thanks to Laurence Tratt, Yossi Kreinin, Justin Hong, [email protected], Sophia Wisdom, @[email protected], @[email protected], and Misha Yagudin for comments/corrections/discussion
This is analogous to the "non-goals" section of a technical design doc, but weaker, in that a non-goal in a design doc is often a positive statement that implies something that couldn't be implied from reading the doc, whereas the non-goal statements themselves don't add any informatio
By "Barbara R. Blank, Gustav P. Chiarello, Melissa Westman-Cherry, Matthew Accornero, Jennifer Nagle, Anticompetitive Practices Division; James Rhilinger, Healthcare Division; James Frost, Office of Policy and Coordination; Priya B. Viswanath, Office of the Director; Stuart Hirschfeld, Danica Noble, Northwest Region; Thomas Dahdouh, Western Region-San Francisco, Attorneys; Daniel Gross, Robert Hilliard, Catherine McNally, Cristobal Ramon, Sarah Sajewski, Brian Stone, Honors Paralegals; Stephanie Langley, Investigator"
Dated August 8, 2012
c. Specifics of Google's Syndication Agreements
"Bureau of Economics
August 8, 2012
From: Christopher Adams and John Yun, Economists"
[I stopped taking detailed notes at this point because taking notes that are legible to other people (as opposed to just for myself) takes about an order of magnitude longer, and I didn't think that there was much of interest here. I generally find comments of the form "I stopped reading at X" to be quite poor, in that people making such comments generally seem to pick some trivial thing that's unimportant and then declare and entire document to be worthless based on that. This pattern is also common when it comes to engineers, institutions, sports players, etc. and I generally find it counterproductive in those cases as well. However, in this case, there isn't really a single, non-representative, issue. The majority of the reasoning seems not just wrong, but highly disconnected from the on-the-ground situation. More notes indicating that the authors are making further misleading or incorrect arguments in the same style don't seem very useful. I did read the rest of the document and I also continue to summarize a few bits, below. I don't want to call them "highlights" because that would imply that I pulled out particularly interesting or compelling or incorrect bits and it's more of a smattering of miscellaneous parts with no particular theme]
[for these, I continued writing high-level summaries, not detailed summaries]
By analogy to a case that many people in tech are familiar with, consider this exchange between Oracle counsel David Boies and Judge William Alsup on the rangeCheck function, which checks if a range is a valid array access or not given the length of an array and throws an exception if the access is out of range:
Boies previously brought up this function as a non-trivial piece of work and then argues that, in their haste, a Google engineer copied this function from Oracle. As Alsup points out, the function is trivial, so trivial that it wouldn't be worth looking it up to copy and that even a high school student could easily produce the function from scratch. Boies then objects that, sure, maybe a high school student could write the function, but it might take an hour or more and Alsup correctly responds that an hour is implausible and that it might take five minutes.
Although nearly anyone who could pass a high school programming class would find Boeis's argument not just wrong but absurd3, more like a joke than something that someone might say seriously, it seems reasonable for Boies to make the argument because people presiding over these decisions in court, in regulatory agencies, and in the legislature, sometimes demonstrate a lack of basic understanding of tech. Since my background is in tech and not law or economics, I have no doubt that this analysis will miss some basics about law and economics in the same way that most analyses I've read seem miss basics about tech, but since there's been extensive commentary on this case from people with strong law and economics backgrounds, I don't see a need to cover those issues in depth here because anyone who's interested can read another analysis instead of or in addition to this one.
[return]Although this document is focused on tech, the lack of hands-on industry-expertise in regulatory bodies, legislation, and the courts, appears to cause problems in other industries as well. An example that's relatively well known due to a NY Times article that was turned into a movie is DuPont's involvement in the popularization of PFAS and, in particular, PFOA. Scientists at 3M and DuPont had evidence of the harms of PFAS going back at least to the 60s, and possibly even as far back as the 50s. Given the severe harms that PFOA caused to people who were exposed to it in significant concentrations, it would've been difficult to set up a production process for PFOA without seeing the harm it caused, but this knowledge, which must've been apparent to senior scientists and decision makers in 3M and DuPont, wasn't understood by regulatory agencies for almost four decades after it was apparent to chemical companies.
By the way, the NY Times article is titled "The Lawyer Who Became DuPont’s Worst Nightmare" and it describes how DuPont made $1B/yr in profit for years while hiding the harms of PFOA, which was used in the manufacturing process for Teflon. This lawyer brought cases against DuPont that were settled for hundreds of millions of dollars; according to the article and movie, the litigation didn't even cost DuPont a single year's worth of PFOA profit. Also, DuPont manage to drag out the litigation for many years, continuing to reap the profit from PFOA. Now that enough evidence has mounted against PFOA, Teflon is now manufactured using PFO2OA or FRD-903, which are newer and have a less well understood safety profile than PFOA. Perhaps the article could be titled "The Lawyer Who Became DuPont's Largest Mild Annoyance".
[return]In the media, I've sometimes seen this framed as a conflict between tech vs. non-tech folks, but we can see analogous comments from people outside of tech. For example, in a panel discussion with Yale SOM professor Fiona Scott Morton and DoJ Antitrust Principal Deputy AAG Doha Mekki, Scott Morton noted that the judge presiding over the Sprint/T-mobile merger proceedings, a case she was an expert witness for, had comically wrong misunderstandings about the market, and that it's common for decisions to be made which are disconnected from "market realities". Mekki seconded this sentiment, saying "what's so fascinating about some of the bad opinions that Fiona identified, and there are many, there's AT&T Time Warner, Sabre Farelogix, T-mobile Sprint, they're everywhere, there's Amex, you know ..."
If you're seeing this or the other footnote in mouseover text and/or tied to a broken link, this is an issue with Hugo. At this point, I've spent more than an entire blog post's worth of effort working around Hugo breakage and am trying to avoid spending more time working around issues in a tool that makes breaking changes at a high rate. If you have a suggestion to fix this, I'll try it, otherwise I'll try to fix it when I switch away from Hugo.
[return]2024-03-16 08:00:00
In 2017, we looked at how web bloat affects users with slow connections. Even in the U.S., many users didn't have broadband speeds, making much of the web difficult to use. It's still the case that many users don't have broadband speeds, both inside and outside of the U.S. and that much of the modern web isn't usable for people with slow internet, but the exponential increase in bandwidth (Nielsen suggests this is 50% per year for high-end connections) has outpaced web bloat for typical sites, making this less of a problem than it was in 2017, although it's still a serious problem for people with poor connections.
CPU performance for web apps hasn't scaled nearly as quickly as bandwidth so, while more of the web is becoming accessible to people with low-end connections, more of the web is becoming inaccessible to people with low-end devices even if they have high-end connections. For example, if I try browsing a "modern" Discourse-powered forum on a Tecno Spark 8C, it sometimes crashes the browser. Between crashes, on measuring the performance, the responsiveness is significantly worse than browsing a BBS with an 8 MHz 286 and a 1200 baud modem. On my 1Gbps home internet connection, the 2.6 MB compressed payload size "necessary" to load message titles is relatively light. The over-the-wire payload size has "only" increased by 1000x, which is dwarfed by the increase in internet speeds. But the opposite is true when it comes to CPU speeds — for web browsing and forum loading performance, the 8-core (2 1.6 GHz Cortex-A75 / 6 1.6 GHz Cortex-A55) CPU can't handle Discourse. The CPU is something like 100000x faster than our 286. Perhaps a 1000000x faster device would be sufficient.
For anyone not familiar with the Tecno Spark 8C, today, a new Tecno Spark 8C, a quick search indicates that one can be hand for USD 50-60 in Nigeria and perhaps USD 100-110 in India. As a fraction of median household income, that's substantially more than a current generation iPhone in the U.S. today.
By worldwide standards, the Tecno Spark 8C isn't even close to being a low-end device, so we'll also look at performance on an Itel P32, which is a lower end device (though still far from the lowest-end device people are using today). Additionally, we'll look at performance with an M3 Max Macbook (14-core), an M1 Pro Macbook (8-core), and the M3 Max set to 10x throttling in Chrome dev tools. In order to give these devices every advantage, we'll be on fairly high-speed internet (1Gbps, with a WiFi router that's benchmarked as having lower latency under load than most of its peers). We'll look at some blogging platforms and micro-blogging platforms (this blog, Substack, Medium, Ghost, Hugo, Tumblr, Mastodon, Twitter, Threads, Bluesky, Patreon), forum platforms (Discourse, Reddit, Quora, vBulletin, XenForo, phpBB, and myBB), and platforms commonly used by small businesses (Wix, Squarespace, Shopify, and WordPress again).
In the table below, every row represents a website and every non-label column is a metric. After the website name column, we have the compressed size transferred over the wire (wire) and the raw, uncompressed, size (raw). Then we have, for each device, Largest Contentful Paint* (LCP*) and CPU usage on the main thread (CPU). Google's docs explain LCP as
Largest Contentful Paint (LCP) measures when a user perceives that the largest content of a page is visible. The metric value for LCP represents the time duration between the user initiating the page load and the page rendering its primary content
LCP is a common optimization target because it's presented as one of the primary metrics in Google PageSpeed Insights, a "Core Web Vital" metric. There's an asterisk next to LCP as used in this document because, LCP as measured by Chrome is about painting a large fraction of the screen, as opposed to the definition above, which is about content. As sites have optimized for LCP, it's not uncommon to have a large paint (update) that's completely useless to the user, with the actual content of the page appearing well after the LCP. In cases where that happens, I've used the timestamp when useful content appears, not the LCP as defined by when a large but useless update occurs. The full details of the tests and why these metrics were chosen are discussed in an appendix.
Although CPU time isn't a "Core Web Vital", it's presented here because it's a simple metric that's highly correlated with my and other users' perception of usability on slow devices. See appendix for more detailed discussion on this. One reason CPU time works as a metric is that, if a page has great numbers for all other metrics but uses a ton of CPU time, the page is not going to be usable on a slow device. If it takes 100% CPU for 30 seconds, the page will be completely unusable for 30 seconds, and if it takes 50% CPU for 60 seconds, the page will be barely usable for 60 seconds, etc. Another reason it works is that, relative to commonly used metrics, it's hard to cheat on CPU time and make optimizations that significantly move the number without impacting user experience.
The color scheme in the table below is that, for sizes, more green = smaller / fast and more red = larger / slower. Extreme values are in black.
| Site | Size | M3 Max | M1 Pro | M3/10 | Tecno S8C | Itel P32 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| wire | raw | LCP* | CPU | LCP* | CPU | LCP* | CPU | LCP* | CPU | LCP* | CPU | |
| danluu.com | 6kB | 18kB | 50ms | 20ms | 50ms | 30ms | 0.2s | 0.3s | 0.4s | 0.3s | 0.5s | 0.5s |
| HN | 11kB | 50kB | 0.1s | 30ms | 0.1s | 30ms | 0.3s | 0.3s | 0.5s | 0.5s | 0.7s | 0.6s |
| MyBB | 0.1MB | 0.3MB | 0.3s | 0.1s | 0.3s | 0.1s | 0.6s | 0.6s | 0.8s | 0.8s | 2.1s | 1.9s |
| phpBB | 0.4MB | 0.9MB | 0.3s | 0.1s | 0.4s | 0.1s | 0.7s | 1.1s | 1.7s | 1.5s | 4.1s | 3.9s |
| WordPress | 1.4MB | 1.7MB | 0.2s | 60ms | 0.2s | 80ms | 0.7s | 0.7s | 1s | 1.5s | 1.2s | 2.5s |
| WordPress (old) | 0.3MB | 1.0MB | 80ms | 70ms | 90ms | 90ms | 0.4s | 0.9s | 0.7s | 1.7s | 1.1s | 1.9s |
| XenForo | 0.3MB | 1.0MB | 0.4s | 0.1s | 0.6s | 0.2s | 1.4s | 1.5s | 1.5s | 1.8s | FAIL | FAIL |
| Ghost | 0.7MB | 2.4MB | 0.1s | 0.2s | 0.2s | 0.2s | 1.1s | 2.2s | 1s | 2.4s | 1.1s | 3.5s |
| vBulletin | 1.2MB | 3.4MB | 0.5s | 0.2s | 0.6s | 0.3s | 1.1s | 2.9s | 4.4s | 4.8s | 13s | 16s |
| Squarespace | 1.9MB | 7.1MB | 0.1s | 0.4s | 0.2s | 0.4s | 0.7s | 3.6s | 14s | 5.1s | 16s | 19s |
| Mastodon | 3.8MB | 5.3MB | 0.2s | 0.3s | 0.2s | 0.4s | 1.8s | 4.7s | 2.0s | 7.6s | FAIL | FAIL |
| Tumblr | 3.5MB | 7.1MB | 0.7s | 0.6s | 1.1s | 0.7s | 1.0s | 7.0s | 14s | 7.9s | 8.7s | 8.7s |
| Quora | 0.6MB | 4.9MB | 0.7s | 1.2s | 0.8s | 1.3s | 2.6s | 8.7s | FAIL | FAIL | 19s | 29s |
| Bluesky | 4.8MB | 10MB | 1.0s | 0.4s | 1.0s | 0.5s | 5.1s | 6.0s | 8.1s | 8.3s | FAIL | FAIL |
| Wix | 7.0MB | 21MB | 2.4s | 1.1s | 2.5s | 1.2s | 18s | 11s | 5.6s | 10s | FAIL | FAIL |
| Substack | 1.3MB | 4.3MB | 0.4s | 0.5s | 0.4s | 0.5s | 1.5s | 4.9s | 14s | 14s | FAIL | FAIL |
| Threads | 9.3MB | 13MB | 1.5s | 0.5s | 1.6s | 0.7s | 5.1s | 6.1s | 6.4s | 16s | 28s | 66s |
| 4.7MB | 11MB | 2.6s | 0.9s | 2.7s | 1.1s | 5.6s | 6.6s | 12s | 19s | 24s | 43s | |
| Shopify | 3.0MB | 5.5MB | 0.4s | 0.2s | 0.4s | 0.3s | 0.7s | 2.3s | 10s | 26s | FAIL | FAIL |
| Discourse | 2.6MB | 10MB | 1.1s | 0.5s | 1.5s | 0.6s | 6.5s | 5.9s | 15s | 26s | FAIL | FAIL |
| Patreon | 4.0MB | 13MB | 0.6s | 1.0s | 1.2s | 1.2s | 1.2s | 14s | 1.7s | 31s | 9.1s | 45s |
| Medium | 1.2MB | 3.3MB | 1.4s | 0.7s | 1.4s | 1s | 2s | 11s | 2.8s | 33s | 3.2s | 63s |
| 1.7MB | 5.4MB | 0.9s | 0.7s | 0.9s | 0.9s | 6.2s | 12s | 1.2s | ∞ | FAIL | FAIL | |
At a first glance, the table seems about right, in that the sites that feel slow unless you have a super fast device show up as slow in the table (as in, max(LCP*,CPU)) is high on lower-end devices). When I polled folks about what platforms they thought would be fastest and slowest on our slow devices (Mastodon, Twitter, Threads), they generally correctly predicted that Wordpress and Ghost would be faster than Substack and Medium, and that Discourse would be much slower than old PHP forums like phpBB, XenForo, and vBulletin. I also pulled Google PageSpeed Insights (PSI) scores for pages (not shown) and the correlation isn't as strong with those numbers because a handful of sites have managed to optimize their PSI scores without actually speeding up their pages for users.
If you've never used a low-end device like this, the general experience is that many sites are unusable on the device and loading anything resource intensive (an app or a huge website) can cause crashes. Doing something too intense in a resource intensive app can also cause crashes. While reviews note that you can run PUBG and other 3D games with decent performance on a Tecno Spark 8C, this doesn't mean that the device is fast enough to read posts on modern text-centric social media platforms or modern text-centric web forums. While 40fps is achievable in PUBG, we can easily see less than 0.4fps when scrolling on these sites.
We can see from the table how many of the sites are unusable if you have a slow device. All of the pages with 10s+ CPU are a fairly bad experience even after the page loads. Scrolling is very jerky, frequently dropping to a few frames per second and sometimes well below. When we tap on any link, the delay is so long that we can't be sure if our tap actually worked. If we tap again, we can get the dreaded situation where the first tap registers, which then causes the second tap to do the wrong thing, but if we wait, we often end up waiting too long because the original tap didn't actually register (or it registered, but not where we thought it did). Although MyBB doesn't serve up a mobile site and is penalized by Google for not having a mobile friendly page, it's actually much more usable on these slow mobiles than all but the fastest sites because scrolling and tapping actually work.
Another thing we can see is how much variance there is in the relative performance on different devices. For example, comparing an M3/10 and a Tecno Spark 8C, for danluu.com and Ghost, an M3/10 gives a halfway decent approximation of the Tecno Spark 8C (although danluu.com loads much too quickly), but the Tecno Spark 8C is about three times slower (CPU) for Medium, Substack, and Twitter, roughly four times slower for Reddit and Discourse, and over an order of magnitude faster for Shopify. For Wix, the CPU approximation is about accurate, but our `Tecno Spark 8C is more than 3 times slower on LCP*. It's great that Chrome lets you conveniently simulate a slower device from the convenience of your computer, but just enabling Chrome's CPU throttling (or using any combination of out-of-the-box options that are available) gives fairly different results than we get on many real devices. The full reasons for this are beyond the scope of the post; for the purposes of this post, it's sufficient to note that slow pages are often super-linearly slow as devices get slower and that slowness on one page doesn't strongly predict slowness on another page.
If take a site-centric view instead of a device-centric view, another way to look at it is that sites like Discourse, Medium, and Reddit, don't use all that much CPU on our fast M3 and M1 computers, but they're among the slowest on our Tecno Spark 8C (Reddit's CPU is shown as ∞ because, no matter how long we wait with no interaction, Reddit uses ~90% CPU). Discourse also sometimes crashed the browser after interacting a bit or just waiting a while. For example, one time, the browser crashed after loading Discourse, scrolling twice, and then leaving the device still for a minute or two. For consistency's sake, this wasn't marked as FAIL in the table since the page did load but, realistically, having a page so resource intensive that the browser crashes is a significantly worse user experience than any of the FAIL cases in the table. When we looked at how web bloat impacts users with slow connections, we found that much of the web was unusable for people with slow connections and slow devices are no different.
Another pattern we can see is how the older sites are, in general, faster than the newer ones, with sites that (visually) look like they haven't been updated in a decade or two tending to be among the fastest. For example, MyBB, the least modernized and oldest looking forum is 3.6x / 5x faster (LCP* / CPU) than Discourse on the M3, but on the Tecno Spark 8C, the difference is 19x / 33x and, given the overall scaling, it seems safe to guess that the difference would be even larger on the Itel P32 if Discourse worked on such a cheap device.
Another example is Wordpress (old) vs. newer, trendier, blogging platforms like Medium and Substack. Wordpress (old) is is 17.5x / 10x faster (LCP* / CPU) than Medium and 5x / 7x faster (LCP* / CPU) faster than Substack on our M3 Max, and 4x / 19x and 20x / 8x faster, respectively, on our Tecno Spark 8C. Ghost is a notable exception to this, being a modern platform (launched a year after Medium) that's competitive with older platforms (modern Wordpress is also arguably an exception, but many folks would probably still consider that to be an old platform). Among forums, NodeBB also seems to be a bit of an exception (see appendix for details).
Sites that use modern techniques like partially loading the page and then dynamically loading the rest of it, such as Discourse, Reddit, and Substack, tend to be less usable than the scores in the table indicate. Although, in principle, you could build such a site in a simple way that works well with cheap devices but, in practice sites that use dynamic loading tend to be complex enough that the sites are extremely janky on low-end devices. It's generally difficult or impossible to scroll a predictable distance, which means that users will sometimes accidentally trigger more loading by scrolling too far, causing the page to lock up. Many pages actually remove the parts of the page you scrolled past as you scroll; all such pages are essentially unusable. Other basic web features, like page search, also generally stop working. Pages with this kind of dynamic loading can't rely on the simple and fast ctrl/command+F search and have to build their own search. How well this works varies (this used to work quite well in Google docs, but for the past few months or maybe a year, it takes so long to load that I have to deliberately wait after opening a doc to avoid triggering the browser's useless built in search; Discourse search has never really worked on slow devices or even not very fast but not particular slow devices).
In principle, these modern pages that burn a ton of CPU when loading could be doing pre-work that means that later interactions on the page are faster and cheaper than on the pages that do less up-front work (this is a common argument in favor of these kinds of pages), but that's not the case for pages tested, which are slower to load initially, slower on subsequent loads, and slower after they've loaded.
To understand why the theoretical idea that doing all this work up-front doesn't generally result in a faster experience later, this exchange between a distinguished engineer at Google and one of the founders of Discourse (and CEO at the time) is illustrative, in a discussion where the founder of Discourse says that you should test mobile sites on laptops with throttled bandwidth but not throttled CPU:
When someone asks the founder of Discourse, "just wondering why you hate them", he responds with a link that cites the Kraken and Octane benchmarks from this Anandtech review, which have the Qualcomm chip at 74% and 85% of the performance of the then-current Apple chip, respectively.
The founder and then-CEO of Discourse considers Qualcomm's mobile performance embarrassing and finds this so offensive that he thinks Qualcomm engineers should all lose their jobs for delivering 74% to 85% of the performance of Apple. Apple has what I consider to be an all-time great performance team. Reasonable people could disagree on that, but one has to at least think of them as a world-class team. So, producing a product with 74% to 85% of an all-time-great team is considered an embarrassment worthy of losing your job.
There are two attitudes on display here which I see in a lot of software folks. First, that CPU speed is infinite and one shouldn't worry about CPU optimization. And second, that gigantic speedups from hardware should be expected and the only reason hardware engineers wouldn't achieve them is due to spectacular incompetence, so the slow software should be blamed on hardware engineers, not software engineers. Donald Knuth expressed a similar sentiment in
I might as well flame a bit about my personal unhappiness with the current trend toward multicore architecture. To me, it looks more or less like the hardware designers have run out of ideas, and that they’re trying to pass the blame for the future demise of Moore’s Law to the software writers by giving us machines that work faster only on a few key benchmarks! I won’t be surprised at all if the whole multiithreading idea turns out to be a flop, worse than the "Itanium" approach that was supposed to be so terrific—until it turned out that the wished-for compilers were basically impossible to write. Let me put it this way: During the past 50 years, I’ve written well over a thousand programs, many of which have substantial size. I can’t think of even five of those programs that would have been enhanced noticeably by parallelism or multithreading. Surely, for example, multiple processors are no help to TeX ... I know that important applications for parallelism exist—rendering graphics, breaking codes, scanning images, simulating physical and biological processes, etc. But all these applications require dedicated code and special-purpose techniques, which will need to be changed substantially every few years. Even if I knew enough about such methods to write about them in TAOCP, my time would be largely wasted, because soon there would be little reason for anybody to read those parts ... The machine I use today has dual processors. I get to use them both only when I’m running two independent jobs at the same time; that’s nice, but it happens only a few minutes every week.
In the case of Discourse, a hardware engineer is an embarrassment not deserving of a job if they can't hit 90% of the performance of an all-time-great performance team but, as a software engineer, delivering 3% the performance of a non-highly-optimized application like MyBB is no problem. In Knuth's case, hardware engineers gave programmers a 100x performance increase every decade for decades with little to no work on the part of programmers. The moment this slowed down and programmers had to adapt to take advantage of new hardware, hardware engineers were "all out of ideas", but learning a few "new" (1970s and 1980s era) ideas to take advantage of current hardware would be a waste of time. And we've previously discussed Alan Kay's claim that hardware engineers are "unsophisticated" and "uneducated" and aren't doing "real engineering" and how we'd get a 1000x speedup if we listened to Alan Kay's "sophisticated" ideas.
It's fairly common for programmers to expect that hardware will solve all their problems, and then, when that doesn't happen, pass the issue onto the user, explaining why the programmer needn't do anything to help the user. A question one might ask is how much performance improvement programmers have given us. There are cases of algorithmic improvements that result in massive speedups but, as we noted above, Discourse, the fastest growing forum software today, seems to have given us an approximately 1000000x slowdown in performance.
Another common attitude on display above is the idea that users who aren't wealthy don't matter. When asked if 100% of users are on iOS, the founder of Discourse says "The influential users who spend money tend to be, I’ll tell you that". We see the same attitude all over comments on Tonsky's JavaScript Bloat post, with people expressing cocktail-party sentiments like "Phone apps are hundreds of megs, why are we obsessing over web apps that are a few megs? Starving children in Africa can download Android apps but not web apps? Come on" and "surely no user of gitlab would be poor enough to have a slow device, let's be serious" (paraphrased for length).
But when we look at the size of apps that are downloaded in Africa, we see that people who aren't on high-end devices use apps like Facebook Lite (a couple megs) and commonly use apps that are a single digit to low double digit number of megabytes. There are multiple reasons app makers care about their app size. One is just the total storage available on the phone; if you watch real users install apps, they often have to delete and uninstall things to put a new app on, so the smaller size is both easier to to install and has a lower chance of being uninstalled when the user is looking for more space. Another is that, if you look at data on app size and usage (I don't know of any public data on this; please pass it along if you have something public I can reference), when large apps increase the size and memory usage, they get more crashes, which drives down user retention, growth, and engagement and, conversely, when they optimize their size and memory usage, they get fewer crashes and better user retention, growth, and engagement.
Alex Russell points out that iOS has 7% market share in India (a 1.4B person market) and 6% market share in Latin America (a 600M person market). Although the founder of Discourse says that these aren't "influential users" who matter, these are still real human beings. Alex further points out that, according to Windows telemetry, which covers the vast majority of desktop users, most laptop/desktop users are on low-end machines which are likely slower than a modern iPhone.
On the bit about no programmers having slow devices, I know plenty of people who are using hand-me-down devices that are old and slow. Many of them aren't even really poor; they just don't see why (for example) their kid needs a super fast device, and they don't understand how much of the modern web works poorly on slow devices. After all, the "slow" device can play 3d games and (with the right OS) compile codebases like Linux or Chromium, so why shouldn't the device be able to interact with a site like gitlab?
Contrary to the claim from the founder of Discourse that, within years, every Android user will be on some kind of super fast Android device, it's been six years since his comment and it's going to be at least a decade before almost everyone in the world who's using a phone has a high-speed device and this could easily take two decades or more. If you look up marketshare stats for Discourse, it's extremely successful; it appears to be the fastest growing forum software in the world by a large margin. The impact of having the fastest growing forum software in the world created by an organization whose then-leader was willing to state that he doesn't really care about users who aren't "influential users who spend money", who don't have access to "infinite CPU speed", is that a lot of forums are now inaccessible to people who don't have enough wealth to buy a device with effectively infinite CPU.
If the founder of Discourse were an anomaly, this wouldn't be too much of a problem, but he's just verbalizing the implicit assumptions a lot of programmers have, which is why we see that so many modern websites are unusable if you buy the income-adjusted equivalent of a new, current generation, iPhone in a low-income country.
Thanks to Yossi Kreinen, Fabian Giesen, John O'Nolan, Joseph Scott, Loren McIntyre, Daniel Filan, @acidshill, Alex Russell, Chris Adams, Tobias Marschner, Matt Stuchlik, @[email protected], Justin Blank, Andy Kelley, Julian Lam, Matthew Thomas, avarcat, @[email protected], William Ehlhardt, Philip R. Boulain, and David Turner for comments/corrections/discussion.
We noted above that we used LCP* and not LCP. This is because LCP basically measures when the largest change happens. When this metric was not deliberately gamed in ways that don't benefit the user, this was a great metric, but this metric has become less representative of the actual user experience as more people have gamed it. In the less blatant cases, people do small optimizations that improve LCP but barely improve or don't improve the actual user experience.
In the more blatant cases, developers will deliberately flash a very large change on the page as soon as possible, generally a loading screen that has no value to the user (actually negative value because doing this increases the total amount of work done and the total time it takes to load the page) and then they carefully avoid making any change large enough that any later change would get marked as the LCP.
For the same reason that VW didn't publicly discuss how it was gaming its emissions numbers, developers tend to shy away from discussing this kind of LCP optimization in public. An exception to this is Discourse, where they publicly announced this kind of LCP optimization, with comments from their devs and the then-CTO (now CEO), noting that their new "Discourse Splash" feature hugely reduced LCP for sites after they deployed it. And then developers ask why their LCP is high, the standard advice from Discourse developers is to keep elements smaller than the "Discourse Splash", so that the LCP timestamp is computed from this useless element that's thrown up to optimize LCP, as opposed to having the timestamp be computed from any actual element that's relevant to the user. Here's a typical, official, comment from Discourse
If your banner is larger than the element we use for the "Introducing Discourse Splash - A visual preloader displayed while site assets load" you gonna have a bad time for LCP.
The official response from Discourse is that you should make sure that your content doesn't trigger the LCP measurement and that, instead, our loading animation timestamp is what's used to compute LCP.
The sites with the most extreme ratio of LCP of useful content vs. Chrome's measured LCP were:
M3: 6
M1: 12
Tecno Spark 8C: 3
Itel P32: N/A (FAIL)
M3: 10
M1: 12
Tecno Spark 8C: 4
Itel P32: N/A (FAIL)
Although we haven't discussed the gaming of other metrics, it appears that some websites also game other metrics and "optimize" them even when this has no benefit to users.
This will depend on the scale of the site as well as its performance, but when I've looked at this data for large companies I've worked for, improving site and app performance is worth a mind boggling amount of money. It's measurable in A/B tests and it's also among the interventions that has, in long-term holdbacks, a relatively large impact on growth and retention (many interventions test well but don't look as good long term, whereas performance improvements tend to look better long term).
Of course you can see this from the direct numbers, but you can also implicitly see this in a lot of ways when looking at the data. One angle is that (just for example), at Twitter, user-observed p99 latency was about 60s in India as well as a number of African countries (even excluding relatively wealthy ones like Egypt and South Africa) and also about 60s in the United States. Of course, across the entire population, people have faster devices and connections in the United States, but in every country, there are enough users that have slow devices or connections that the limiting factor is really user patience and not the underlying population-level distribution of devices and connections. Even if you don't care about users in Nigeria or India and only care about U.S. ad revenue, improving performance for low-end devices and connections has enough of impact that we could easily see the impact in global as well as U.S. revenue in A/B tests, especially in long-term holdbacks. And you also see the impact among users who have fast devices since a change that improves the latency for a user with a "low-end" device from 60s to 50s might improve the latency for a user with a high-end device from 5s to 4.5s, which has an impact on revenue, growth, and retention numbers as well.
For a variety of reasons that are beyond the scope of this doc, this kind of boring, quantifiable, growth and revenue driving work has been difficult to get funded at most large companies I've worked for relative to flash product work that ends up showing little to no impact in long-term holdbacks.
When using slow devices or any device with low bandwidth and/or poor connectivity, the best experiences, by far, are generally the ones that load a lot of content at once into a static page. If the images have proper width and height attributes and alt text, that's very helpful. Progressive images (as in progressive jpeg) isn't particularly helpful.
On a slow device with high bandwidth, any lightweight, static, page works well, and lightweight dynamic pages can work well if designed for performance. Heavy, dynamic, pages are doomed unless the page weight doesn't cause the page to be complex.
With low bandwidth and/or poor connectivity, lightweight pages are fine. With heavy pages, the best experience I've had is when I trigger a page load, go do something else, and then come back when it's done (or at least the HTML and CSS are done). I can then open each link I might want to read in a new tab, and then do something else while I wait for those to load.
A lot of the optimizations that modern websites do, such as partial loading that causes more loading when you scroll down the page, and the concomitant hijacking of search (because the browser's built in search is useless if the page isn't fully loaded) causes the interaction model that works to stop working and makes pages very painful to interact with.
Just for example, a number of people have noted that Substack performs poorly for them because it does partial page loads. Here's a video by @acidshill of what it looks like to load a Substack article and then scroll on an iPhone 8, where the post has a fairly fast LCP, but if you want to scroll past the header, you have to wait 6s for the next page to load, and then on scrolling again, you have to wait maybe another 1s to 2s:
As an example of the opposite approach, I tried loading some fairly large plain HTML pages, such as https://danluu.com/diseconomies-scale/ (0.1 MB wire / 0.4 MB raw) and https://danluu.com/threads-faq/ (0.4 MB wire / 1.1 MB raw) and these were still quite usable for me even on slow devices. 1.1 MB seems to be larger than optimal and breaking that into a few different pages would be better on a low-end devices, but a single page with 1.1 MB of text works much better than most modern sites on a slow device. While you can get into trouble with HTML pages that are so large that browsers can't really handle them, for pages with a normal amount of content, it generally isn't until you have complex CSS payloads or JS that the pages start causing problems for slow devices. Below, we test pages that are relatively simple, some of which have a fair amount of media (14 MB in one case) and find that these pages work ok, as long as they stay simple.
Chris Adams has also noted that blind users, using screen readers, often report that dynamic loading makes the experience much worse for them. Like dynamic loading to improve performance, while this can be done well, it's often either done badly or bundled with so much other complexity that the result is worse than a simple page.
@Qingcharles noted another accessibility issue — the (prison) parolees he works with are given "lifeline" phones, which are often very low end devices. From a quick search, in 2024, some people will get an iPhone 6 or an iPhone 8, but there are also plenty of devices that are lower end than an Itel P32, let alone a Tecno Spark 8C. They also get plans with highly limited data, and then when they run out, some people "can't fill out any forms for jobs, welfare, or navigate anywhere with Maps".
For sites that do up-front work and actually give you a decent experience on low end devices, Andy Kelley pointed out an example of a site that does up front work that seems to work ok on a slow device (although it would struggle on a very slow connection), the Zig standard library documentation:
I made the controversial decision to have it fetch all the source code up front and then do all the content rendering locally. In theory, this is CPU intensive but in practice... even those old phones have really fast CPUs!
On the Tecno Spark 8C, this uses 4.7s of CPU and, afterwards, is fairly responsive (relative to the device — of course an iPhone responds much more quickly. Taps cause links to load fairly quickly and scrolling also works fine (it's a little jerky, but almost nothing is really smooth on this device). This seems like the kind of thing people are referring to when they say that you can get better performance if you ship a heavy payload, but there aren't many examples of that which actually improve performance on low-end devices.
1.0 MB / 1.1 MB
Tecno Spark 8C: 0.9s / 1.4s
80 kB / 0.2 MB
Tecno Spark 8C: 0.8s / 0.7s
650 kB / 1.8 MB if you scroll through the entire page, but scrolling is only a little jerky and the lazy loading doesn't cause delays. Probably the only page I've tried that does lazy loading in a way that makes the experience better and not worse on a slow device; I didn't test on a slow connection, where this would still make the experience worse.Itel P32: 1.1s / 1s
1s for text to render when scrolling to new text; can be much worse with images that are lazy loaded. Even though this is the best implementation of lazy loading I've seen in the wild, the Itel P32 still can't handle it.14 kB / 57 kB
Tecno Spark 8C: 0.5s / 0.3s
Itel P32:0.7s / 0.5 s
82 kB / 0.1 MB
Tecno Spark 8C: 0.5s / 0.4s
Itel P32: 0.7s / 0.4s
14 MB / 14 MB
Tecno Spark 8C: 0.8s / 1.9s
Itel P32: 2.5s / 3s
1s for new content to appear when you scroll a significant distance.25 kB / 74 kB
Tecno Spark 8C: 0.6s / 0.5s
Itel P32: 1.3s / 1.1s
Itel P32 couldn't really handle.
Something I've observed over time, as programming has become more prestigious and more lucrative, is that people have tended to come from wealthier backgrounds and have less exposure to people with different income levels. An example we've discussed before, is at a well-known, prestigious, startup that has a very left-leaning employee base, where everyone got rich, on a discussion about the covid stimulus checks, in a slack discussion, a well meaning progressive employee said that it was pointless because people would just use their stimulus checks to buy stock. This person had, apparently, never talked to any middle-class (let alone poor) person about where their money goes or looked at the data on who owns equity. And that's just looking at American wealth. When we look at world-wide wealth, the general level of understanding is much lower. People seem to really underestimate the dynamic range in wealth and income across the world. From having talked to quite a few people about this, a lot of people seem to have mental buckets for "poor by American standards" (buys stock with stimulus checks) and "poor by worldwide standards" (maybe doesn't even buy stock), but the range of poverty in the world dwarfs the range of poverty in America to an extent that not many wealthy programmers seem to realize.
Just for example, in this discussion how lucky I was (in terms of financial opportunities) that my parents made it to America, someone mentioned that it's not that big a deal because they had great financial opportunities in Poland. For one thing, with respect to the topic of the discussion, the probability that someone will end up with a high-paying programming job (senior staff eng at a high-paying tech company) or equivalent, I suspect that, when I was born, being born poor in the U.S. gives you better odds than being fairly well off in Poland, but I could believe the other case as well if presented with data. But if we're comparing Poland v. U.S. to Vietnam v. U.S., if I spend 15 seconds looking up rough wealth numbers for these countries in the year I was born, the GDP/capita ratio of U.S. : Poland was ~8:1, whereas it was ~50 : 1 for Poland : Vietnam. The difference in wealth between Poland and Vietnam was roughly the square of the difference between the U.S. and Poland, so Poland to Vietnam is roughly equivalent to Poland vs. some hypothetical country that's richer than the U.S. by the amount that the U.S. is richer than Poland. These aren't even remotely comparable, but a lot of people seem to have this mental model that there's "rich countries" and "not rich countries" and "not rich countries" are all roughly in the same bucket. GDP/capita isn't ideal, but it's easier to find than percentile income statistics; the quick search I did also turned up that annual income in Vietnam then was something like $200-$300 a year. Vietnam was also going through the tail end of a famine whose impacts are a bit difficult to determine because statistics here seem to be gamed, but if you believe the mortality rate statistics, the famine caused total overall mortality rate to jump to double the normal baseline1.
Of course, at the time, the median person in a low-income country wouldn't have had a computer, let alone internet access. But, today it's fairly common for people in low-income countries to have devices. Many people either don't seem to realize this or don't understand what sorts of devices a lot of these folks use.
On the Discourse founder's comments on iOS vs. Android marketshare, Fabian notes
In the US, according to the most recent data I could find (for 2023), iPhones have around 60% marketshare. In the EU, it's around 33%. This has knock-on effects. Not only do iOS users skew towards the wealthier end, they also skew towards the US.
There's some secondary effects from this too. For example, in the US, iMessage is very popular for group chats etc. and infamous for interoperating very poorly with Android devices in a way that makes the experience for Android users very annoying (almost certainly intentionally so).
In the EU, not least because Android is so much more prominent, iMessage is way less popular and anecdotally, even iPhone users among my acquaintances who would probably use iMessage in the US tend to use WhatsApp instead.
Point being, globally speaking, recent iOS + fast Internet is even more skewed towards a particular demographic than many app devs in the US seem to be aware.
And on the comment about mobile app vs. web app sizes, Fabian said:
One more note from experience: apps you install when you install them, and generally have some opportunity to hold off on updates while you're on a slow or metered connection (or just don't have data at all).
Back when I originally got my US phone, I had no US credit history and thus had to use prepaid plans. I still do because it's fine for what I actually use my phone for most of the time, but it does mean that when I travel to Germany once a year, I don't get data roaming at all. (Also, phone calls in Germany cost me $1.50 apiece, even though T-Mobile is the biggest mobile provider in Germany - though, of course, not T-Mobile US.)
Point being, I do get access to free and fast Wi-Fi at T-Mobile hotspots (e.g. major train stations, airports etc.) and on inter-city trains that have them, but I effectively don't have any data plan when in Germany at all.
This is completely fine with mobile phone apps that work offline and sync their data when they have a connection. But web apps are unusable while I'm not near a public Wi-Fi.
Likewise I'm fine sending an email over a slow metered connection via the Gmail app, but I for sure wouldn't use any web-mail client that needs to download a few MBs worth of zipped JS to do anything on a metered connection.
At least with native app downloads, I can prepare in advance and download them while I'm somewhere with good internet!
Another comment from Fabian (this time paraphrased since this was from a conversation), is that people will often justify being quantitatively hugely slower because there's a qualitative reason something should be slow. One example he gave was that screens often take a long time to sync their connection and this is justified because there are operations that have to be done that take time. For a long time, these operations would often take seconds. Recently, a lot of displays sync much more quickly because Nvidia specifies how long this can take for something to be "G-Sync" certified, so display makers actually do this in a reasonable amount of time now. While it's true that there are operations that have to be done that take time, there's no fundamental reason they should take as much time as they often used to. Another example he gave was on how someone was justifying how long it took to read thousands of files because the operation required a lot of syscalls and "syscalls are slow", which is a qualitatively true statement, but if you look at the actual cost of a syscall, in the case under discussion, the cost of a syscall was many orders of magnitude from being costly enough to be a reasonable explanation for why it took so long to read thousands of files.
On this topic, when people point out that a modern website is slow, someone will generally respond with the qualitative defense that the modern website has these great features, which the older website is lacking. And while it's true that (for example) Discourse has features that MyBB doesn't, it's hard to argue that its feature set justifies being 33x slower.
With the exception of danluu.com and, arguably, HN, for each site, I tried to find the "most default" experience. For example, for WordPress, this meant a demo blog with the current default theme, twentytwentyfour. In some cases, this may not be the most likely thing someone uses today, e.g., for Shopify, I looked at the first thing that theme they give you when you browse their themes, but I didn't attempt to find theme data to see what the most commonly used theme is. For this post, I wanted to do all of the data collection and analysis as a short project, something that takes less than a day, so there were a number of shortcuts like this, which will be described below. I don't think it's wrong to use the first-presented Shopify theme in a decent fraction of users will probably use the first-presente theme, but that is, of course, less representative than grabbing whatever the most common theme is and then also testing many different sites that use that theme to see how real-world performance varies when people modify the theme for their own use. If I worked for Shopify or wanted to do competitive analysis on behalf of a competitor, I would do that, but for a one-day project on how large websites impact users on low-end devices, the performance of Shopify demonstrated here seems ok. I actually did the initial work for this around when I ran these polls, back in February; I just didn't have time to really write this stuff up for a month.
For the tests on laptops, I tried to have the laptop at ~60% battery, not plugged in, and the laptop was idle for enough time to return to thermal equilibrium in a room at 20°C, so pages shouldn't be impacted by prior page loads or other prior work that was happening on the machine.
For the mobile tests, the phones were at ~100% charge and plugged in, and also previously at 100% charge so the phones didn't have any heating effect you can get from rapidly charging. As noted above, these tests were formed with 1Gbps WiFi. No other apps were running, the browser had no other tabs open, and the only apps that were installed on the device, so no additional background tasks should've been running other than whatever users are normally subject to by the device by default. A real user with the same device is going to see worse performance than we measured here in almost every circumstance except if running Chrome Dev Tools on a phone significantly degrades performance. I noticed that, on the Itel P32, scrolling was somewhat jerkier with Dev Tools running than when running normally but, since this was a one-day project, I didn't attempt to quantify this and if it impacts some sites much more than others. In absolute terms, the overhead can't be all that large because the fastest sites are still fairly fast with Dev Tools running, but if there's some kind of overhead that's super-linear in the amount of work the site does (possibly indirectly, if it causes some kind of resource exhaustion), then that could be a problem in measurements of some sites.
Sizes were all measured on mobile, so in cases where different assets are loaded on mobile vs. desktop, the we measured the mobile asset sizes. CPU was measured as CPU time on the main thread (I did also record time on other threads for sites that used other threads, but didn't use this number; if CPU were a metric people wanted to game, time on other threads would have to be accounted for to prevent sites from trying to offload as much work as possible to other threads, but this isn't currently an issue and time on main thread is more directly correlated to usability than sum of time across all threads, and the metric that would work for gaming is less legible with no upside for now).
For WiFi speeds, speed tests had the following numbers:
M3 Max
850 Mbps
840 Mbps
3ms / 8ms
900 Mbps
840 Mbps
3ms / 8ms / 13ms
Tecno Spark 8C
390 Mbps
210 Mbps
2ms / 30ms
Itel P32
44 Mbps
4ms / 400ms
45 Mbps
One thing to note is that the Itel P32 doesn't really have the ability to use the bandwidth that it nominally has. Looking at the top Google reviews, none of them mention this. The first review reads
Performance-wise, the phone doesn’t lag. It is powered by the latest Android 8.1 (GO Edition) ... we have 8GB+1GB ROM and RAM, to run on a power horse of 1.3GHz quad-core processor for easy multi-tasking ... I’m impressed with the features on the P32, especially because of the price. I would recommend it for those who are always on the move. And for those who take battery life in smartphones has their number one priority, then P32 is your best bet.
Itel mobile is one of the leading Africa distributors ranking 3rd on a continental scale ... the light operating system acted up to our expectations with no sluggish performance on a 1GB RAM device ... fairly fast processing speeds ... the Itel P32 smartphone delivers the best performance beyond its capabilities ... at a whooping UGX 330,000 price tag, the Itel P32 is one of those amazing low-range like smartphones that deserve a mid-range flag for amazing features embedded in a single package.
"Much More Than Just a Budget Entry-Level Smartphone ... Our full review after 2 weeks of usage ... While switching between apps, and browsing through heavy web pages, the performance was optimal. There were few lags when multiple apps were running in the background, while playing games. However, the overall performance is average for maximum phone users, and is best for average users [screenshot of game] Even though the game was skipping some frames, and automatically dropped graphical details it was much faster if no other app was running on the phone.
Notes on sites:
LCP was misleading on every deviceTecno Spark 8C, scrolling never really works. It's very jerky and this never settles downItel P32, the page fails non-deterministically (different errors on different loads); it can take quite a while to error out; it was 23s on the first run, with the CPU pegged for 28s
Itel P32, this technically doesn't load correctly and could be marked as FAIL, but it's close enough that I counted it. The thing that's incorrect is that profile photos have a square box around then
LCP is highly gamed and basically meaningless. We linked to a post where the Discourse folks note that, on slow loads, they put a giant splash screen up at 2s to cap the LCP at 2s. Also notable is that, on loads that are faster than the 2s, the LCP is also highly gamed. For example, on the M3 Max with low-latency 1Gbps internet, the LCP was reported as 115ms, but the page loads actual content at 1.1s. This appears to use the same fundamental trick as "Discourse Splash", in that it paints a huge change onto the screen and then carefully loads smaller elements to avoid having the actual page content detected as the LCP.Tecno Spark 8C, scrolling is unpredictable and can jump too far, triggering loading from infinite scroll, which hangs the page for 3s-10s. Also, the entire browser sometimes crashes if you just let the browser sit on this page for a while.Itel P32, an error message is displayed after 7.5s
Itel P32
Itel P32, but the page appears to load and work, although interacting with it is fairly slow and painfulLCP on the Tecno Spark 8C was significantly before the page content actually loadedItel P32, but doesn't FAIL. The console shows that the JavaScript errors out, but the page still works fine (I tried scrolling, clicking links, etc., and these all worked), so you can actually go to the post you want and read it. The JS error appears to have made this page load much more quickly than it other would have and also made interacting with the page after it loaded fairly zippy.M3/10 run, Chrome dev tools reported a nonsensical 697s of CPU time (the run completed in a normal amount of time, well under 697s or even 697/10s. This run was ignored when computing results.Itel P32, the page load never completes and it just shows a flashing cursor-like image, which is deliberately loaded by the theme. On devices that load properly, the flashing cursor image is immediately covered up by another image, but that never happens here.LCP* compared to how long it takes for the page to become usable. Although not measured in this test, I generally find the page slow and sort of unusable on Intel Macbooks which are, by historical standards, extremely fast computers (unless I use old.reddit.com)Itel P32, just gives you a blank screen. Due to how long things generally take on the Itel P32, it's not obvious for a while if the page is failing or if it's just slowItel P32, the page stops executing scripts at some point and doesn't fully load. This causes it to fail to display properly. Interacting with the page doesn't really work either.Itel P32, I tried scrolling starting 35s after loading the page. The delay to scroll was 5s-8s and scrolling moved an unpredictable amount, making the page completely unusable. This wasn't marked as a FAIL in the table, but one could argue that this should be a FAIL since the page is unusable.Itel P32, the layout is badly wrong and page content overlaps itself. There's no reasonable way to interact with the element you want because of this, and reading the text requires reading text that's been overprinted multiple times.Itel P32 charged (the battery is in rough shape and discharges quite quickly once unplugged, so I'd have to wait quite a while to get it into a charged state)0.3s/0.4s on the M1 and 3.4s/7.2s on the Tecno Spark 8C. This is moderately slower than vBulletin and significantly slower than the faster php forums, but much faster than Discourse. If you need a "modern" forum for some reason and want to have your forum be usable by people who aren't, by global standards, rich, this seems like it could work.0.9 MB / 2.2 MB, so also fairly light for a "modern" site and possibly usable on a slow connection, although slow connections weren't tested here.Another kind of testing would be to try to configure pages to look as similar as possible. I'd be interested in seeing that results for that if anyone does it, but that test would be much more time consuming. For one thing, it requires customizing each site. And for another, it requires deciding what sites should look like. If you test something danluu.com-like, every platform that lets you serve up something light straight out of a CDN, like Wordpress and Ghost, should score similarly, with the score being dependent on the CDN and the CDN cache hit rate. Sites like Medium and Substack, which have relatively little customizability would score pretty much as they do here. Realistically, from looking at what sites exist, most users will create sites that are slower than the "most default" themes for Wordpress and Ghost, although it's plausible that readers of this blog would, on average, do the opposite, so you'd probably want to test a variety of different site styles.
Just as an aside, something I've found funny for a long time is that I get quite a bit of hate mail about the styling on this page (and a similar volume of appreciation mail). By hate mail, I don't mean polite suggestions to change things, I mean the equivalent of road rage, but for web browsing; web rage. I know people who run sites that are complex enough that they're unusable by a significant fraction of people in the world. How come people are so incensed about the styling of this site and, proportionally, basically don't care at all that the web is unusable for so many people?
Another funny thing here is that the people who appreciate the styling generally appreciate that the site doesn't override any kind of default styling, letting you make the width exactly what you want (by setting your window size how you want it) and it also doesn't override any kind of default styling you apply to sites. The people who are really insistent about this want everyone to have some width limit they prefer, some font they prefer, etc., but it's always framed in a way as if they don't want it, it's really for the benefit of people at large even though accommodating the preferences of the web ragers would directly oppose the preferences of people who prefer (just for example) to be able to adjust the text width by adjusting their window width.
Until I pointed this out tens of times, this iteration would usually start with web ragers telling me that "studies show" that narrower text width is objectively better, but on reading every study that exists on the topic that I could find, I didn't find this to be the case. Moreover, on asking for citations, it's clear that people saying this generally hadn't read any studies on this at all and would sometimes hastily send me a study that they did not seem to have read. When I'd point this out, people would then change their argument to how studies can't really describe the issue (odd that they'd cite studies in the first place), although one person cited a book to me (which I read and they, apparently, had not since it also didn't support their argument) and then move to how this is what everyone wants, even though that's clearly not the case, both from the comments I've gotten as well as the data I have from when I made the change.
Web ragers who have this line of reasoning generally can't seem to absorb the information that their preferences are not universal and will insist that they regardless of what people say they like, which I find fairly interesting. On the data, when I switched from Octopress styling (at the time, the most popular styling for programming bloggers) to the current styling, I got what appeared to be a causal increase in traffic and engagement, so it appears that not only do people who write me appreciation mail about the styling like the styling, the overall feeling of people who don't write to me appears to be that the site is fine and apparently more appealing than standard programmer blog styling. When I've noted this, people tend to become become further invested in the idea that their preferences are universal and that people who think they have other preferences are wrong and reply with total nonsense.
For me, two questions I'm curious about are why do people feel the need to fabricate evidence on this topic (referring to studies when they haven't read any, googling for studies and then linking to one that says the opposite of what they claim it says, presumably because they didn't really read it, etc.) in order to claim that there are "objective" reasons their preferences are universal or correct, and why are people so much more incensed by this than by the global accessibility problems caused by typical web design? On the latter, I suspect if you polled people with an abstract survey, they would rate global accessibility to be a larger problem, but by revealed preference both in terms of what people create as well as what irritates them enough to send hate mail, we can see that having fully-adjustable line width and not capping line width at their preferred length is important to do something about whereas global accessibility is not. As noted above, people who run sites that aren't accessible due to performance problems generally get little to no hate mail about this. And when I use a default Octopress install, I got zero hate mail about this. Fewer people read my site at the time, but my traffic volume hasn't increased by a huge amount since then and the amount of hate mail I get about my site design has gone from zero to a fair amount, an infinitely higher ratio than the increase in traffic.
To be clear, I certainly wouldn't claim that the design on this site is optimal. I just removed the CSS from the most popular blogging platform for programmers at the time because that CSS seemed objectively bad for people with low-end connections and, as a side effect, got more traffic and engagement overall, not just from locations where people tend to have lower end connections and devices. No doubt a designer who cares about users on low-end connections and devices could do better, but there's something quite odd about both the untruthfulness and the vitriol of comments on this.
2024-02-18 08:00:00
If I ask myself a question like "I'd like to buy an SD card; who do I trust to sell me a real SD card and not some fake, Amazon or my local Best Buy?", of course the answer is that I trust my local Best Buy1 more than Amazon, which is notorious for selling counterfeit SD cards. And if I ask who do I trust more, my local reputable electronics shop (Memory Express, B&H Photo, etc.), I trust my local reputable electronics shop more. Not only are they less likely to sell me a counterfeit than Best Buy, in the event that they do sell me a counterfeit, the service is likely to be better.
Similarly, let's say I ask myself a question like, "on which platform do I get a higher rate of scams, spam, fraudulent content, etc., [smaller platform] or [larger platform]"? Generally the answer is [larger platform]. Of course, there are more total small platforms out there and they're higher variance, so I could deliberately use a smaller platform that's worse, but I'm choosing good options instead of bad options, in every size class, the smaller platform is generally better. For example, with Signal vs. WhatsApp, I've literally never received a spam Signal message, whereas I get spam WhatsApp messages somewhat regularly. Or if I compare places I might read tech content on, if I compare tiny forums no one's heard of to lobste.rs, lobste.rs has a very slightly higher rate (rate as in fraction of messages I see, not absolute message volume) of bad content because it's zero on the private forums and very low but non-zero on lobste.rs. And then if I compare lobste.rs to a somewhat larger platform, like Hacker News or mastodon.social, those have (again very slightly) higher rates of scam/spam/fraudulent content. And then if I compare that to mid-sized social media platforms, like reddit, reddit has a significantly higher and noticeable rate of bad content. And then if I can compare reddit to the huge platforms like YouTube, Facebook, Google search results, these larger platforms have an even higher rate of scams/spam/fraudulent content. And, as with the SD card example, the odds of getting decent support go down as the platform size goes up as well. In the event of an incorrect suspension or ban from the platform, the odds of an account getting reinstated get worse as the platform gets larger.
I don't think it's controversial to say that in general, a lot of things get worse as platforms get bigger. For example, when I ran a Twitter poll to see what people I'm loosely connected to think, only 2.6% thought that huge company platforms have the best moderation and spam/fraud filtering. For reference, in one poll, 9% of Americans said that vaccines implant a microchip and and 12% said the moon landing was fake. These are different populations but it seems random Americans are more likely to say that the moon landing was faked than tech people are likely to say that the largest companies have the best anti-fraud/anti-spam/moderation.
However, over the past five years, I've noticed an increasingly large number of people make the opposite claim, that only large companies can do decent moderation, spam filtering, fraud (and counterfeit) detection, etc. We looked at one example of this when we examined search results, where a Google engineer said
Somebody tried argue that if the search space were more competitive, with lots of little providers instead of like three big ones, then somehow it would be *more* resistant to ML-based SEO abuse.
And... look, if *google* can't currently keep up with it, how will Little Mr. 5% Market Share do it?
And a thought leader responded
like 95% of the time, when someone claims that some small, independent company can do something hard better than the market leader can, it’s just cope. economies of scale work pretty well!
But when we looked at the actual results, it turned out that, of the search engines we looked at, Mr 0.0001% Market Share was the most resistant to SEO abuse (and fairly good), Mr 0.001% was a bit resistant to SEO abuse, and Google and Bing were just flooded with SEO abuse, frequently funneling people directly to various kinds of scams. Something similar happens with email, where I commonly hear that it's impossible to manage your own email due to the spam burden, but people do it all the time and often have similar or better results than Gmail, with the main problem being interacting with big company mail servers which incorrectly ban their little email server.
I started seeing a lot of comments claiming that you need scale to do moderation, anti-spam, anti-fraud, etc., around the time Zuckerberg, in response to Elizabeth Warren calling for the breakup of big tech companies, claimed that breaking up tech companies would make content moderation issues substantially worse, saying:
It’s just that breaking up these companies, whether it’s Facebook or Google or Amazon, is not actually going to solve the issues,” Zuckerberg said “And, you know, it doesn’t make election interference less likely. It makes it more likely because now the companies can’t coordinate and work together. It doesn’t make any of the hate speech or issues like that less likely. It makes it more likely because now ... all the processes that we’re putting in place and investing in, now we’re more fragmented
It’s why Twitter can’t do as good of a job as we can. I mean, they face, qualitatively, the same types of issues. But they can’t put in the investment. Our investment on safety is bigger than the whole revenue of their company. [laughter] And yeah, we’re operating on a bigger scale, but it’s not like they face qualitatively different questions. They have all the same types of issues that we do."
The argument is that you need a lot of resources to do good moderation and smaller companies, Twitter sized companies (worth ~$30B at the time), can't marshal the necessary resources to do good moderation. I found this statement quite funny at the time because, pre-Twitter acquisition, I saw a much higher rate of obvious scam content on Facebook than on Twitter. For example, when I clicked through Facebook ads during holiday shopping season, most were scams and, while Twitter had its share of scam ads, it wasn't really in the same league as Facebook. And it's not just me — Arturo Bejar, who designed an early version of Facebook's reporting system and headed up some major trust and safety efforts noticed something similar (see footnote for details)2.
Zuckerberg seems to like the line of reasoning mentioned above, though, as he's made similar arguments elsewhere, such as here, in a statement the same year that Meta's internal docs made the case that they were exposing 100k minors a day to sexual abuse imagery:
To some degree when I was getting started in my dorm room, we obviously couldn’t have had 10,000 people or 40,000 people doing content moderation then and the AI capacity at that point just didn’t exist to go proactively find a lot of harmful content. At some point along the way, it started to become possible to do more of that as we became a bigger business
The rhetorical sleight of hand here is the assumption that Facebook needed 10k or 40k people doing content moderation when Facebook was getting started in Zuckerberg's dorm room. Services that are larger than dorm-room-Facebook can and do have better moderation than Facebook today with a single moderator, often one who works part time. But as people talk more about pursuing real antitrust action against big tech companies, tech big tech founders and execs have ramped up the anti-antitrust rhetoric, making claims about all sorts of disasters that will befall humanity if the biggest companies are broken up into the size of the biggest tech companies of 2015 or 2010. This kind of reasoning seems to be catching on a bit, as I've seen more and more big company employees state very similar reasoning. We've come a long way since the 1979 IBM training manual which read
A COMPUTER CAN NEVER BE HELD ACCOUNTABLE
THEREFORE A COMPUTER MUST NEVER MAKE A MANAGEMENT DECISION
The argument is now, for many critical decisions, it is only computers that can make most of the decisions and the lack of accountability seems to ultimately a feature, not a bug.
But unfortunately for Zuckerberg's argument3, there are at least three major issues in play here where diseconomies of scale dominate. One is that, given material that nearly everyone can agree is bad (such as bitcoin scams, spam for fake pharmaceutical products, fake weather forecasts, adults sending photos of their genitals to children), etc., large platforms do worse than small ones. The second is that, for the user, errors are much more costly and less fixable as companies get bigger because support generally becomes worse. The third is that, as platforms scale up, a larger fraction of users will strongly disagree about what should be allowed on the platform.
With respect to the first, while it's true that big companies have more resources, the cocktail party idea that they'll have the best moderation because they have the most resources is countered by the equally simplistic idea that they'll have the worst moderation because they're the juiciest targets or that they'll have the worst moderation because they'll have worst fragmentation due to the standard diseconomies of scale that occur when you scale up organizations and problem domains. Whether or not the company having more resources or these other factors dominate is too complex to resolve theoretically, but can observe the result empirically. At least at the level of resources that big companies choose to devote to moderation, spam, etc., having the larger target and other problems associated with scale dominate.
While it's true that these companies are wildly profitable and could devote enough resources to significantly reduce this problem, they have chosen not to do this. For example, in the last year before I wrote this sentence, Meta's last-year profit before tax (through December 2023) was $47B. If Meta had a version of the internal vision statement of a power company a friend mine worked for ("Reliable energy, at low cost, for generations.") and operated like that power company did, trying to create a good experience for the user instead of maximizing profit plus creating the metaverse, they could've spent the $50B they spent on the metaverse on moderation platforms and technology and then spent $30k/yr (which would result in a very good income in most countries where moderators are hired today, allowing them to have their pick of who to hire) on 1.6 million additional full-time staffers for things like escalations and support, on the order of one additional moderator or support staffer per few thousand users (and of course diseconomies of scale apply to managing this many people). I'm not saying that Meta or Google should do this, just that whenever someone at big tech company says something like "these systems have to be fully automated because no one could afford to operate manual systems at our scale", what's really being said is more along the lines of "we would not be able to generate as many billions a year in profit if we hired enough competent people to manually review cases our system should flag as ambiguous, so we settle for what we can get without compromising profits".4 One can defend that choice, but it is a choice.
And likewise for claims about advantages of economies of scale. There are areas where economies of scale legitimately make the experience better for users. For example, when we looked at why it's so hard to buy things that work well, we noted that Amazon's economies of scale have enabled them to build out their own package delivery service that is, while flawed, still more reliable than is otherwise available (and this has only improved since they added the ability for users to rate each delivery, which no other major package delivery service has). Similarly, Apple's scale and vertical integration has allowed them to build one of the all-time great performance teams (as measured by normalized performance relative to competitors of the same era), not only wiping the floor with the competition on benchmarks, but also providing a better experience in ways that no one really measured until recently, like device latency. For a more mundane example of economies of scale, crackers and other food that ships well are cheaper on Amazon than in my local grocery store. It's easy to name ways in which economies of scale benefit the user, but this doesn't mean that we should assume that economies of scale dominate diseconomies of scale in all areas. Although it's beyond the scope of this post, if we're going to talk about whether or not users are better off if companies are larger or smaller, we should look at what gets better when companies get bigger and what gets worse, not just assume that everything will get better just because some things get better (or vice versa).
Coming back to the argument that huge companies have the most resources to spend on moderation, spam, anti-fraud, etc., vs. the reality that they choose to spend those resources elsewhere, like dropping $50B on the Metaverse and not hiring 1.6 million moderators and support staff that they could afford to hire, it makes sense to look at how much effort is being expended. Meta's involvement in Myanmar makes for a nice case study because Erin Kissane wrote up a fairly detailed 40,000 word account of what happened. The entirety of what happened is a large and complicated issue (see appendix for more discussion) but, for the main topic of this post, the key components are that there was an issue that most people can generally agree should be among the highest priority moderation and support issues and that, despite repeated, extremely severe and urgent, warnings to Meta staff at various levels (engineers, directors, VPs, execs, etc.), almost no resources were dedicated to the issue while internal documents indicate that only a small fraction of agreed-upon bad content was caught by their systems (on the order of a few percent). I don't think this is unique to Meta and this matches my experience with other large tech companies, both as a user of their products and as an employee.
To pick a smaller scale example, an acquaintance of mine had their Facebook account compromised and it's now being used for bitcoin scams. The person's name is Samantha K. and some scammer is doing enough scamming that they didn't even bother reading her name properly and have been generating very obviously faked photos where someone holds up a sign and explains how "Kamantha" has helped them make tens or hundreds of thousands of dollars. This is a fairly common move for "hackers" to make and someone else I'm connected to on FB reported that this happened to their account and they haven't been able to recover the old account or even get it banned despite the constant stream of obvious scams being posted by the account.
By comparison, on lobste.rs, I've never seen a scam like this and Peter Bhat Harkins, the head mod says that they've never had one that he knows of. On Mastodon, I think I might've seen one once in my feed, replies, or mentions. Of course, Mastodon is big enough that you can find some scams if you go looking for them, but the per-message and per-user rates are low enough that you shouldn't encounter them as a normal user. On Twitter (before the acquisition) or reddit, moderately frequently, perhaps an average of once every few weeks in my normal feed. On Facebook, I see things like this all the time; I get obvious scam consumer good sites every shopping season, and the bitcoin scams, both from ads as well as account takeovers, are year-round. Many people have noted that they don't bother reporting these kinds of scams anymore because they've observed that Facebook doesn't take action on their reports. Meanwhile, Reuven Lerner was banned from running Facebook ads on their courses about Python and Pandas, seemingly because Facebook systems "thought" that Reuven was advertising something to do with animal trading (as opposed to programming). This is the fidelity of moderation and spam control that Zuckerberg says cannot be matched by any smaller company. By the way, I don't mean to pick on Meta in particular; if you'd like examples with a slightly different flavor, you can see the appendix of Google examples for a hundred examples of automated systems going awry at Google.
A reason this comes back to being an empirical question is that all of this talk about how economies of scale allows huge companies to bring more resources to bear on the problem on matters if the company chooses to deploy those resources. There's no theoretical force that makes companies deploy resources in these areas, so we can't reason theoretically. But we can observe that the resources deployed aren't sufficient to match the problems, even in cases where people would generally agree that the problem should very obviously be high priority, such as with Meta in Myanmar. Of course, when it comes to issues where the priority is less obvious, resources are also not deployed there.
On the second issue, support, it's a meme among tech folks that the only way to get support as a user of one of the big platforms is to make a viral social media post or know someone on the inside. This compounds the issue of bad moderation, scam detection, anti-fraud, etc., since those issues could be mitigated if support was good.
Normal support channels are a joke, where you either get a generic form letter rejection, or a kafkaesque nightmare followed by a form letter rejection. For example, when Adrian Black was banned from YouTube for impersonating Adrian Black (to be clear, he was banned for impersonating himself, not someone else with the same name), after appealing, he got a response that read
unfortunately, there's not more we can do on our end. your account suspension & appeal were very carefully reviewed & the decision is final
accounting data exports for extensions have been broken for me (and I think all extension merchants?) since April 2018 [this was written on Sept 2020]. I had to get the NY attorney general to write them a letter before they would actually respond to my support requests so that I could properly file my taxes
There was also the time YouTube kept demonetizing PointCrow's video of eating water with chopsticks (he repeatedly dips chopsticks into water and then drinks the water, very slowly eating a bowl of water).
Despite responding with things like
we're so sorry about that mistake & the back and fourth [sic], we've talked to the team to ensure it doesn't happen again
He would get demonetized again and appeals would start with the standard support response strategy of saying that they took great care in examining the violating under discussion but, unfortunately, the user clearly violated the policy and therefore nothing can be done:
We have reviewed your appeal ... We reviewed your content carefully, and have confirmed that it violates our violent or graphic content policy ... it's our job to make sure that YouTube is a safe place for all
These are high-profile examples, but of course having a low profile doesn't stop you from getting banned and getting the same basically canned response, like this HN user who was banned for selling a vacuum in FB marketplace. After a number of appeals, he was told
Unfortunately, your account cannot be reinstated due to violating community guidelines. The review is final
When paid support is optional, people often say you won't have these problems if you pay for support, but people who use Google One paid support or Facebook and Instagram's paid creator support generally report that the paid support is no better than the free support. Products that effectively have paid support built-in aren't necessarily better, either. I know people who've gotten the same kind of runaround you get from free Google support with Google Cloud, even when they're working for companies that have 8 or 9 figure a year Google Cloud spend. In one of many examples, the user was seeing that Google must've been dropping packets and Google support kept insisting that the drops were happening in the customer's datacenter despite packet traces showing that this could not possibly be the case. The last I heard, they gave up on that one, but sometimes when an issue is a total showstopper, someone will call up a buddy of theirs at Google to get support because the standard support is often completely ineffective. And this isn't unique to Google — at another cloud vendor, a former colleague of mine was in the room for a conversation where a very senior engineer was asked to look into an issue where a customer was complaining that they were seeing 100% of packets get dropped for a few seconds at a time, multiple times an hour. The engineer responded with something like "it's the cloud, they should deal with it", before being told they couldn't ignore the issue as usual because the issue was coming from [VIP customer] and it was interrupting [one of the world's largest televised sporting events]. That one got fixed, but, odds are, you aren't that important, even if you're paying hundreds of millions a year.
And of course this kind of support isn't unique to cloud vendors. For example, there was this time Stripe held $400k from a customer for over a month without explanation, and every request to support got a response that was as ridiculous as the ones we just looked at. The user availed themself of the only reliable Stripe support mechanism, posting to HN and hoping to hit #1 on the front page, which worked, although many commenters said made the usual comments like "Flagged because we are seeing a lot of these on HN, and they seem to be attempts to fraudulently manipulate customer support, rather than genuine stories", with multiple people suggesting or insinuating that the user is doing something illicit or fraudulent, but it turned out that it was an error on Stripe's end, compounded by Stripe's big company support. At one point, the user notes
While I was writing my HN post I was also on chat with Stripe for over an hour. No new information. They were basically trying to shut down the chat with me until I sent them the HN story and showed that it was getting some traction. Then they started working on my issue again and trying to communicate with more people
And then the issue was fixed the next day.
Although, in principle, as companies become larger, they could leverage their economies of scale to deliver more efficient support, instead, they tend to use their economies of scale to deliver worse, but cheaper and more profitable support. For example, on Google Play store approval support, a Google employee notes:
a lot of that was outsourced to overseas which resulted in much slower response time. Here stateside we had a lot of metrics in place to fast response. Typically your app would get reviewed the same day. Not sure what it's like now but the managers were incompetent back then even so
And a former FB support person notes:
The big problem here is the division of labor. Those who spend the most time in the queues have the least input as to policy. Analysts are able to raise issues to QAs who can then raise them to Facebook FTEs. It can take months for issues to be addressed, if they are addressed at all. The worst part is that doing the common sense thing and implementing the spirit of the policy, rather than the letter, can have a negative effect on your quality score. I often think about how there were several months during my tenure when most photographs of mutilated animals were allowed on a platform without a warning screen due to a carelessly worded policy "clarification" and there was nothing we could do about it.
If you've ever wondered why your support person is responding nonsensically, sometimes it's the obvious reason that support has been outsourced to someone making $1/hr (when I looked up the standard rates for one country that a lot of support is outsourced to, a fairly standard rate works out to about $1/hr) who doesn't really speak your language and is reading from a flowchart without understanding anything about the system they're giving support for, but another, less obvious, reason is that the support person may be penalized and eventually fired if they take actions that make sense instead of following the nonsensical flowchart that's in front of them.
Coming back to the "they seem to be attempts to fraudulently manipulate customer support, rather than genuine stories" comment, this is a sentiment I've commonly seen expressed by engineers at companies that mete out arbitrary and capricious bans. I'm sympathetic to how people get here. As I noted before I joined Twitter, commenting on public information
Turns out twitter is removing ~1M bots/day. Twitter only has ~300M MAU, making the error tolerance v. low. This seems like a really hard problem ... Gmail's spam filter gives me maybe 1 false positive per 1k correctly classified ham ... Regularly wiping the same fraction of real users in a service would be [bad].
It is actually true that, if you, an engineer, dig into the support queue at some giant company and look at people appealing bans, almost all of the appeals should be denied. But, my experience from having talked to engineers working on things like anti-fraud systems is that many, and perhaps most, round "almost all" to "all", which is both quantitatively and qualitatively different. Having engineers who work on these systems believe that "all" and not "almost all" of their decisions are correct results in bad experiences for users.
For example, there's a social media company that's famous for incorrectly banning users (at least 10% of people I know have lost an account due to incorrect bans and, if I search for a random person I don't know, there's a good chance I get multiple accounts for them, with some recent one that has a profile that reads "used to be @[some old account]", with no forward from the old account to the new one because they're now banned). When I ran into a senior engineer from the team that works on this stuff, I asked him why so many legitimate users get banned and he told me something like "that's not a problem, the real problem is that we don't ban enough accounts. Everyone who's banned deserves it, it's not worth listening to appeals or thinking about them". Of course it's true that most content on every public platform is bad content, spam, etc., so if you have any sort of signal at all on whether or not something is bad content, when you look at it, it's likely to be bad content. But this doesn't mean the converse, that almost no users are banned incorrectly, is true. And if senior people on the team that classifies which content is bad have the attitude that we shouldn't worry about false positives because almost all flagged content is bad, we'll end up with a system that has a large number of false positives. I later asked around to see what had ever been done to reduce false positives in the fraud detection systems and found out that there was no systematic attempt at tracking false positives at all, no way to count cases where employees filed internal tickets to override bad bans, etc.; At the meta level, there was some mechanism to decrease the false negative rate (e.g., someone sees bad content that isn't being caught then adds something to catch more bad content) but, without any sort of tracking of false positives, there was effectively no mechanism to decrease the false positive rate. It's no surprise that this meta system resulted in over 10% of people I know getting incorrect suspensions or bans. And, as Patrick McKenzie says, the optimal rate of false positives isn't zero. But when you have engineers who have the attitude that they've done enough legwork that false positives are impossible, it's basically guaranteed that the false positive rate is higher than optimal. When you combine this with normal big company levels of support, it's a recipe for kafkaesque user experiences.
Another time, I commented on how an announced change in Uber's moderation policy seemed likely to result in false positive bans. An Uber TL immediately took me to task, saying that I was making unwarranted assumptions on how banning works, that Uber engineers go to great lengths to make sure that there are no false positive bans, there's extensive to review to make sure that bans are valid and, in fact, the false positive banning I was concerned about could never happen. And then I got effectively banned due to a false positive in a fraud detection system. I was remind of that incident when Uber incorrectly banned a driver who had to take them to court to even get information on why he was banned, at which point Uber finally actually looked into it (instead of just responding to appeals with fake messages claiming they'd looked into it). Afterwards, Uber responded to a press inquiry with
We are disappointed that the court did not recognize the robust processes we have in place, including meaningful human review, when making a decision to deactivate a driver’s account due to suspected fraud
Of course, in that driver's case, there was no robust process for review, nor was there a robust appeals process for my case. When I contacted support, they didn't really read my message and made some change that broke my account even worse than before. Luckily, I have enough Twitter followers that some Uber engineers saw my tweet about the issue and got me unbanned, but that's not an option that's available to most people, leading to weird stuff like this Facebook ad targeted at Google employees, from someone desperately seeking help with their Google account.
And even when you know someone on the inside, it's not always easy to get the issue fixed because even if the company's effectiveness doesn't increase as the company gets bigger, the complexity of the systems does increase. A nice example of this is Gergely Orosz's story about when the manager of the payments team left Uber and then got banned from Uber due to some an inscrutable ML anti-fraud algorithm deciding that the former manager of the payments team was committing payments fraud. It took six months of trying to get the problem fixed to mitigate the issue. And, by the way, they never managed to understand what happened and fix the underlying issue; instead, they added the former manager of the payments team to a special whitelist, not fixing the issue for any other user and, presumably, severely reducing or perhaps even entirely removing payment fraud protections for the former manager's account.
No doubt they would've fixed the underlying issue if it were easy to, but as companies scale up, they produce both technical and non-technical bureaucracy that makes systems opaque even to employees.
Another example of that is, at a company that has a ranked social feed, the idea that you could eliminate stuff you didn't want in your ranked feed by adding filters for things like timeline_injection:false, interstitial_ad_op_out, etc., would go viral. The first time this happened, a number of engineers looked into it and thought that the viral tricks didn't work. They weren't 100% sure and were relying on ideas like "no one can recall a system that would do something like this ever being implemented" and "if you search the codebase for these strings, they don't appear", and "we looked at the systems we think might do this and they don't appear to do this". There was moderate confidence that this trick didn't work, but no one would state with certainty that the trick didn't work because, as at all large companies, the aggregate behavior of the system is beyond human understanding and even parts that could be understood often aren't because there are other priorities.
A few months later, the trick went viral again and people were generally referred to the last investigation when they asked if it was real, except that one person actually tried the trick and reported that it worked. They wrote a slack message about how the trick did work for them, but almost no one noticed that the one person who tried reproducing the trick found that it worked. Later, when the trick would go viral again, people would point to the discussions about how people thought the trick didn't work, with this message noting that it appears to work (almost certainly not by the mechanism that users think, and instead just because having a long list of filters causes something to time out, or something similar) basically got lost because there's too much information to read all of it.
In my social circles, many people have read James Scott's Seeing Like a State, which is subtitled How Certain Schemes to Improve the Human World Have Failed. A key concept from the book is "legibility", what a state can see, and how this distorts what states do. One could easily write a highly analogous book, Seeing like a Tech Company about what's illegible to companies that scale up, at least as companies are run today. A simple example of this is that, in many video games, including ones made by game studios that are part of a $3T company, it's easy to get someone suspended or banned by having a bunch of people report the account for bad behavior. What's legible to the game company is the rate of reports and what's not legible is the player's actual behavior (it could be legible, but the company chooses not to have enough people or skilled enough people examine actual behavior); and many people have reported similar bannings with social media companies. When it comes to things like anti-fraud systems, what's legible to the company tends to be fairly illegible to humans, even humans working on the anti-fraud systems themselves.
Although he wasn't specifically talking about an anti-fraud system, in a Special Master's System, Eugene Zarashaw, a director a Facebook made this comment which illustrates the illegibility of Facebook's own systems:
It would take multiple teams on the ad side to track down exactly the — where the data flows. I would be surprised if there’s even a single person that can answer that narrow question conclusively
Facebook was unfairly and mostly ignorantly raked over the coals for this statement (we'll discuss that in an appendix), but it is generally true that it's difficult to understand how a system the size of Facebook works.
In principle, companies could augment the legibility of their inscrutable systems by having decently paid support people look into things that might be edge-case issues with severe consequences, where the system is "misunderstanding" what's happening but, in practice, companies pay these support people extremely poorly and hire people who really don't understand what's going on, and then give them instructions which ensure that they generally do not succeed at resolving legibility issues.
One thing that helps the forces of illegibility win at scale is that, as a highly-paid employee of one of these huge companies, it's easy to look at the millions or billions of people (and bots) out there and think of them all as numbers. As the saying goes, "the death of one man is a tragedy. The death of a million is a statistic" and, as we noted, engineers often turn thoughts like "almost all X is fraud" to "all X is fraud, so we might as well just ban everyone who does X and not look at appeals". The culture that modern tech companies have, of looking for scalable solutions at all costs, makes this worse than in other industries even at the same scale, and tech companies also have unprecedented scale.
For example, in response to someone noting that FB Ad Manager claims you can run an ad with a potential reach of 101M people in the U.S. aged 18-34 when the U.S. census had the total population of people aged 18-34 as 76M, the former PM of the ads targeting team responded with
Think at FB scale
And explained that you can't expect slice & dice queries to work for something like the 18-34 demographic in the U.S. at "FB scale". There's a meme at Google that's used ironically in cases like this, where people will say "I can't count that low". Here's the former PM of FB ads saying, non-ironically, "FB can't count that low" for numbers like 100M. Not only does FB not care about any individual user (unless they're famous), this PM claims they can't be bothered to care that groups of 100M people are tracked accurately.
Coming back to the consequences of poor support, a common response to hearing about people getting incorrectly banned from one of these huge services is "Good! Why would you want to use Uber/Amazon/whatever anyway? They're terrible and no one should use them". I disagree with this line of reasoning. For one thing, why should you decide for that person whether or not they should use a service or what's good for them? For another (and this this is a large enough topic that it should be its own post, so I'll just mention it briefly and link to this lengthier comment from @whitequark) most services that people write off as unnecessary conveniences that you should just do without are actually serious accessibility issues for quite a few people (in absolute, not necessarily, percentage, terms). When we're talking about small businesses, those people can often switch to another business, but with things like Uber and Amazon, there are sometimes zero or one alternatives that offer similar convenience and when there's one, getting banned due to some random system misfiring can happen with the other service as well. For example, in response to many people commenting on how you should just issue a chargeback and get banned from DoorDash when they don't deliver, a disabled user responds:
I'm disabled. Don't have a driver's license or a car. There isn't a bus stop near my apartment, I actually take paratransit to get to work, but I have to plan that a day ahead. Uber pulls the same shit, so I have to cycle through Uber, Door dash, and GrubHub based on who has coupons and hasn't stolen my money lately. Not everyone can just go pick something up.
Also, when talking about this class of issue, involvement is often not voluntary, such as in the case of this Fujitsu bug that incorrectly put people in prison.
On the third issue, the impossibility of getting people to agree on what constitutes spam, fraud, and other disallowed content, we discussed that in detail here. We saw that, even in a trivial case with a single, uncontroversial, simple, rule, people can't agree on what's allowed. And, as you add more rules or add topics that are controversial or scale up the number of people, it becomes even harder to agree on what should be allowed.
To recap, we looked at three areas where diseconomies of scale make moderation, support, anti-fraud, and anti-spam worse as companies get bigger. The first was that, even in cases where there's broad agreement that something is bad, such as fraud/scam/phishing websites and search, the largest companies with the most sophisticated machine learning can't actually keep up with a single (albeit very skilled) person working on a small search engine. The returns to scammers are much higher if they take on the biggest platforms, resulting in the anti-spam/anti-fraud/etc. problem being extremely non-linearly hard.
To get an idea of the difference in scale, HN "hellbans" spammers and people who post some kinds of vitriolic comments. Most spammers don't seem to realize they're hellbanned and will keep posting for a while, so if you browse the "newest" (submissions) page while logged in, you'll see a steady stream of automatically killed stories from these hellbanned users. While there are quite a few of them, the percentage is generally well under half. When we looked at a "mid-sized" big tech company like Twitter circa 2017, based on the public numbers, if spam bots were hellbanned instead of removed, spam is so much more prevalent that all you'd see if you were able to see it. And, as big companies go, 2017-Twitter isn't that big. As we also noted, the former PM of FB ads targeting explained that numbers as low as 100M are in the "I can't count that low" range, too small to care about; to him, basically a rounding error. The non-linear difference in difficulty is much worse for a company like FB or Google. The non-linearity of the difficulty of this problems is, apparently, more than a match for whatever ML or AI techniques Zuckerberg and other tech execs want to brag about.
In testimony in front of Congress, you'll see execs defend the effectiveness of these systems at scale with comments like "we can identify X with 95% accuracy", a statement that may technically be correct, but seems designed to deliberately mislead an audience that's presumed to be innumerate. If you use, as a frame of reference, things at a personal scale, 95% might sound quite good. Even for something like HN's scale, 95% accurate spam detection that results in an immediate ban might be sort of alright. Anyway, even if it's not great, people who get incorrectly banned can just email Dan Gackle, who will unban them. As we noted when we looked at the numbers, 95% accurate detection at Twitter's scale would be horrible (and, indeed, the majority of DMs I get are obvious spam). Either you have to back off and only ban users in cases where you're extremely confident, or you ban all your users after not too long and, as companies like to handle support, appealing means that you'll get a response saying that "your case was carefully reviewed and we have determined that you've violated our policies. This is final", even for cases where any sort of cursory review would cause a reversal of the ban, like when you ban a user for impersonating themselves. And then at FB's scale, it's even worse and you'll ban all of your users even more quickly, so then you back off and we end up with things like 100k minors a day being exposed to "photos of adult genitalia or other sexually abusive content".
The second area we looked at was support, which tends to get worse as companies get larger. At a high level, it's fair to say that companies don't care to provide decent support (with Amazon being somewhat of an exception here, especially with AWS, but even on the consumer side). Inside the system, there are individuals who care, but if you look at the fraction of resources expended on support vs. growth or even fun/prestige projects, support is an afterthought. Back when deepmind was training a StarCraft AI, it's plausible that Alphabet was spending more money playing Starcraft than on support agents (and, if not, just throw in one or two more big AI training projects and you'll be there, especially if you include the amortized cost of developing custom hardware, etc.).
It's easy to see how little big companies care. All you have to do is contact support and get connected to someone who's paid $1/hr to respond to you in a language they barely know, attempting to help solve a problem they don't understand by walking through some flowchart, or appeal an issue and get told "after careful review, we have determined that you have [done the opposite of what you actually did]". In some cases, you don't even need to get that far, like when following Instagram's support instructions results in an infinite loop that takes you back where you started and the "click here if this wasn't you link returns a 404". I've run into an infinite loop like this once, with Verizon, and it persisted for at least six months. I didn't check after that, but I'd bet on it persisting for years. If you had an onboarding or sign-up page that had an issue like this, that would be considered a serious bug that people should prioritize because that impacts growth. But for something like account loss due to scammers taking over accounts, that might get fixed after months or years. Or maybe not.
If you ever talk to people who work in support at a company that really cares about support, it's immediately obvious that they operate completely different from typical big tech company support, in terms of process as well as culture. Another way you can tell that big companies don't care about support is how often big company employees and execs who've never looked into how support is done or could be done will tell you that it's impossible to do better.
When you talk to people who work on support at companies that do actually care about this, it's apparent that it can be done much better. While I was writing this post, I actually did support at a company that does support decently well (for a tech company, adjusted for size, I'd say they're well above 99%-ile), including going through the training and onboarding process for support folks. Executing anything well at scale is non-trivial, so I don't mean to downplay how good their support org is, but the most striking thing to me was how much of the effectiveness of the org naturally followed from caring about providing a good support experience for the user. A full discussion of what that means is too long to include here, so we'll look at this in more detail another time, but one example is that, when we look at how big company support responds, it's often designed to discourage the user from responding ("this review is final") or to justify, putatively to the user, that the company is doing an adequate job ("this was not a purely automated process and each appeal was reviewed by humans in a robust process that ... "). This company's training instructs you to do the opposite of the standard big company "please go away"-style and "we did a great job and have a robust process, therefore complaints are invalid"-style responses. For every anti-pattern you commonly see in support, the training tells you to do the opposite and discusses why the anti-pattern results in a bad user experience. Moreover, the culture has deeply absorbed these ideas (or rather, these ideas come out of the culture) and there are processes for ensuring that people really know what it means to provide good support and follow through on it, support folks have ways to directly talk to the developers who are implementing the product, etc.
If people cared about doing good support, they could talk to people who work in support orgs that are good at helping users or even try working in one before explaining how it's impossible to do better, but this generally isn't done. Their company's support org leadership could do this as well, or do what I did and actually directly work in a support role in an effective support org, but this doesn't happen. If you're a cynic, this all makes sense. In the same way that cynics advise junior employees "big company HR isn't there to help you; their job is to protect the company", a cynic can credibly argue "big company support isn't there to help the user; their job is to protect the company", so of course big companies don't try to understand how companies that are good at supporting users do support because that's not what big company support is for.
The third area we looked at was how it's impossible for people to agree on how a platform should operate and how people's biases mean that people don't understand how difficult a problem this is. For Americans, a prominent case of this are the left and right wing conspiracy theories that pop up every time some bug pseudo-randomly causes any kind of service disruption or banning.
In a tweet, Ryan Greeberg joked:
Come work at Twitter, where your bugs TODAY can become conspiracy theories of TOMORROW!
In my social circles, people like to make fun of all of the absurd right-wing conspiracy theories that get passed around after some bug causes people to incorrectly get banned, causes the site not to load, etc., or even when some new ML feature correctly takes down a huge network of scam/spam bots, which also happens to reduce the follower count of some users. But of course this isn't unique to the right, and left-wing thought leaders and politicians come up with their own conspiracy theories as well.
Putting all three of these together, worse detection of issues, worse support, and a harder time reaching agreement on policies, we end with the situation we noted at the start where, in a poll of my Twitter followers, people who mostly work in tech and are generally fairly technically savvy, only 2.6% of people thought that the biggest companies were the best at moderation and spam/fraud filtering, so it might seem a bit silly to spend so much time belaboring the point. When you sample the U.S population at large, a larger fraction of people say they believe in conspiracy theories like vaccines putting a microchip in you or that we never landed on the moon, and I don't spend my time explaining why vaccines do not actually put a microchip in you or why it's reasonable to think that we landed on the moon. One reason that would perhaps be reasonable is that I've been watching the "only big companies can handle these issues" rhetoric with concern as it catches on among non-technical people, like regulators, lawmakers, and high-ranking government advisors, who often listen to and then regurgitate nonsense. Maybe next time you run into a lay person who tells you that only the largest companies could possibly handle these issues, you can politely point out that there's very strong consensus the other way among tech folks5.
If you're a founder or early-stage startup looking for an auth solution, PropelAuth is targeting your use case. Although they can handle other use cases, they're currently specifically trying to make life easier for pre-launch startups that haven't invested in an auth solution yet. Disclaimer: I'm an investor
Thanks to Gary Bernhardt, Peter Bhat Harkins, Laurence Tratt, Dan Gackle, Sophia Wisdom, David Turner, Yossi Kreinin, Justin Blank, Ben Cox, Horace He, @borzhemsky, Kevin Burke, Bert Muthalaly, Sasuke, anonymous, Zach Manson, Joachim Schipper, Tony D'Souza, and @GL1zdA for comments/corrections/discussion.
This post has focused on the disadvantages of bigness, but we can also flip this around and look at the advantages of smallness.
As mentioned, the best experiences I've had on platforms are a side effect of doing things that don't scale. One thing that can work well is to have a single person, with a single vision, handling the entire site or, when that's too big, a key feature of the site.
I'm on a number of small discords that have good discussion and essentially zero scams, spam, etc. The strategy for this is simple; the owner of the channel reads every message and bans and scammers or spammers who show up. When you get to a bigger site, like lobste.rs, or even bigger like HN, that's too large for someone to read every message (well, this could be done for lobste.rs, but considering that it's a spare-time pursuit for the owner and the volume of messages, it's not reasonable to expect them to read every message in a short timeframe), but there's still a single person who provides the vision for what should happen, even if the sites are large enough that it's not reasonable to literally read every message. The "no vehicles in the park" problem doesn't apply here because a person decides what the policies should be. You might not like those policies, but you're welcome to find another small forum or start your own (and this is actually how lobste.rs got started — under HN's previous moderation regime, which was known for banning people who disagreed with them, Joshua Stein was banned for publicly disagreeing with an HN policy, so Joshua created lobsters (and then eventually handed it off to Peter Bhat Harkins).
... we were stuck at SFO for something like four hours and getting to spend half a workday sitting next to Craig Newmark was pretty awesome.
I'd heard Craig say in interviews that he was basically just "head of customer service" for Craigslist but I always thought that was a throwaway self-deprecating joke. Like if you ran into Larry Page at Google and he claimed to just be the janitor or guy that picks out the free cereal at Google instead of the cofounder. But sitting next to him, I got a whole new appreciation for what he does. He was going through emails in his inbox, then responding to questions in the craigslist forums, and hopping onto his cellphone about once every ten minutes. Calls were quick and to the point "Hi, this is Craig Newmark from craigslist.org. We are having problems with a customer of your ISP and would like to discuss how we can remedy their bad behavior in our real estate forums". He was literally chasing down forum spammers one by one, sometimes taking five minutes per problem, sometimes it seemed to take half an hour to get spammers dealt with. He was totally engrossed in his work, looking up IP addresses, answering questions best he could, and doing the kind of thankless work I'd never seen anyone else do with so much enthusiasm. By the time we got on our flight he had to shut down and it felt like his giant pile of work got slightly smaller but he was looking forward to attacking it again when we landed.
At some point, if sites grow, they get big enough that a person can't really own every feature and every moderation action on the site, but sites can still get significant value out of having a single person own something that people would normally think is automated. A famous example of this is how the Digg "algorithm" was basically one person:
What made Digg work really was one guy who was a machine. He would vet all the stories, infiltrate all the SEO networks, and basically keep subverting them to keep the Digg front-page usable. Digg had an algorithm, but it was basically just a simple algorithm that helped this one dude 10x his productivity and keep the quality up.
Google came to buy Digg, but figured out that really it's just a dude who works 22 hours a day that keeps the quality up, and all that talk of an algorithm was smoke and mirrors to trick the SEO guys into thinking it was something they could game (they could not, which is why front page was so high quality for so many years). Google walked.
Then the founders realised if they ever wanted to get any serious money out of this thing, they had to fix that. So they developed "real algorithms" that independently attempted to do what this one dude was doing, to surface good/interesting content.
...
It was a total shit-show ... The algorithm to figure out what's cool and what isn't wasn't as good as the dude who worked 22 hours a day, and without his very heavy input, it just basically rehashed all the shit that was popular somewhere else a few days earlier ... Instead of taking this massive slap to the face constructively, the founders doubled-down. And now here we are.
...
Who I am referring to was named Amar (his name is common enough I don't think I'm outing him). He was the SEO whisperer and "algorithm." He was literally like a spy. He would infiltrate the awful groups trying to game the front page and trick them into giving him enough info that he could identify their campaigns early, and kill them. All the while pretending to be an SEO loser like them.
Etsy supposedly used the same strategy as well.
Another class of advantage that small sites have over large ones is that the small site usually doesn't care about being large and can do things that you wouldn't do if you wanted to grow. For example, consider these two comments made in the midst of a large flamewar on HN
My wife spent years on Twitter embroiled in a very long running and bitter political / rights issue. She was always thoughtful, insightful etc. She'd spend 10 minutes rewording a single tweet to make sure it got the real point across in a way that wasn't inflammatory, and that had a good chance of being persuasive. With 5k followers, I think her most popular tweets might get a few hundred likes. The one time she got drunk and angry, she got thousands of supportive reactions, and her followers increased by a large % overnight. And that scared her. She saw the way "the crowd" was pushing her. Rewarding her for the smell of blood in the water.
I've turned off both the flags and flamewar detector on this article now, in keeping with the first rule of HN moderation, which is (I'm repeating myself but it's probably worth repeating) that we moderate HN less, not more, when YC or a YC-funded startup is part of a story ... Normally we would never late a ragestorm like this stay on the front page—there's zero intellectual curiosity here, as the comments demonstrate. This kind of thing is obviously off topic for HN: https://news.ycombinator.com/newsguidelines.html. If it weren't, the site would consist of little else. Equally obvious is that this is why HN users are flagging the story. They're not doing anything different than they normally would.
For a social media site, low-quality high-engagement flamebait is one of the main pillars that drive growth. HN, which cares more about discussion quality than growth, tries to detect and suppress these (with exceptions like criticism of HN itself, of YC companies like Stripe, etc., to ensure a lack of bias). Any social media site that aims to grow does the opposite; they implement a ranked feed that puts the content that is most enraging and most engaging in front of the people its algorithms predict will be the most enraged and engaged by it. For example, let's say you're in a country with very high racial/religious/factonal tensions, with regular calls for violence, etc. What's the most engaging content? Well, that would be content calling for the death of your enemies, so you get things a livestream of someone calling for the death of the other faction and then grabbing someone and beating them shown to a lot of people. After all, what's more engaging than a beatdown of your sworn enemy? A theme of Broken Code is that someone will find some harmful content they want to suppress, but then get overruled because that would reduce engagement and growth. HN has no such goal, so it has no problem suppressing or eliminating content that HN deems to be harmful.
Another thing you can do if growth isn't your primary goal is to deliberately make user-signups high friction. HN adds does a little bit of this by having a "login" link but not a "sign up" link, and sites like lobste.rs and metafilter do even more of this.
In the main doc, we noted that big company employees often say that it's impossible to provide better support for theoretical reason X, without ever actually looking into how one provides support or what companies that provide good support do. When the now-$1T were the size where many companies do provide good support, these companies also did not provide good support, so this doesn't seem to come from size since these huge companies didn't even attempt to provide good support, then or now. This theoretical, plausible sounding, reason doesn't really hold up in practice.
This is generally the case for theoretical discussions on disceconomies of scale of large tech companies. Another example is an idea mentioned at the start of this doc, that being a larger target has a larger impact than having more sophisticated ML. A standard extension of this idea that I frequently hear is that big companies actually do have the best anti-spam and anti-fraud, but they're also subject to the most sophisticated attacks. I've seen this used as a justification for why big companies seem to have worst anti-spam and anti-fraud than a forum like HN. While it's likely true that big companies are subject to the most sophisticated attacks, if this whole idea held and it were the case that their systems were really good, it would be harder, in absolute terms, to spam or scam people on reddit and Facebook than on HN, but that's not the case at all.
If you actually try to spam, it's extremely easy to do so on large platforms and the most obvious things you might try will often work. As an experiment, I made a new reddit account and tried to get nonsense onto the front page and found this completely trivial. Similarly it's completely trivial to take over someone's Facebook account and post obvious scams for months to years, with extremely markers that they're scams, many people replying in concern that the account has been taken over and is running scams (unlike working in support and spamming reddit, I didn't try taking over people's Facebook accounts, but given people's password practices, it's very easy to take over an account, and given how Facebook responds to these takeovers when a friend's account is taken over, we can see that attacks that do the most naive thing possible, with zero sophistication, are not defeated), etc. In absolute terms, it's actually more difficult to get spammy or scammy content in front of eyeballs on HN than it is on reddit or Facebook.
The theoretical reason here is one that would be significant if large companies were even remotely close to doing the kind of job they could do with the resources they have, but we're not even close to being there.
To avoid belaboring the point in this already very long document, I've only listed a couple of examples here, but I find this pattern to hold true of almost every counterargument I've heard on this topic. If you actually look into it a bit, these theoretical arguments are classic cocktail party ideas that have little to no connection to reality.
A meta point here is that you absolutely cannot trust vaguely plausible sounding arguments from people on this since they virtually all of them fall apart when examined in practice. It seems quite reasonable to think that a business the size of reddit would have more sophisticated anti-spam systems than HN, which has a single person who both writes the code for the anti-spam systems and does the moderation. But the most naive and simplistic tricks you might use to put content on the front page work on reddit and don't work on HN. I'm not saying you can't defeat HN's system, but doing so would take a little bit of thought, which is not the case for reddit and Facebook. And likewise for support, where once you start talking to people about how to run a support org that's good for users, you immediately see that the most obvious things have not been seriously tried by big tech companies.
Overall, very little. As we discussed when we looked at the Cruise pedestrian accident report, almost every time I read a journalist's take on something (with rare exceptions like Zeynep), the journalist has a spin they're trying to put on the story and the impression you get from reading the story is quite different from the impression you get if you look at the raw source; it's fairly common that there's so much spin that the story says the opposite of what the source docs say. That's one issue.
The full topic here is big enough that it deserves its own document, so we'll just look at two examples. The first is one we briefly looked at, when Eugene Zarashaw, a director at Facebook, testified in a Special Master’s Hearing. He said
It would take multiple teams on the ad side to track down exactly the — where the data flows. I would be surprised if there’s even a single person that can answer that narrow question conclusively
Eugene's testimony resulted in headlines like , "Facebook Has No Idea What Is Going on With Your Data", "Facebook engineers admit there’s no way to track all the data it collects on you" (with a stock photo of an overwhelmed person in a nest of cables, grabbing their head) and "Facebook Engineers: We Have No Idea Where We Keep All Your Personal Data", etc.
Even without any technical knowledge, any unbiased person can plainly see that these headlines are inaccurate. There's a big difference between it taking work to figure out exactly where all data, direct and derived, for each user exists, and having no idea where the data is. If I Google, logged out with no cookies, Eugene Zarashaw facebook testimony, every single above the fold result I get is misleading, false, clickbait, like the above.
For most people with relevant technical knowledge, who understand the kind of systems being discussed, Eugene Zarashaw's quote is not only not egregious, it's mundane, expected, and reasonable.
Despite this lengthy disclaimer, there are a few reasons that I feel comfortable citing Jeff Horwitz's Broken Code as well as a few stories that cover similar ground. The first is that, if you delete all of the references to these accounts, the points in this doc don't really change, just like they wouldn't change if you delete 50% of the user stories mentioned here. The second is that, at least for me, the most key part is the attitudes on display and not the specific numbers. I've seen similar attitudes in companies I've worked for and heard about them inside companies where I'm well connected via my friends and I could substitute similar stories from my friends, but it's nice to be able to use already-public sources instead of using anonymized stories from my friends, so the quotes about attitude are really just a stand-in for other stories which I can verify. The third reason is a bit too subtle to describe here, so we'll look at that when I expand this disclaimer into a standalone document.
If you're looking for work, Freshpaint is hiring (US remote) in engineering, sales, and recruiting. Disclaimer: I may be biased since I'm an investor, but they seem to have found product-market fit and are rapidly growing.
Erin starts with
But once I started to really dig in, what I learned was so much gnarlier and grosser and more devastating than what I’d assumed. The harms Meta passively and actively fueled destroyed or ended hundreds of thousands of lives that might have been yours or mine, but for accidents of birth. I say “hundreds of thousands” because “millions” sounds unbelievable, but by the end of my research I came to believe that the actual number is very, very large.
To make sense of it, I had to try to go back, reset my assumptions, and try build up a detailed, factual understanding of what happened in this one tiny slice of the world’s experience with Meta. The risks and harms in Myanmar—and their connection to Meta’s platform—are meticulously documented. And if you’re willing to spend time in the documents, it’s not that hard to piece together what happened. Even if you never read any further, know this: Facebook played what the lead investigator on the UN Human Rights Council’s Independent International Fact-Finding Mission on Myanmar (hereafter just “the UN Mission”) called a “determining role” in the bloody emergence of what would become the genocide of the Rohingya people in Myanmar.2
From far away, I think Meta’s role in the Rohingya crisis can feel blurry and debatable—it was content moderation fuckups, right? In a country they weren’t paying much attention to? Unethical and probably negligent, but come on, what tech company isn’t, at some point?
As discussed above, I have not looked into the details enough to determine if the claim that Facebook played a "determining role" in genocide are correct, but at a meta-level (no pun intended), it seems plausible. Every comment I've seen that aims to be a direction refutation of Erin's position is actually pre-refuted by Erin in Erin's text, so it appears that very few people who are publicly commenting who disagree with Erin read the articles before commenting (or they've read them and failed to understand what Erin is saying) and, instead, are disagreeing based on something other than the actual content. It reminds me a bit of the responses to David Jackson's proof of the four color theorem. Some people thought it was, finally, a proof, and others thought it wasn't.. Something I found interesting at the time was that the people who thought it wasn't a proof had read the paper and thought it seemed flawed, whereas the people who thought it was a proof were going off of signals like David's track record or the prestige of his institution. At the time, without having read the paper myself, I guessed (with low confidence) that the proof was incorrect based on the meta-heuristic that thoughts from people who read the paper were stronger evidence than things like prestige. Similarly, I would guess that Erin's summary is at least roughly accurate and that Erin's endorsement of the UN HRC fact-finding mission is correct, although I have lower confidence in this than in my guess about the proof because making a positive claim like this is harder than finding a flaw and the area is one where evaluating a claim is significantly trickier.
Unlike with Broken Code, the source documents are available here and it would be possible to retrace Erin's steps, but since there's quite a bit of source material and the claims that would need additional reading and analysis to really be convinced and those claims don't play a determining role in the correctness of this document, I'll leave that for somebody else.
On the topic itself, Erin noted that some people at Facebook, when presented with evidence that something bad was happening, laughed it off as they simply couldn't believe that Facebook could be instrumental in something that bad. Ironically, this is fairly similar in tone and content to a lot of the "refutations" of Erin's articles which appear to have not actually read the articles.
The most substantive objections I've seen are around the edges which, such as
The article claims that "Arturo Bejar" was "head of engineering at Facebook", which is simply false. He appears to have been a Director, which is a manager title overseeing (typically) less than 100 people. That isn't remotely close to "head of engineering".
What Erin actually said was
... Arturo Bejar, one of Facebook’s heads of engineering
So the objection is technically incorrect in that it was not said that Arturo Bejar was head of engineering. And, if you read the entire set of articles, you'll see references like "Susan Benesch, head of the Dangerous Speech Project" and "the head of Deloitte in Myanmar", so it appears that the reason that Erin said that "one of Facebook’s heads of engineering" is that Erin is using the term head colloquially here (and note that the it isn't capitalized, as a title might be), to mean that Arturo was in charge of something.
There is a form of the above objection that's technically correct — for an engineer at a big tech company, the term Head of Engineering will generally call to mind an executive who all engineers transitively report into (or, in cases where there are large pillars, perhaps one of a few such people). Someone who's fluent in internal tech company lingo would probably not use this phrasing, even when writing for lay people, but this isn't strong evidence of factual errors in the article even if, in an ideal world, journalists would be fluent in the domain-specific connotations of every phrase.
The person's objection continues with
I point this out because I think it calls into question some of the accuracy of how clearly the problem was communicated to relevant people at Facebook.
It isn't enough for someone to tell random engineers or Communications VPs about a complex social problem.
On the topic of this post, diseconomies of scale, this objection, if correct, actually supports the post. According to Arturo's LinkedIn, he was "the leader for Integrity and Care Facebook", and the book Broken Code discusses his role at length, which is very closely related to the topic of Meta in Myanmar. Arturo is not, in fact, a "random engineers or Communications VP".
Anway, Erin documents that Facebook was repeatedly warned about what was happening, for years. These warnings went well beyond the standard reporting of bad content and fake accounts (although those were also done), and included direct conversations with directors, VPs, and other leaders. These warnings were dismissed and it seems that people thought that their existing content moderation systems were good enough, even in the face of fairly strong evidence that this was not the case.
Reuters notes that one of the examples Schissler gives Meta was a Burmese Facebook Page called, “We will genocide all of the Muslims and feed them to the dogs.” 48
None of this seems to get through to the Meta employees on the line, who are interested in…cyberbullying. Frenkel and Kang write that the Meta employees on the call “believed that the same set of tools they used to stop a high school senior from intimidating an incoming freshman could be used to stop Buddhist monks in Myanmar.”49
Aela Callan later tells Wired that hate speech seemed to be a “low priority” for Facebook, and that the situation in Myanmar, “was seen as a connectivity opportunity rather than a big pressing problem.”50
The details make this sound worse than a small excerpt, so I recommend reading the entire thing, but with respect to the discussion about resources, a key issue is that even after Meta decided to take some kind of action, the result was:
As the Burmese civil society people in the private Facebook group finally learn, Facebook has a single Burmese-speaking moderator—a contractor based in Dublin—to review everything that comes in. The Burmese-language reporting tool is, as Htaike Htaike Aung and Victoire Rio put it in their timeline, “a road to nowhere."
Since this was 2014, it's not fair to say that Meta could've spent the $50B metaverse dollars and hired 1.6 million moderators, but in 2014, it was still the 4th largest tech company in the world, worth $217B, with a net profit of $3B/yr, Meta would've "only" been able to afford something like 100k moderators and support staff if paid at a globally very generous loaded cost of $30k/yr (e.g., Jacobin notes that Meta's Kenyan moderators are paid $2/hr and don't get benefits). Myanmar's share of the global population was 0.7% and, let's say that you consider a developing genocide to be low priority and don't think that additional resources should be deployed to prevent or stop it and want to allocate a standard moderation share, then we have "only" have capacity for 700 generously paid moderation and support staff for Myanmar.
On the other side of the fence, there actually were 700 people:
in the years before the coup, it already had an internal adversary in the military that ran a professionalized, Russia-trained online propaganda and deception operation that maxed out at about 700 people, working in shifts to manipulate the online landscape and shout down opposing points of view. It’s hard to imagine that this force has lessened now that the genocidaires are running the country.
These folks didn't have the vaunted technology that Zuckerberg says that smaller companies can't match, but it turns out you don't need billions of dollars of technology when it's 700 on 1 and the 1 is using tools that were developed for a different purpose.
As you'd expect if you've ever interacted with the reporting system for a huge tech company, from the outside, nothing people tried worked:
They report posts and never hear anything. They report posts that clearly call for violence and eventually hear back that they’re not against Facebook’s Community Standards. This is also true of the Rohingya refugees Amnesty International interviews in Bangladesh
In the 40,000 word summary, Erin also digs through whistleblower reports to find things like
…we’re deleting less than 5% of all of the hate speech posted to Facebook. This is actually an optimistic estimate—previous (and more rigorous) iterations of this estimation exercise have put it closer to 3%, and on V&I [violence and incitement] we’re deleting somewhere around 0.6%…we miss 95% of violating hate speech.
and
[W]e do not … have a model that captures even a majority of integrity harms, particularly in sensitive areas … We only take action against approximately 2% of the hate speech on the platform. Recent estimates suggest that unless there is a major change in strategy, it will be very difficult to improve this beyond 10-20% in the short-medium term
and
While Hate Speech is consistently ranked as one of the top abuse categories in the Afghanistan market, the action rate for Hate Speech is worryingly low at 0.23 per cent.
To be clear, I'm not saying that Facebook has a significantly worse rate of catching bad content than other platforms of similar or larger size. As we noted above, large tech companies often have fairly high false positive and false negative rates and have employees who dismiss concerns about this, saying that things are fine.
Since I saw Zuck's statement about how only large companies (and the larger the better) can possibly do good moderation, anti-fraud, anti-spam, etc., I've been collecting links I run across when doing normal day-to-browsing of failures by large companies. If I deliberately looked for failures, I'd have a lot more. And, for some reason, some companies don't really trigger my radar for this so, for example, even though I see stories about AirBnB issues all the time, it didn't occur to me to collect them until I started writing this post, so there are only a few AirBnB fails here, even though they'd be up there with Uber in failure count if I actually recorded the links I saw.
These are so frequent that, out of eight draft readers, at least two draft readers ran into an issue while reading the draft of this doc. Peter Bhat Harkins reported:
Well, I received a keychron keyboard a few days ago. I ordered a used K1 v5 (Keychron does small, infrequent production runs so it was out of stock everywhere). I placed the order on KeyChron's official Amazon store, fulfilled by Amazon. After some examination, I've received a v4. It's the previous gen mechanical switch instead of the current optical switch. Someone apparently peeled off the sticker with the model and serial number and one key stabilizer is broken from wear, which strongly implies someone bought a v5 and returned a v4 they already owned. Apparently this is a common scam on Amazon now.
In the other case, an anonymous reader created a Gmail account to used as a shared account for them and their partner, so they could get shared emails from local services. I know a number of people who've done this and this usually works fine, but in their case, after they used this email to set up a few services, Google decided that their account was suspicious:
Verify your identity
We’ve detected unusual activity on the account you’re trying to access. To continue, please follow the instructions below.
Provide a phone number to continue. We’ll send a verification code you can use to sign in.
Providing the phone number they used to sign up for the account resulted in
This phone number has already been used too many times for verification.
For whatever reason, even though this number was provided at account creation, using this apparently illegal number didn't result in the account being banned until it had been used for a while and the email address had been used to sign up for some services. Luckily, these were local services by small companies, so this issue could be fixed by calling them up. I've seen something similar happen with services that don't require you to provide a phone number on sign-up, but then lock and effectively ban the account unless you provide a phone number later, but I've never seen a case where the provided phone number turned out to not work after a day or two. The message above can be read two ways, the other way being that the phone number was allowed but had just recently been used to receive too many verification codes but, in recent history, the phone number had only once been used to receive a code, and that was the verification code necessary to attach a (required) phone number to the account in the first place.
I also had a quality control failure from Amazon, when I ordered a 10 pack of Amazon Basics power strips and the first one I pulled out had its cable covered in solder. I wonder what sort of process could leave solder, likely lead-based solder (although I didn't test it) all over the outside of one of these and wonder if I need to wash every Amazon Basics electronics item I get if I don't want lead dust getting all over my apartment. And, of course, since this is constant, I had many spam emails get through Gmail's spam filter and hit my inbox, and multiple ham emails get filtered into spam, including the classic case where I emailed someone and their reply to me went to spam; from having talked to them about it previously, I have no doubt that most of my draft readers who use Gmail also had something similar happen to them and that this is so common they didn't even find it worth remarking on.
Anyway, below, in a few cases, I've mentioned when commenters blame the user even though the issue is clearly not the user's fault. I haven't done this even close to exhaustively, so the lack of such a comment from me shouldn't be read as the lack of the standard "the user must be at fault" response from people.
[email protected] if you change the email on your account, but this didn't happen; user looked at their Fastmail logs and believes that their email was not compromisedMWAIT instruction, an engineering sample that was apparently from before Intel had finalized the current behavior of MWAIT).User gets constant stream of unwanted Amazon packages
Mechanic warns people not to buy car parts on Amazon because counterfeits are so frequent
User stops buying household products from Amazon because counterfeit rate is too high
Amazon driver mishears automated response from Eufy doorbell, causing Amazon to shut down user's smarthome (user was able to get smarthome and account back after one week)
Amazon account gets locked out; support refuses to acknowledge there's an issue until user calls back many times and then tells user to abandon the account and make another one
User has Amazon account closed because they sometimes send gifts to friends back home in Belarus
User gets counterfeit item from Amazon; they contact support with detailed photos showing that the item is counterfeit and support replies with "the information we have indicates that the product you received was authentic"
User gets the wrong GPU from Amazon, twice; luckily for them, the second time, Amazon sent a higher end GPU than was purchased, so the user is getting a free upgrade
Technical book publisher fails to get counterfeits removed from Amazon
ChatGPT clone of author's book only removed after Washington Post story on problem
Searching for children's books on Amazon returns AI generated nonsense
Amazon takes down legitimate cookbook; author notes "They won't tell us why. They won't tell us how to fix whatever tripped the algorithm. They won't seem to let us appeal. Reaching a human at Amazon is a Kafkaesque experience that we haven't yet managed to do."
Amazon basically steals $250 from customer, appeal does nothing, as usual
User receives fake GPU from Amazon, after an attempt to buy from the official Amazon.com msi store
Amazon sells many obviously fake 16 TB physically tiny SSD drives for $100
User notes that bestselling item on Amazon is a fake item and that they tried to leave a review to this effect, but the review was rejected
Amazon sells Android TV boxes that are actually malware
Amazon scammer causes user to get arrested and charged for fraud, which causes user to lose their job
Illegal weapon a bestselling item on Amazon, although this does get removed after it's reported
I tried to buy 3M 616 litho tape from Amazon (in Canada) and every listing had a knock-off product that copy+pasted the description of 3M 616 into the description
When searching for replacement Kidde smoke detectors on amazon.ca, all of the one I found are not Canadian versions, meaning they're not approved by SA, cUL, ULC or cETL. It's possible this doesn't matter, but in the event of a fire and an insurance claim, I wouldn't want to have a non-approved smoke detector
This includes GitHub, LinkedIn, Activision, etc.
I dropped most of the Twitter stories since there are so many after the acquisition that it seems silly to list them, but I've kept a few random ones.
I've seen a ton of these but, for some reason, it didn't occur to me to add them to my list, so I don't have a lot of examples even though I've probably seen three times as many of these as I've seen Uber horror stories.
Below are a few relevant excerpts. This is intended to be analogous to Zvi Mowshowitz's Quotes from Moral Mazes, which gives you an idea of what's in the book but is definitely not a replacement for reading the book. If these quotes are interesting, I recommend reading the book!
The former employees who agreed to speak to me said troubling things from the get-go. Facebook’s automated enforcement systems were flatly incapable of performing as billed. Efforts to engineer growth had inadvertently rewarded political zealotry. And the company knew far more about the negative effects of social media usage than it let on.
as the election progressed, the company started receiving reports of mass fake accounts, bald-faced lies on campaign-controlled pages, and coordinated threats of violence against Duterte critics. After years in politics, Harbath wasn’t naive about dirty tricks. But when Duterte won, it was impossible to deny that Facebook’s platform had rewarded his combative and sometimes underhanded brand of politics. The president-elect banned independent media from his inauguration—but livestreamed the event on Facebook. His promised extrajudicial killings began soon after.A month after Duterte’s May 2016 victory came the United Kingdom’s referendum to leave the European Union. The Brexit campaign had been heavy on anti-immigrant sentiment and outright lies. As in the Philippines, the insurgent tactics seemed to thrive on Facebook—supporters of the “Leave” camp had obliterated “Remain” supporters on the platform. ... Harbath found all that to be gross, but there was no denying that Trump was successfully using Facebook and Twitter to short-circuit traditional campaign coverage, garnering attention in ways no campaign ever had. “I mean, he just has to go and do a short video on Facebook or Instagram and then the media covers it,” Harbath had marveled during a talk in Europe that spring. She wasn’t wrong: political reporters reported not just the content of Trump’s posts but their like counts.
Did Facebook need to consider making some effort to fact-check lies spread on its platform? Harbath broached the subject with Adam Mosseri, then Facebook’s head of News Feed.
“How on earth would we determine what’s true?” Mosseri responded. Depending on how you looked at it, it was an epistemic or a technological conundrum. Either way, the company chose to punt when it came to lies on its platform.
Zuckerberg believed math was on Facebook’s side. Yes, there had been misinformation on the platform—but it certainly wasn’t the majority of content. Numerically, falsehoods accounted for just a fraction of all news viewed on Facebook, and news itself was just a fraction of the platform’s overall content. That such a fraction of a fraction could have thrown the election was downright illogical, Zuckerberg insisted.. ... But Zuckerberg was the boss. Ignoring Kornblut’s advice, he made his case the following day during a live interview at Techonomy, a conference held at the Ritz-Carlton in Half Moon Bay. Calling fake news a “very small” component of the platform, he declared the possibility that it had swung the election “a crazy idea.” ... A favorite saying at Facebook is that “Data Wins Arguments.” But when it came to Zuckerberg’s argument that fake news wasn’t a major problem on Facebook, the company didn’t have any data. As convinced as the CEO was that Facebook was blameless, he had no evidence of how “fake news” came to be, how it spread across the platform, and whether the Trump campaign had made use of it in their Facebook ad campaigns. ... One week after the election, BuzzFeed News reporter Craig Silverman published an analysis showing that, in the final months of the election, fake news had been the most viral election-related content on Facebook. A story falsely claiming that the pope had endorsed Trump had gotten more than 900,000 likes, reshares, and comments—more engagement than even the most widely shared stories from CNN, the New York Times, or the Washington Post. The most popular falsehoods, the story showed, had been in support of Trump.It was a bombshell. Interest in the term “fake news” spiked on Google the day the story was published—and it stayed high for years, first as Trump’s critics cited it as an explanation for the president-elect’s victory, and then as Trump co-opted the term to denigrate the media at large. ... even as the company’s Communications staff had quibbled with Silverman’s methodology, executives had demanded that News Feed’s data scientists replicate it. Was it really true that lies were the platform’s top election-related content?
A day later, the staffers came back with an answer: almost.
A quick and dirty review suggested that the data BuzzFeed was using had been slightly off, but the claim that partisan hoaxes were trouncing real news in Facebook’s News Feed was unquestionably correct. Bullshit peddlers had a big advantage over legitimate publications—their material was invariably compelling and exclusive. While scores of mainstream news outlets had written rival stories about Clinton’s leaked emails, for instance, none of them could compete with the headline “WikiLeaks CONFIRMS Hillary Sold Weapons to ISIS.”
The engineers weren’t incompetent—just applying often-cited company wisdom that “Done Is Better Than Perfect.” Rather than slowing down, Maurer said, Facebook preferred to build new systems capable of minimizing the damage of sloppy work, creating firewalls to prevent failures from cascading, discarding neglected data before it piled up in server-crashing queues, and redesigning infrastructure so that it could be readily restored after inevitable blowups.The same culture applied to product design, where bonuses and promotions were doled out to employees based on how many features they “shipped”—programming jargon for incorporating new code into an app. Conducted semiannually, these “Performance Summary Cycle” reviews incented employees to complete products within six months, even if it meant the finished product was only minimally viable and poorly documented. Engineers and data scientists described living with perpetual uncertainty about where user data was being collected and stored—a poorly labeled data table could be a redundant file or a critical component of an important product. Brian Boland, a longtime vice president in Facebook’s Advertising and Partnerships divisions, recalled that a major data-sharing deal with Amazon once collapsed because Facebook couldn’t meet the retailing giant’s demand that it not mix Amazon’s data with its own.
“Building things is way more fun than making things secure and safe,” he said of the company’s attitude. “Until there’s a regulatory or press fire, you don’t deal with it.”
Nowhere in the system was there much place for quality control. Instead of trying to restrict problem content, Facebook generally preferred to personalize users’ feeds with whatever it thought they would want to see. Though taking a light touch on moderation had practical advantages—selling ads against content you don’t review is a great business—Facebook came to treat it as a moral virtue, too. The company wasn’t failing to supervise what users did—it was neutral.Though the company had come to accept that it would need to do some policing, executives continued to suggest that the platform would largely regulate itself. In 2016, with the company facing pressure to moderate terrorism recruitment more aggressively, Sheryl Sandberg had told the World Economic Forum that the platform did what it could, but that the lasting solution to hate on Facebook was to drown it in positive messages.
“The best antidote to bad speech is good speech,” she declared, telling the audience how German activists had rebuked a Neo-Nazi political party’s Facebook page with “like attacks,” swarming it with messages of tolerance.
Definitionally, the “counterspeech” Sandberg was describing didn’t work on Facebook. However inspiring the concept, interacting with vile content would have triggered the platform to distribute the objectionable material to a wider audience.
... in an internal memo by Andrew “Boz” Bosworth, who had gone from being one of Mark Zuckerberg’s TAs at Harvard to one of his most trusted deputies and confidants at Facebook. Titled “The Ugly,” Bosworth wrote the memo in June 2016, two days after the murder of a Chicago man was inadvertently livestreamed on Facebook. Facing calls for the company to rethink its products, Bosworth was rallying the troops.“We talk about the good and the bad of our work often. I want to talk about the ugly,” the memo began. Connecting people created obvious good, he said—but doing so at Facebook’s scale would produce harm, whether it was users bullying a peer to the point of suicide or using the platform to organize a terror attack.
That Facebook would inevitably lead to such tragedies was unfortunate, but it wasn’t the Ugly. The Ugly, Boz wrote, was that the company believed in its mission of connecting people so deeply that it would sacrifice anything to carry it out.
“That’s why all the work we do in growth is justified. All the questionable contact importing practices. All the subtle language that helps people stay searchable by friends. All of the work we do to bring more communication in. The work we will likely have to do in China some day. All of it,” Bosworth wrote.
Every team responsible for ranking or recommending content rushed to overhaul their systems as fast as they could, setting off an explosion in the complexity of Facebook’s product. Employees found that the biggest gains often came not from deliberate initiatives but from simple futzing around. Rather than redesigning algorithms, which was slow, engineers were scoring big with quick and dirty machine learning experiments that amounted to throwing hundreds of variants of existing algorithms at the wall and seeing which versions stuck—which performed best with users. They wouldn’t necessarily know why a variable mattered or how one algorithm outperformed another at, say, predicting the likelihood of commenting. But they could keep fiddling until the machine learning model produced an algorithm that statistically outperformed the existing one, and that was good enough.
... in Facebook’s efforts to deploy a classifier to detect pornography, Arturo Bejar recalled, the system routinely tried to cull images of beds. Rather than learning to identify people screwing, the model had instead taught itself to recognize the furniture on which they most often did ... Similarly fundamental errors kept occurring, even as the company came to rely on far more advanced AI techniques to make far weightier and complex decisions than “porn/not porn.” The company was going all in on AI, both to determine what people should see, and also to solve any problems that might arise.
Willner happened to read an NGO report documenting the use of Facebook to groom and arrange meetings with dozens of young girls who were then kidnapped and sold into sex slavery in Indonesia. Zuckerberg was working on his public speaking skills at the time and had asked employees to give him tough questions. So, at an all-hands meeting, Willner asked him why the company had allocated money for its first-ever TV commercial—a recently released ninety-second spot likening Facebook to chairs and other helpful structures—but no budget for a staffer to address its platform’s known role in the abduction, rape, and occasional murder of Indonesian children.Zuckerberg looked physically ill. He told Willner that he would need to look into the matter ... Willner said, the company was hopelessly behind in the markets where she believed Facebook had the highest likelihood of being misused. When she left Facebook in 2013, she had concluded that the company would never catch up.
Within a few months, Facebook laid off the entire Trending Topics team, sending a security guard to escort them out of the building. A newsroom announcement said that the company had always hoped to make Trending Topics fully automated, and henceforth it would be. If a story topped Facebook’s metrics for viral news, it would top Trending Topics.The effects of the switch were not subtle. Freed from the shackles of human judgment, Facebook’s code began recommending users check out the commemoration of “National Go Topless Day,” a false story alleging that Megyn Kelly had been sacked by Fox News, and an only-too-accurate story titled “Man Films Himself Having Sex with a McChicken Sandwich.”
Setting aside the feelings of McDonald’s social media team, there were reasons to doubt that the engagement on that final story reflected the public’s genuine interest in sandwich-screwing: much of the engagement was apparently coming from people wishing they’d never seen such accursed content. Still, Zuckerberg preferred it this way. Perceptions of Facebook’s neutrality were paramount; dubious and distasteful was better than biased.
“Zuckerberg said anything that had a human in the loop we had to get rid of as much as possible,” the member of the early polarization team recalled.
Among the early victims of this approach was the company’s only tool to combat hoaxes. For more than a decade, Facebook had avoided removing even the most obvious bullshit, which was less a principled stance and more the only possible option for the startup. “We were a bunch of college students in a room,” said Dave Willner, Charlotte Willner’s husband and the guy who wrote Facebook’s first content standards. “We were radically unequipped and unqualified to decide the correct history of the world.”
But as the company started churning out billions of dollars in annual profit, there were, at least, resources to consider the problem of fake information. In early 2015, the company had announced that it had found a way to combat hoaxes without doing fact-checking—that is, without judging truthfulness itself. It would simply suppress content that users disproportionately reported as false.
Nobody was so naive as to think that this couldn’t get contentious, or that the feature wouldn’t be abused. In a conversation with Adam Mosseri, one engineer asked how the company would deal, for example, with hoax “debunkings” of manmade global warming, which were popular on the American right. Mosseri acknowledged that climate change would be tricky but said that was not cause to stop: “You’re choosing the hardest case—most of them won’t be that hard.”
Facebook publicly revealed its anti-hoax work to little fanfare in an announcement that accurately noted that users reliably reported false news. What it omitted was that users also reported as false any news story they didn’t like, regardless of its accuracy.
To stem a flood of false positives, Facebook engineers devised a workaround: a “whitelist” of trusted publishers. Such safe lists are common in digital advertising, allowing jewelers to buy preauthorized ads on a host of reputable bridal websites, for example, while excluding domains like www.wedddings.com. Facebook’s whitelisting was pretty much the same: they compiled a generously large list of recognized news sites whose stories would be treated as above reproach.
The solution was inelegant, and it could disadvantage obscure publishers specializing in factual but controversial reporting. Nonetheless, it effectively diminished the success of false viral news on Facebook. That is, until the company faced accusations of bias surrounding Trending Topics. Then Facebook preemptively turned it off.
The disabling of Facebook’s defense against hoaxes was part of the reason fake news surged in the fall of 2016.
Gomez-Uribe’s team hadn’t been tasked with working on Russian interference, but one of his subordinates noted something unusual: some of the most hyperactive accounts seemed to go entirely dark on certain days of the year. Their downtime, it turned out, corresponded with a list of public holidays in the Russian Federation.“They respect holidays in Russia?” he recalled thinking. “Are we all this fucking stupid?”
But users didn’t have to be foreign trolls to promote problem posts. An analysis by Gomez-Uribe’s team showed that a class of Facebook power users tended to favor edgier content, and they were more prone to extreme partisanship. They were also, hour to hour, more prolific—they liked, commented, and reshared vastly more content than the average user. These accounts were outliers, but because Facebook recommended content based on aggregate engagement signals, they had an outsized effect on recommendations. If Facebook was a democracy, it was one in which everyone could vote whenever they liked and as frequently as they wished. ... hyperactive users tended to be more partisan and more inclined to share misinformation, hate speech, and clickbait,
At Facebook, he realized, nobody was responsible for looking under the hood. “They’d trust the metrics without diving into the individual cases,” McNally said. “It was part of the ‘Move Fast’ thing. You’d have hundreds of launches every year that were only driven by bottom-line metrics.”Something else worried McNally. Facebook’s goal metrics tended to be calculated in averages.
“It is a common phenomenon in statistics that the average is volatile, so certain pathologies could fall straight out of the geometry of the goal metrics,” McNally said. In his own reserved, mathematically minded way, he was calling Facebook’s most hallowed metrics crap. Making decisions based on metrics alone, without carefully studying the effects on actual humans, was reckless. But doing it based on average metrics was flat-out stupid. An average could rise because you did something that was broadly good for users, or it could go up because normal people were using the platform a tiny bit less and a small number of trolls were using Facebook way more.
Everyone at Facebook understood this concept—it’s the difference between median and mean, a topic that is generally taught in middle school. But, in the interest of expediency, Facebook’s core metrics were all based on aggregate usage. It was as if a biologist was measuring the strength of an ecosystem based on raw biomass, failing to distinguish between healthy growth and a toxic algae bloom.
One distinguishing feature was the shamelessness of fake news publishers’ efforts to draw attention. Along with bad information, their pages invariably featured clickbait (sensationalist headlines) and engagement bait (direct appeals for users to interact with content, thereby spreading it further).Facebook already frowned on those hype techniques as a little spammy, but truth be told it didn’t really do much about them. How much damage could a viral “Share this if you support the troops” post cause?
Facebook’s mandate to respect users’ preferences posed another challenge. According to the metrics the platform used, misinformation was what people wanted. Every metric that Facebook used showed that people liked and shared stories with sensationalistic and misleading headlines.McNally suspected the metrics were obscuring the reality of the situation. His team set out to demonstrate that this wasn’t actually true. What they found was that, even though users routinely engaged with bait content, they agreed in surveys that such material was of low value to them. When informed that they had shared false content, they experienced regret. And they generally considered fact-checks to contain useful information.
every time a well-intentioned proposal of that sort blew up in the company’s face, the people working on misinformation lost a bit of ground. In the absence of a coherent, consistent set of demands from the outside world, Facebook would always fall back on the logic of maximizing its own usage metrics.“If something is not going to play well when it hits mainstream media, they might hesitate when doing it,” McNally said. “Other times we were told to take smaller steps and see if anybody notices. The errors were always on the side of doing less.” ... “For people who wanted to fix Facebook, polarization was the poster child of ‘Let’s do some good in the world,’ ” McNally said. “The verdict came back that Facebook’s goal was not to do that work.”
When the ranking team had begun its work, there had been no question that Facebook was feeding its users overtly false information at a rate that vastly outstripped any other form of media. This was no longer the case (even though the company would be raked over the coals for spreading “fake news” for years to come).Ironically, Facebook was in a poor position to boast about that success. With Zuckerberg having insisted throughout that fake news accounted for only a trivial portion of content, Facebook couldn’t celebrate that it might be on the path of making the claim true.
multiple members of both teams recalled having had the same response when they first learned of MSI’s new engagement weightings: it was going to make people fight. Facebook’s good intent may have been genuine, but the idea that turbocharging comments, reshares, and emojis would have unpleasant effects was pretty obvious to people who had, for instance, worked on Macedonian troll farms, sensationalism, and hateful content.Hyperbolic headlines and outrage bait were already well-recognized digital publishing tactics, on and off Facebook. They traveled well, getting reshared in long chains. Giving a boost to content that galvanized reshares was going to add an exponential component to the already-healthy rate at which such problem content spread. At a time when the company was trying to address purveyors of misinformation, hyperpartisanship, and hate speech, it had just made their tactics more effective.
Multiple leaders inside Facebook’s Integrity team raised concerns about MSI with Hegeman, who acknowledged the problem and committed to trying to fine-tune MSI later. But adopting MSI was a done deal, he said—Zuckerberg’s orders.
Even non-Integrity staffers recognized the risk. When a Growth team product manager asked if the change meant News Feed would favor more controversial content, the manager of the team responsible for the work acknowledged it very well could.
The effect was more than simply provoking arguments among friends and relatives. As a Civic Integrity researcher would later report back to colleagues, Facebook’s adoption of MSI appeared to have gone so far as to alter European politics. “Engagement on positive and policy posts has been severely reduced, leaving parties increasingly reliant on inflammatory posts and direct attacks on their competitors,” a Facebook social scientist wrote after interviewing political strategists about how they used the platform. In Poland, the parties described online political discourse as “a social-civil war.” One party’s social media management team estimated that they had shifted the proportion of their posts from 50/50 positive/negative to 80 percent negative and 20 percent positive, explicitly as a function of the change to the algorithm. Major parties blamed social media for deepening political polarization, describing the situation as “unsustainable.”The same was true of parties in Spain. “They have learnt that harsh attacks on their opponents net the highest engagement,” the researcher wrote. “From their perspective, they are trapped in an inescapable cycle of negative campaigning by the incentive structures of the platform.”
If Facebook was making politics more combative, not everyone was upset about it. Extremist parties proudly told the researcher that they were running “provocation strategies” in which they would “create conflictual engagement on divisive issues, such as immigration and nationalism.”
To compete, moderate parties weren’t just talking more confrontationally. They were adopting more extreme policy positions, too. It was a matter of survival. “While they acknowledge they are contributing to polarization, they feel like they have little choice and are asking for help,” the researcher wrote.
Facebook’s most successful publishers of political content were foreign content farms posting absolute trash, stuff that made About.com’s old SEO chum look like it belonged in the New Yorker.Allen wasn’t the first staffer to notice the quality problem. The pages were an outgrowth of the fake news publishers that Facebook had battled in the wake of the 2016 election. While fact-checks and other crackdown efforts had made it far harder for outright hoaxes to go viral, the publishers had regrouped. Some of the same entities that BuzzFeed had written about in 2016—teenagers from a small Macedonian mountain town called Veles—were back in the game. How had Facebook’s news distribution system been manipulated by kids in a country with a per capita GDP of $5,800?
When reviewing troll farm pages, he noticed something—their posts usually went viral. This was odd. Competition for space in users’ News Feeds meant that most pages couldn’t reliably get their posts in front of even those people who deliberately chose to follow them. But with the help of reshares and the News Feed algorithms, the Macedonian troll farms were routinely reaching huge audiences. If having a post go viral was hitting the attention jackpot, then the Macedonians were winning every time they put a buck into Facebook’s slot machine.The reason the Macedonians’ content was so good was that it wasn’t theirs. Virtually every post was either aggregated or stolen from somewhere else on the internet. Usually such material came from Reddit or Twitter, but the Macedonians were just ripping off content from other Facebook pages, too, and reposting it to their far larger audiences. This worked because, on Facebook, originality wasn’t an asset; it was a liability. Even for talented content creators, most posts turned out to be duds. But things that had already gone viral nearly always would do so again.
Allen began a note about the problem from the summer of 2018 with a reminder. “The mission of Facebook is to empower people to build community. This is a good mission,” he wrote, before arguing that the behavior he was describing exploited attempts to do that. As an example, Allen compared a real community—a group known as the National Congress of American Indians. The group had clear leaders, produced original programming, and held offline events for Native Americans. But, despite NCAI’s earnest efforts, it had far fewer fans than a page titled “Native American Proub” [sic] that was run out of Vietnam. The page’s unknown administrators were using recycled content to promote a website that sold T-shirts.“They are exploiting the Native American Community,” Allen wrote, arguing that, even if users liked the content, they would never choose to follow a Native American pride page that was secretly run out of Vietnam. As proof, he included an appendix of reactions from users who had wised up. “If you’d like to read 300 reviews from real users who are very upset about pages that exploit the Native American community, here is a collection of 1 star reviews on Native American ‘Community’ and ‘Media’ pages,” he concluded.
This wasn’t a niche problem. It was increasingly the default state of pages in every community. Six of the top ten Black-themed pages—including the number one page, “My Baby Daddy Ain’t Shit”—were troll farms. The top fourteen English-language Christian- and Muslim-themed pages were illegitimate. A cluster of troll farms peddling evangelical content had a combined audience twenty times larger than the biggest authentic page.
“This is not normal. This is not healthy. We have empowered inauthentic actors to accumulate huge followings for largely unknown purposes,” Allen wrote in a later note. “Mostly, they seem to want to skim a quick buck off of their audience. But there are signs they have been in contact with the IRA.”
So how bad was the problem? A sampling of Facebook publishers with significant audiences found that a full 40 percent relied on content that was either stolen, aggregated, or “spun”—meaning altered in a trivial fashion. The same thing was true of Facebook video content. One of Allen’s colleagues found that 60 percent of video views went to aggregators.
The tactics were so well-known that, on YouTube, people were putting together instructional how-to videos explaining how to become a top Facebook publisher in a matter of weeks. “This is where I’m snagging videos from YouTube and I’ll re-upload them to Facebook,” said one guy in a video Allen documented, noting that it wasn’t strictly necessary to do the work yourself. “You can pay 20 dollars on Fiverr for a compilation—‘Hey, just find me funny videos on dogs, and chain them together into a compilation video.’ ”
Holy shit, Allen thought. Facebook was losing in the later innings of a game it didn’t even understand it was playing. He branded the set of winning tactics “manufactured virality.”
“What’s the easiest (lowest effort) way to make a big Facebook Page?” Allen wrote in an internal slide presentation. “Step 1: Find an existing, engaged community on [Facebook]. Step 2: Scrape/Aggregate content popular in that community. Step 3: Repost the most popular content on your Page.”
Allen’s research kicked off a discussion. That a top page for American Vietnam veterans was being run from overseas—from Vietnam, no less—was just flat-out embarrassing. And unlike killing off Page Like ads, which had been a nonstarter for the way it alienated certain internal constituencies, if Allen and his colleagues could work up ways to systematically suppress trash content farms—material that was hardly exalted by any Facebook team—getting leadership to approve them might be a real possibility.This was where Allen ran up against that key Facebook tenet, “Assume Good Intent.” The principle had been applied to colleagues, but it was meant to be just as applicable to Facebook’s billions of users. In addition to being a nice thought, it was generally correct. The overwhelming majority of people who use Facebook do so in the name of connection, entertainment, and distraction, and not to deceive or defraud. But, as Allen knew from experience, the motto was hardly a comprehensive guide to living, especially when money was involved.
With the help of another data scientist, Allen documented the inherent traits of crap publishers. They aggregated content. They went viral too consistently. They frequently posted engagement bait. And they relied on reshares from random users, rather than cultivating a dedicated long-term audience.None of these traits warranted severe punishment by itself. But together they added up to something damning. A 2019 screening for these features found 33,000 entities—a scant 0.175 percent of all pages—that were receiving a full 25 percent of all Facebook page views. Virtually none of them were “managed,” meaning controlled by entities that Facebook’s Partnerships team considered credible media professionals, and they accounted for just 0.14 percent of Facebook revenue.
After it was bought, CrowdTangle was no longer a company but a product, available to media companies at no cost. However much publishers were angry with Facebook, they loved Silverman’s product. The only mandate Facebook gave him was for his team to keep building things that made publishers happy. Savvy reporters looking for viral story fodder loved it, too. CrowdTangle could surface, for instance, an up-and-coming post about a dog that saved its owner’s life, material that was guaranteed to do huge numbers on social media because it was already heading in that direction.CrowdTangle invited its formerly paying media customers to a party in New York to celebrate the deal. One of the media executives there asked Silverman whether Facebook would be using CrowdTangle internally as an investigative tool, a question that struck Silverman as absurd. Yes, it had offered social media platforms an early window into their own usage. But Facebook’s staff now outnumbered his own by several thousand to one. “I was like, ‘That’s ridiculous—I’m sure whatever they have is infinitely more powerful than what we have!’ ”
It took Silverman more than a year to reconsider that answer.
It was only as CrowdTangle started building tools to do this that the team realized just how little Facebook knew about its own platform. When Media Matters, a liberal media watchdog, published a report showing that MSI had been a boon for Breitbart, Facebook executives were genuinely surprised, sending around the article asking if it was true. As any CrowdTangle user would have known, it was.Silverman thought the blindness unfortunate, because it prevented the company from recognizing the extent of its quality problem. It was the same point that Jeff Allen and a number of other Facebook employees had been hammering on. As it turned out, the person to drive it home wouldn’t come from inside the company. It would be Jonah Peretti, the CEO of BuzzFeed.
BuzzFeed had pioneered the viral publishing model. While “listicles” earned the publication a reputation for silly fluff in its early days, Peretti’s staff operated at a level of social media sophistication far above most media outlets, stockpiling content ahead of snowstorms and using CrowdTangle to find quick-hit stories that drew giant audiences.
In the fall of 2018, Peretti emailed Cox with a grievance: Facebook’s Meaningful Social Interactions ranking change was pressuring his staff to produce scuzzier content. BuzzFeed could roll with the punches, Peretti wrote, but nobody on his staff would be happy about it. Distinguishing himself from publishers who just whined about lost traffic, Peretti cited one of his platform’s recent successes: a compilation of tweets titled “21 Things That Almost All White People Are Guilty of Saying.” The list—which included “whoopsie daisy,” “get these chips away from me,” and “guilty as charged”—had performed fantastically on Facebook. What bothered Peretti was the apparent reason why. Thousands of users were brawling in the comments section over whether the item itself was racist.
“When we create meaningful content, it doesn’t get rewarded,” Peretti told Cox. Instead, Facebook was promoting “fad/junky science,” “extremely disturbing news,” “gross images,” and content that exploited racial divisions, according to a summary of Peretti’s email that circulated among Integrity staffers. Nobody at BuzzFeed liked producing that junk, Peretti wrote, but that was what Facebook was demanding. (In an illustration of BuzzFeed’s willingness to play the game, a few months later it ran another compilation titled “33 Things That Almost All White People Are Guilty of Doing.”)
As users’ News Feeds became dominated by reshares, group posts, and videos, the “organic reach” of celebrity pages began tanking. “My artists built up a fan base and now they can’t reach them unless they buy ads,” groused Travis Laurendine, a New Orleans–based music promoter and technologist, in a 2019 interview. A page with 10,000 followers would be lucky to reach more than a tiny percent of them.Explaining why a celebrity’s Facebook reach was dropping even as they gained followers was hell for Partnerships, the team tasked with providing VIP service to notable users and selling them on the value of maintaining an active presence on Facebook. The job boiled down to convincing famous people, or their social media handlers, that if they followed a set of company-approved best practices, they would reach their audience. The problem was that those practices, such as regularly posting original content and avoiding engagement bait, didn’t actually work. Actresses who were the center of attention on the Oscars’ red carpet would have their posts beaten out by a compilation video of dirt bike crashes stolen from YouTube. ... Over time, celebrities and influencers began drifting off the platform, generally to sister company Instagram. “I don’t think people ever connected the dots,” Boland said.
“Sixty-four percent of all extremist group joins are due to our recommendation tools,” the researcher wrote in a note summarizing her findings. “Our recommendation systems grow the problem.”This sort of thing was decidedly not supposed to be Civic’s concern. The team existed to promote civic participation, not police it. Still, a longstanding company motto was that “Nothing Is Someone Else’s Problem.” Chakrabarti and the researcher team took the findings to the company’s Protect and Care team, which worked on things like suicide prevention and bullying and was, at that point, the closest thing Facebook had to a team focused on societal problems.
Protect and Care told Civic there was nothing it could do. The accounts creating the content were real people, and Facebook intentionally had no rules mandating truth, balance, or good faith. This wasn’t someone else’s problem—it was nobody’s problem.
Even if the problem seemed large and urgent, exploring possible defenses against bad-faith viral discourse was going to be new territory for Civic, and the team wanted to start off slow. Cox clearly supported the team’s involvement, but studying the platform’s defenses against manipulation would still represent moonlighting from Civic’s main job, which was building useful features for public discussion online.A few months after the 2016 election, Chakrabarti made a request of Zuckerberg. To build tools to study political misinformation on Facebook, he wanted two additional engineers on top of the eight he already had working on boosting political participation.
“How many engineers do you have on your team right now?” Zuckerberg asked. Chakrabarti told him. “If you want to do it, you’re going to have to come up with the resources yourself,” the CEO said, according to members of Civic. Facebook had more than 20,000 engineers—and Zuckerberg wasn’t willing to give the Civic team two of them to study what had happened during the election.
While acknowledging the possibility that social media might not be a force for universal good was a step forward for Facebook, discussing the flaws of the existing platform remained difficult even internally, recalled product manager Elise Liu.“People don’t like being told they’re wrong, and they especially don’t like being told that they’re morally wrong,” she said. “Every meeting I went to, the most important thing to get in was ‘It’s not your fault. It happened. How can you be part of the solution? Because you’re amazing.’
“We do not and possibly never will have a model that captures even a majority of integrity harms, particularly in sensitive areas,” one engineer would write, noting that the company’s classifiers could identify only 2 percent of prohibited hate speech with enough precision to remove it.Inaction on the overwhelming majority of content violations was unfortunate, Rosen said, but not a reason to change course. Facebook’s bar for removing content was akin to the standard of guilt beyond a reasonable doubt applied in criminal cases. Even limiting a post’s distribution should require a preponderance of evidence. The combination of inaccurate systems and a high burden of proof would inherently mean that Facebook generally didn’t enforce its own rules against hate, Rosen acknowledged, but that was by design.
“Mark personally values free expression first and foremost and would say this is a feature, not a bug,” he wrote.
Publicly, the company declared that it had zero tolerance for hate speech. In practice, however, the company’s failure to meaningfully combat it was viewed as unfortunate—but highly tolerable.
Myanmar, ruled by a military junta that exercised near-complete control until 2011, was the sort of place where Facebook was rapidly filling in for the civil society that the government had never allowed to develop. The app offered telecommunications services, real-time news, and opportunities for activism to a society unaccustomed to them.In 2012, ethnic violence between the country’s dominant Buddhist majority and its Rohingya Muslim minority left around two hundred people dead and prompted tens of thousands of people to flee their homes. To many, the dangers posed by Facebook in the situation seemed obvious, including to Aela Callan, a journalist and documentary filmmaker who brought them to the attention of Elliot Schrage in Facebook’s Public Policy division in 2013. All the like-minded Myanmar Cassandras received a polite audience in Menlo Park, and little more. Their argument that Myanmar was a tinderbox was validated in 2014, when a hardline Buddhist monk posted a false claim on Facebook that a Rohingya man had raped a Buddhist woman, a provocation that produced clashes, killing two people. But with the exception of Bejar’s Compassion Research team and Cox—who was personally interested in Myanmar, privately funding independent news media there as a philanthropic endeavor—nobody at Facebook paid a great deal of attention.
Later accounts of the ignored warnings led many of the company’s critics to attribute Facebook’s inaction to pure callousness, though interviews with those involved in the cleanup suggest that the root problem was incomprehension. Human rights advocates were telling Facebook not just that its platform would be used to kill people but that it already had. At a time when the company assumed that users would suss out and shut down misinformation without help, however, the information proved difficult to absorb. The version of Facebook that the company’s upper ranks knew—a patchwork of their friends, coworkers, family, and interests—couldn’t possibly be used as a tool of genocide.
Facebook eventually hired its first Burmese-language content reviewer to cover whatever issues arose in the country of more than 50 million in 2015, and released a packet of flower-themed, peace-promoting digital stickers for Burmese users to slap on hateful posts. (The company would later note that the stickers had emerged from discussions with nonprofits and were “widely celebrated by civil society groups at the time.”) At the same time, it cut deals with telecommunications providers to provide Burmese users with Facebook access free of charge.
The first wave of ethnic cleansing began later that same year, with leaders of the country’s military announcing on Facebook that they would be “solving the problem” of the country’s Muslim minority. A second wave of violence followed and, in the end, 25,000 people were killed by the military and Buddhist vigilante groups, 700,000 were forced to flee their homes, and thousands more were raped and injured. The UN branded the violence a genocide.
Facebook still wasn’t responding. On its own authority, Gomez-Uribe’s News Feed Integrity team began collecting examples of the platform giving massive distribution to statements inciting violence. Even without Burmese-language skills, it wasn’t difficult. The torrent of anti-Rohingya hate and falsehoods from the Burmese military, government shills, and firebrand monks was not just overwhelming but overwhelmingly successful.
This was exploratory work, not on the Integrity Ranking team’s half-year roadmap. When Gomez-Uribe, along with McNally and others, pushed to reassign staff to better grasp the scope of Facebook’s problem in Myanmar, they were shot down.
“We were told no,” Gomez-Uribe recalled. “It was clear that leadership didn’t want to understand it more deeply.”
That changed, as it so often did, when Facebook’s role in the problem became public. A couple of weeks after the worst violence broke out, an international human rights organization condemned Facebook for inaction. Within seventy-two hours, Gomez-Uribe’s team was urgently asked to figure out what was going on.
When it was all over, Facebook’s negligence was clear. A UN report declared that “the response of Facebook has been slow and ineffective,” and an external human rights consultant that Facebook hired eventually concluded that the platform “has become a means for those seeking to spread hate and cause harm.”
In a series of apologies, the company acknowledged that it had been asleep at the wheel and pledged to hire more staffers capable of speaking Burmese. Left unsaid was why the company screwed up. The truth was that it had no idea what was happening on its platform in most countries.
Barnes was put in charge of “meme busting”—that is, combating the spread of viral hoaxes about Facebook, on Facebook. No, the company was not going to claim permanent rights to all your photos unless you reshared a post warning of the threat. And no, Zuckerberg was not giving away money to the people who reshared a post saying so. Suppressing these digital chain letters had an obvious payoff; they tarred Facebook’s reputation and served no purpose.Unfortunately, restricting the distribution of this junk via News Feed wasn’t enough to sink it. The posts also spread via Messenger, in large part because the messaging platform was prodding recipients of the messages to forward them on to a list of their friends.
The Advocacy team that Barnes had worked on sat within Facebook’s Growth division, and Barnes knew the guy who oversaw Messenger forwarding. Armed with data showing that the current forwarding feature was flooding the platform with anti-Facebook crap, he arranged a meeting.
Barnes’s colleague heard him out, then raised an objection.
“It’s really helping us with our goals,” the man said of the forwarding feature, which allowed users to reshare a message to a list of their friends with just a single tap. Messenger’s Growth staff had been tasked with boosting the number of “sends” that occurred each day. They had designed the forwarding feature to encourage precisely the impulsive sharing that Barnes’s team was trying to stop.
Barnes hadn’t so much lost a fight over Messenger forwarding as failed to even start one. At a time when the company was trying to control damage to its reputation, it was also being intentionally agnostic about whether its own users were slandering it. What was important was that they shared their slander via a Facebook product.
“The goal was in itself a sacred thing that couldn’t be questioned,” Barnes said. “They’d specifically created this flow to maximize the number of times that people would send messages. It was a Ferrari, a machine designed for one thing: infinite scroll.”
Entities like Liftable Media, a digital media company run by longtime Republican operative Floyd Brown, had built an empire on pages that began by spewing upbeat clickbait, then pivoted to supporting Trump ahead of the 2016 election. To compound its growth, Liftable began buying up other spammy political Facebook pages with names like “Trump Truck,” “Patriot Update,” and “Conservative Byte,” running its content through them.In the old world of media, the strategy of managing loads of interchangeable websites and Facebook pages wouldn’t make sense. For both economies of scale and to build a brand, print and video publishers targeted each audience through a single channel. (The publisher of Cat Fancy might expand into Bird Fancy, but was unlikely to cannibalize its audience by creating a near-duplicate magazine called Cat Enthusiast.)
That was old media, though. On Facebook, flooding the zone with competing pages made sense because of some algorithmic quirks. First, the algorithm favored variety. To prevent a single popular and prolific content producer from dominating users’ feeds, Facebook blocked any publisher from appearing too frequently. Running dozens of near-duplicate pages sidestepped that, giving the same content more bites at the apple.
Coordinating a network of pages provided a second, greater benefit. It fooled a News Feed feature that promoted virality. News Feed had been designed to favor content that appeared to be emerging organically in many places. If multiple entities you followed were all talking about something, the odds were that you would be interested so Facebook would give that content a big boost.
The feature played right into the hands of motivated publishers. By recommending that users who followed one page like its near doppelgängers, a publisher could create overlapping audiences, using a dozen or more pages to synthetically mimic a hot story popping up everywhere at once. ... Zhang, working on the issue in 2020, found that the tactic was being used to benefit publishers (Business Insider, Daily Wire, a site named iHeartDogs), as well as political figures and just about anyone interested in gaming Facebook content distribution (Dairy Queen franchises in Thailand). Outsmarting Facebook didn’t require subterfuge. You could win a boost for your content by running it on ten different pages that were all administered by the same account.
It would be difficult to overstate the size of the blind spot that Zhang exposed when she found it ... ... Liftable was an archetype of that malleability. The company had begun as a vaguely Christian publisher of the low-calorie inspirational content that once thrived on Facebook. But News Feed was a fickle master, and by 2015 Facebook had changed its recommendations in ways that stopped rewarding things like “You Won’t Believe Your Eyes When You See This Phenomenally Festive Christmas Light Show.”
The algorithm changes sent an entire class of rival publishers like Upworthy and ViralNova into a terminal tailspin, but Liftable was a survivor. In addition to shifting toward stories with headlines like “Parents Furious: WATCH What Teacher Did to Autistic Son on Stage in Front of EVERYONE,” Liftable acquired WesternJournal.com and every large political Facebook page it could get its hands on.
This approach was hardly a secret. Despite Facebook rules prohibiting the sale of pages, Liftable issued press releases about its acquisition of “new assets”—Facebook pages with millions of followers. Once brought into the fold, the network of pages would blast out the same content.
Nobody inside or outside Facebook paid much attention to the craven amplification tactics and dubious content that publishers such as Liftable were adopting. Headlines like “The Sodomites Are Aiming for Your Kids” seemed more ridiculous than problematic. But Floyd and the publishers of such content knew what they were doing, and they capitalized on Facebook’s inattention and indifference.
The early work trying to figure out how to police publishers’ tactics had come from staffers attached to News Feed, but that team was broken up during the consolidation of integrity work under Guy Rosen ... “The News Feed integrity staffers were told not to work on this, that it wasn’t worth their time,” recalled product manager Elise Liu ... Facebook’s policies certainly made it seem like removing networks of fake accounts shouldn’t have been a big deal: the platform required users to go by their real names in the interests of accountability and safety. In practice, however, the rule that users were allowed a single account bearing their legal name generally went unenforced.
In the spring of 2018, the Civic team began agitating to address dozens of other networks of recalcitrant pages, including one tied to a site called “Right Wing News.” The network was run by Brian Kolfage, a U.S. veteran who had lost both legs and a hand to a missile in Iraq.Harbath’s first reaction to Civic’s efforts to take down a prominent disabled veteran’s political media business was a flat no. She couldn’t dispute the details of his misbehavior—Kolfage was using fake or borrowed accounts to spam Facebook with links to vitriolic, sometimes false content. But she also wasn’t ready to shut him down for doing things that the platform had tacitly allowed.
“Facebook had let this guy build up a business using shady-ass tactics and scammy behavior, so there was some reluctance to basically say, like, ‘Sorry, the things that you’ve done every day for the last several years are no longer acceptable,’ ” she said. ... Other than simply giving up on enforcing Facebook’s rules, there wasn’t much left to try. Facebook’s Public Policy team remained uncomfortable with taking down a major domestic publisher for inauthentic amplification, and it made the Civic team prove that Kolfage’s content, in addition to his tactics, was objectionable. This hurdle became a permanent but undisclosed change in policy: cheating to manipulate Facebook’s algorithm wasn’t enough to get you kicked off the platform—you had to be promoting something bad, too.
Tests showed that the takedowns cut the amount of American political spam content by 20 percent overnight. Chakrabarti later admitted to his subordinates that he had been surprised that they had succeeded in taking a major action on domestic attempts to manipulate the platform. He had privately been expecting Facebook’s leadership to shut the effort down.
A staffer had shown Cox that a Brazilian legislator who supported the populist Jair Bolsonaro had posted a fabricated video of a voting machine that had supposedly been rigged in favor of his opponent. The doctored footage had already been debunked by fact-checkers, which normally would have provided grounds to bring the distribution of the post to an abrupt halt. But Facebook’s Public Policy team had long ago determined, after a healthy amount of discussion regarding the rule’s application to President Donald Trump, that government officials’ posts were immune from fact-checks. Facebook was therefore allowing false material that undermined Brazilians’ trust in democracy to spread unimpeded.... Despite Civic’s concerns, voting in Brazil went smoothly. The same couldn’t be said for Civic’s colleagues over at WhatsApp. In the final days of the Brazilian election, viral misinformation transmitted by unfettered forwarding had blown up.
Supporters of the victorious Bolsonaro, who shared their candidate’s hostility toward homosexuality, were celebrating on Facebook by posting memes of masked men holding guns and bats. The accompanying Portuguese text combined the phrase “We’re going hunting” with a gay slur, and some of the posts encouraged users to join WhatsApp groups supposedly for that violent purpose. Engagement was through the roof, prompting Facebook’s systems to spread them even further.While the company’s hate classifiers had been good enough to detect the problem, they weren’t reliable enough to automatically remove the torrent of hate. Rather than celebrating the race’s conclusion, Civic War Room staff put out an after-hours call for help from Portuguese-speaking colleagues. One polymath data scientist, a non-Brazilian who spoke great Portuguese and happened to be gay, answered the call.
For Civic staffers, an incident like this wasn’t a good time, but it wasn’t extraordinary, either. They had come to accept that unfortunate things like this popped up on the platform sometimes, especially around election time.
It took a glance at the Portuguese-speaking data scientist to remind Barnes how strange it was that viral horrors had become so routine on Facebook. The volunteer was hard at work just like everyone else, but he was quietly sobbing as he worked. “That moment is embedded in my mind,” Barnes said. “He’s crying, and it’s going to take the Operations team ten hours to clear this.”
India was a huge target for Facebook, which had already been locked out of China, despite much effort by Zuckerberg. The CEO had jogged unmasked through Tiananmen Square as a sign that he wasn’t bothered by Beijing’s notorious air pollution. He had asked President Xi Jinping, unsuccessfully, to choose a Chinese name for his first child. The company had even worked on a secret tool that would have allowed Beijing to directly censor the posts of Chinese users. All of it was to little avail: Facebook wasn’t getting into China. By 2019, Zuckerberg had changed his tune, saying that the company didn’t want to be there—Facebook’s commitment to free expression was incompatible with state repression and censorship. Whatever solace Facebook derived from adopting this moral stance, succeeding in India became all the more vital: If Facebook wasn’t the dominant platform in either of the world’s two most populous countries, how could it be the world’s most important social network?
Civic’s work got off to an easy start because the misbehavior was obvious. Taking only perfunctory measures to cover their tracks, all major parties were running networks of inauthentic pages, a clear violation of Facebook rules.The BJP’s IT cell seemed the most successful. The bulk of the coordinated posting could be traced to websites and pages created by Silver Touch, the company that had built Modi’s reelection campaign app. With cumulative follower accounts in excess of 10 million, the network hit both of Facebook’s agreed-upon standards for removal: they were using banned tricks to boost engagement and violating Facebook content policies by running fabricated, inflammatory quotes that allegedly exposed Modi opponents’ affection for rapists and that denigrated Muslims.
With documentation of all parties’ bad behavior in hand by early spring, the Civic staffers overseeing the project arranged an hour-long meeting in Menlo Park with Das and Harbath to make the case for a mass takedown. Das showed up forty minutes late and pointedly let the team know that, despite the ample cafés, cafeterias, and snack rooms at the office, she had just gone out for coffee. As the Civic Team’s Liu and Ghosh tried to rush through several months of research showing how the major parties were relying on banned tactics, Das listened impassively, then told them she’d have to approve any action they wanted to take.
The team pushed ahead with preparing to remove the offending pages. Mindful as ever of optics, the team was careful to package a large group of abusive pages together, some from the BJP’s network and others from the INC’s far less successful effort. With the help of Nathaniel Gleicher’s security team, a modest collection of Facebook pages traced to the Pakistani military was thrown in for good measure
Even with the attempt at balance, the effort soon got bogged down. Higher-ups’ enthusiasm for the takedowns was so lacking that Chakrabarti and Harbath had to lobby Kaplan directly before they got approval to move forward.
“I think they thought it was going to be simpler,” Harbath said of the Civic team’s efforts.
Still, Civic kept pushing. On April 1, less than two weeks before voting was set to begin, Facebook announced that it had taken down more than one thousand pages and groups in separate actions against inauthentic behavior. In a statement, the company named the guilty parties: the Pakistani military, the IT cell of the Indian National Congress, and “individuals associated with an Indian IT firm, Silver Touch.”
For anyone who knew what was truly going on, the announcement was suspicious. Of the three parties cited, the pro-BJP propaganda network was by far the largest—and yet the party wasn’t being called out like the others.
Harbath and another person familiar with the mass takedown insisted this had nothing to do with favoritism. It was, they said, simply a mess. Where the INC had abysmally failed at subterfuge, making the attribution unavoidable under Facebook’s rules, the pro-BJP effort had been run through a contractor. That fig leaf gave the party some measure of deniability, even if it might fall short of plausible.
If the announcement’s omission of the BJP wasn’t a sop to India’s ruling party, what Facebook did next certainly seemed to be. Even as it was publicly mocking the INC for getting caught, the BJP was privately demanding that Facebook reinstate the pages the party claimed it had no connection to. Within days of the takedown, Das and Kaplan’s team in Washington were lobbying hard to reinstate several BJP-connected entities that Civic had fought so hard to take down. They won, and some of the BJP pages got restored.
With Civic and Public Policy at odds, the whole messy incident got kicked up to Zuckerberg to hash out. Kaplan argued that applying American campaign standards to India and many other international markets was unwarranted. Besides, no matter what Facebook did, the BJP was overwhelmingly favored to return to power when the election ended in May, and Facebook was seriously pissing it off.
Zuckerberg concurred with Kaplan’s qualms. The company should absolutely continue to crack down hard on covert foreign efforts to influence politics, he said, but in domestic politics the line between persuasion and manipulation was far less clear. Perhaps Facebook needed to develop new rules—ones with Public Policy’s approval.
The result was a near moratorium on attacking domestically organized inauthentic behavior and political spam. Imminent plans to remove illicitly coordinated Indonesian networks of pages, groups, and accounts ahead of upcoming elections were shut down. Civic’s wings were getting clipped.
By 2019, Jin’s standing inside the company was slipping. He had made a conscious decision to stop working so much, offloading parts of his job onto others, something that did not conform to Facebook’s culture. More than that, Jin had a habit of framing what the company did in moral terms. Was this good for users? Was Facebook truly making its products better?Other executives were careful when bringing decisions to Zuckerberg to not frame decisions in terms of right or wrong. Everyone was trying to work collaboratively, to make a better product, and whatever Zuckerberg decided was good. Jin’s proposals didn’t carry that tone. He was unfailingly respectful, but he was also clear on what he considered the range of acceptable positions. Alex Schultz, the company’s chief marketing officer, once remarked to a colleague that the problem with Jin was that he made Zuckerberg feel like shit.
In July 2019, Jin wrote a memo titled “Virality Reduction as an Integrity Strategy” and posted it in a 4,200-person Workplace group for employees working on integrity problems. “There’s a growing set of research showing that some viral channels are used for bad more than they are used for good,” the memo began. “What should our principles be around how we approach this?” Jin went on to list, with voluminous links to internal research, how Facebook’s products routinely garnered higher growth rates at the expense of content quality and user safety. Features that produced marginal usage increases were disproportionately responsible for spam on WhatsApp, the explosive growth of hate groups, and the spread of false news stories via reshares, he wrote.
None of the examples were new. Each of them had been previously cited by Product and Research teams as discrete problems that would require either a design fix or extra enforcement. But Jin was framing them differently. In his telling, they were the inexorable result of Facebook’s efforts to speed up and grow the platform.
The response from colleagues was enthusiastic. “Virality is the goal of tenacious bad actors distributing malicious content,” wrote one researcher. “Totally on board for this,” wrote another, who noted that virality helped inflame anti-Muslim sentiment in Sri Lanka after a terrorist attack. “This is 100% direction to go,” Brandon Silverman of CrowdTangle wrote.
After more than fifty overwhelmingly positive comments, Jin ran into an objection from Jon Hegeman, the executive at News Feed who by then had been promoted to head of the team. Yes, Jin was probably right that viral content was disproportionately worse than nonviral content, Hegeman wrote, but that didn’t mean that the stuff was bad on average. ... Hegeman was skeptical. If Jin was right, he responded, Facebook should probably be taking drastic steps like shutting down all reshares, and the company wasn’t in much of a mood to try. “If we remove a small percentage of reshares from people’s inventory,” Hegeman wrote, “they decide to come back to Facebook less.”
If Civic had thought Facebook’s leadership would be rattled by the discovery that the company’s growth efforts had been making Facebook’s integrity problems worse, they were wrong. Not only was Zuckerberg hostile to future anti-growth work; he was beginning to wonder whether some of the company’s past integrity efforts were misguided.Empowered to veto not just new integrity proposals but work that had long ago been approved, the Public Policy team began declaring that some failed to meet the company’s standards for “legitimacy.” Sparing Sharing, the demotion of content pushed by hyperactive users—already dialed down by 80 percent at its adoption—was set to be dialed back completely. (It was ultimately spared but further watered down.)
“We cannot assume links shared by people who shared a lot are bad,” a writeup of plans to undo the change said. (In practice, the effect of rolling back Sparing Sharing, even in its weakened form, was unambiguous. Views of “ideologically extreme content for users of all ideologies” would immediately rise by a double-digit percentage, with the bulk of the gains going to the far right.)
“Informed Sharing”—an initiative that had demoted content shared by people who hadn’t clicked on the posts in question, and which had proved successful in diminishing the spread of fake news—was also slated for decommissioning.
“Being less likely to share content after reading it is not a good indicator of integrity,” stated a document justifying the planned discontinuation.
A company spokeswoman denied numerous Integrity staffers’ contention that the Public Policy team had the ability to veto or roll back integrity changes, saying that Kaplan’s team was just one voice among many internally. But, regardless of who was calling the shots, the company’s trajectory was clear. Facebook wasn’t just slow-walking integrity work anymore. It was actively planning to undo large chunks of it.
Facebook could be certain of meeting its goals for the 2020 election if it was willing to slow down viral features. This could include imposing limits on reshares, message forwarding, and aggressive algorithmic amplification—the kind of steps that the Integrity teams throughout Facebook had been pushing to adopt for more than a year. The moves would be simple and cheap. Best of all, the methods had been tested and guaranteed success in combating longstanding problems.The correct choice was obvious, Jin suggested, but Facebook seemed strangely unwilling to take it. It would mean slowing down the platform’s growth, the one tenet that was inviolable.
“Today the bar to ship a pro-Integrity win (that may be negative to engagement) often is higher than the bar to ship pro-engagement win (that may be negative to Integrity),” Jin lamented. If the situation didn’t change, he warned, it risked a 2020 election disaster from “rampant harmful virality.”
Even including downranking, “we estimate that we may action as little as 3–5% of hate and 0.6% of [violence and incitement] on Facebook, despite being the best in the world at it,” one presentation noted. Jin knew these stats, according to people who worked with him, but was too polite to emphasize them.
Company researchers used multiple methods to demonstrate QAnon’s gravitational pull, but the simplest and most visceral proof came from setting up a test account and seeing where Facebook’s algorithms took it.After setting up a dummy account for “Carol”—a hypothetical forty-one-year-old conservative woman in Wilmington, North Carolina, whose interests included the Trump family, Fox News, Christianity, and parenting—the researcher watched as Facebook guided Carol from those mainstream interests toward darker places.
Within a day, Facebook’s recommendations had “devolved toward polarizing content.” Within a week, Facebook was pushing a “barrage of extreme, conspiratorial, and graphic content.” ... The researcher’s write-up included a plea for action: if Facebook was going to push content this hard, the company needed to get a lot more discriminating about what it pushed.
Later write-ups would acknowledge that such warnings went unheeded.
As executives filed out, Zuckerberg pulled Integrity’s Guy Rosen aside. “Why did you show me this in front of so many people?” Zuckerberg asked Rosen, who as Chakrabarti’s boss bore responsibility for his subordinate’s presentation landing on that day’s agenda.Zuckerberg had good reason to be unhappy that so many executives had watched him being told in plain terms that the forthcoming election was shaping up to be a disaster. In the course of investigating Cambridge Analytica, regulators around the world had already subpoenaed thousands of pages of documents from the company and had pushed for Zuckerberg’s personal communications going back for the better part of the decade. Facebook had paid $5 billion to the U.S. Federal Trade Commission to settle one of the most prominent inquiries, but the threat of subpoenas and depositions wasn’t going away. ... If there had been any doubt that Civic was the Integrity division’s problem child, lobbing such a damning document straight onto Zuckerberg’s desk settled it. As Chakrabarti later informed his deputies, Rosen told him that Civic would henceforth be required to run such material through other executives first—strictly for organizational reasons, of course.
Chakrabarti didn’t take the reining in well. A few months later, he wrote a scathing appraisal of Rosen’s leadership as part of the company’s semiannual performance review. Facebook’s top integrity official was, he wrote, “prioritizing PR risk over social harm.”
Facebook still hadn’t given Civic the green light to resume the fight against domestically coordinated political manipulation efforts. Its fact-checking program was too slow to effectively shut down the spread of misinformation during a crisis. And the company still hadn’t addressed the “perverse incentives” resulting from News Feed’s tendency to favor divisive posts. “Remains unclear if we have a societal responsibility to reduce exposure to this type of content,” an updated presentation from Civic tartly stated.“Samidh was trying to push Mark into making those decisions, but he didn’t take the bait,” Harbath recalled.
Cutler remarked that she would have pushed for Chakrabarti’s ouster if she didn’t expect a substantial portion of his team would mutiny. (The company denies Cutler said this.)
a British study had found that Instagram had the worst effect of any social media app on the health and well-being of teens and young adults.
The second was the death of Molly Russell, a fourteen-year-old from North London. Though “apparently flourishing,” as a later coroner’s inquest found, Russell had died by suicide in late 2017. Her death was treated as an inexplicable local tragedy until the BBC ran a report on social media activity in 2019. Russell had followed a large group of accounts that romanticized depression, self-harm, and suicide, and she had engaged with more than 2,100 macabre posts, mostly on Instagram. Her final login had come at 12:45 the morning she died.“I have no doubt that Instagram helped kill my daughter,” her father told the BBC.
Later research—both inside and outside Instagram—would demonstrate that a class of commercially motivated accounts had seized on depression-related content for the same reason that others focused on car crashes or fighting: the stuff pulled high engagement. But serving pro-suicide content to a vulnerable kid was clearly indefensible, and the platform pledged to remove and restrict the recommendation of such material, along with hiding hashtags like #Selfharm. Beyond exposing an operational failure, the extensive coverage of Russell’s death associated Instagram with rising concerns about teen mental health.
Though much attention, both inside and outside the company, had been paid to bullying, the most serious risks weren’t the result of people mistreating each other. Instead, the researchers wrote, harm arose when a user’s existing insecurities combined with Instagram’s mechanics. “Those who are dissatisfied with their lives are more negatively affected by the app,” one presentation noted, with the effects most pronounced among girls unhappy with their bodies and social standing.There was a logic here, one that teens themselves described to researchers. Instagram’s stream of content was a “highlight reel,” at once real life and unachievable. This was manageable for users who arrived in a good frame of mind, but it could be poisonous for those who showed up vulnerable. Seeing comments about how great an acquaintance looked in a photo would make a user who was unhappy about her weight feel bad—but it didn’t make her stop scrolling.
“They often feel ‘addicted’ and know that what they’re seeing is bad for their mental health but feel unable to stop themselves,” the “Teen Mental Health Deep Dive” presentation noted. Field research in the U.S. and U.K. found that more than 40 percent of Instagram users who felt “unattractive” traced that feeling to Instagram. Among American teens who said they had thought about dying by suicide in the past month, 6 percent said the feeling originated on the platform. In the U.K., the number was double that.
“Teens who struggle with mental health say Instagram makes it worse,” the presentation stated. “Young people know this, but they don’t adopt different patterns.”
These findings weren’t dispositive, but they were unpleasant, in no small part because they made sense. Teens said—and researchers appeared to accept—that certain features of Instagram could aggravate mental health issues in ways beyond its social media peers. Snapchat had a focus on silly filters and communication with friends, while TikTok was devoted to performance. Instagram, though? It revolved around bodies and lifestyle. The company disowned these findings after they were made public, calling the researchers’ apparent conclusion that Instagram could harm users with preexisting insecurities unreliable. The company would dispute allegations that it had buried negative research findings as “plain false.”
Facebook had deployed a comment-filtering system to prevent the heckling of public figures such as Zuckerberg during livestreams, burying not just curse words and complaints but also substantive discussion of any kind. The system had been tuned for sycophancy, and poorly at that. The irony of heavily censoring comments on a speech about free speech wasn’t hard to miss.
CrowdTangle’s rundown of that Tuesday’s top content had, it turned out, included a butthole. This wasn’t a borderline picture of someone’s ass. It was an unmistakable, up-close image of an anus. It hadn’t just gone big on Facebook—it had gone biggest. Holding the number one slot, it was the lead item that executives had seen when they opened Silverman’s email. “I hadn’t put Mark or Sheryl on it, but I basically put everyone else on there,” Silverman said.The picture was a thumbnail outtake from a porn video that had escaped Facebook’s automated filters. Such errors were to be expected, but was Facebook’s familiarity with its platform so poor that it wouldn’t notice when its systems started spreading that content to millions of people?
Yes, it unquestionably was.
In May, a data scientist working on integrity posted a Workplace note titled “Facebook Creating a Big Echo Chamber for ‘the Government and Public Health Officials Are Lying to Us’ Narrative—Do We Care?”Just a few months into the pandemic, groups devoted to opposing COVID lockdown measures had become some of the most widely viewed on the platform, pushing false claims about the pandemic under the guise of political activism. Beyond serving as an echo chamber for alternating claims that the virus was a Chinese plot and that the virus wasn’t real, the groups served as a staging area for platform-wide assaults on mainstream medical information. ... An analysis showed these groups had appeared abruptly, and while they had ties to well-established anti-vaccination communities, they weren’t arising organically. Many shared near-identical names and descriptions, and an analysis of their growth showed that “a relatively small number of people” were sending automated invitations to “hundreds or thousands of users per day.”
Most of this didn’t violate Facebook’s rules, the data scientist noted in his post. Claiming that COVID was a plot by Bill Gates to enrich himself from vaccines didn’t meet Facebook’s definition of “imminent harm.” But, he said, the company should think about whether it was merely reflecting a widespread skepticism of COVID or creating one.
“This is severely impacting public health attitudes,” a senior data scientist responded. “I have some upcoming survey data that suggests some baaaad results.”
President Trump was gearing up for reelection and he took to his platform of choice, Twitter, to launch what would become a monthslong attempt to undermine the legitimacy of the November 2020 election. “There is no way (ZERO!) that Mail-In Ballots will be anything less than substantially fraudulent,” Trump wrote. As was standard for Trump’s tweets, the message was cross-posted on Facebook.Under the tweet, Twitter included a small alert that encouraged users to “Get the facts about mail-in ballots.” Anyone clicking on it was informed that Trump’s allegations of a “rigged” election were false and there was no evidence that mail-in ballots posed a risk of fraud.
Twitter had drawn its line. Facebook now had to choose where it stood. Monika Bickert, Facebook’s head of Content Policy, declared that Trump’s post was right on the edge of the sort of misinformation about “methods for voting” that the company had already pledged to take down.
Zuckerberg didn’t have a strong position, so he went with his gut and left it up. But then he went on Fox News to attack Twitter for doing the opposite. “I just believe strongly that Facebook shouldn’t be the arbiter of truth of everything that people say online,” he told host Dana Perino. “Private companies probably shouldn’t be, especially these platform companies, shouldn’t be in the position of doing that.”
The interview caused some tumult inside Facebook. Why would Zuckerberg encourage Trump’s testing of the platform’s boundaries by declaring its tolerance of the post a matter of principle? The perception that Zuckerberg was kowtowing to Trump was about to get a lot worse. On the day of his Fox News interview, protests over the recent killing of George Floyd by Minneapolis police officers had gone national, and the following day the president tweeted that “when the looting starts, the shooting starts”—a notoriously menacing phrase used by a white Miami police chief during the civil rights era.
Declaring that Trump had violated its rules against glorifying violence, Twitter took the rare step of limiting the public’s ability to see the tweet—users had to click through a warning to view it, and they were prevented from liking or retweeting it.
Over on Facebook, where the message had been cross-posted as usual, the company’s classifier for violence and incitement estimated it had just under a 90 percent probability of breaking the platform’s rules—just shy of the threshold that would get a regular user’s post automatically deleted.
Trump wasn’t a regular user, of course. As a public figure, arguably the world’s most public figure, his account and posts were protected by dozens of different layers of safeguards.
Facebook drew up a list of accounts that were immune to some or all immediate enforcement actions. If those accounts appeared to break Facebook’s rules, the issue would go up the chain of Facebook’s hierarchy and a decision would be made on whether to take action against the account or not. Every social media platform ended up creating similar lists—it didn’t make sense to adjudicate complaints about heads of state, famous athletes, or persecuted human rights advocates in the same way the companies did with run-of-the-mill users. The problem was that, like a lot of things at Facebook, the company’s process got particularly messy.For Facebook, the risks that arose from shielding too few users were seen as far greater than the risks of shielding too many. Erroneously removing a bigshot’s content could unleash public hell—in Facebook parlance, a “media escalation” or, that most dreaded of events, a “PR fire.” Hours or days of coverage would follow when Facebook erroneously removed posts from breast cancer victims or activists of all stripes. When it took down a photo of a risqué French magazine cover posted to Instagram by the American singer Rihanna in 2014, it nearly caused an international incident. As internal reviews of the system later noted, the incentive was to shield as heavily as possible any account with enough clout to cause undue attention.
No one team oversaw XCheck, and the term didn’t even have a specific definition. There were endless varieties and gradations applied to advertisers, posts, pages, and politicians, with hundreds of engineers around the company coding different flavors of protections and tagging accounts as needed. Eventually, at least 6 million accounts and pages were enrolled into XCheck, with an internal guide stating that an entity should be “newsworthy,” “influential or popular,” or “PR risky” to qualify. On Instagram, XCheck even covered popular animal influencers, including Doug the Pug.
Any Facebook employee who knew the ropes could go into the system and flag accounts for special handling. XCheck was used by more than forty teams inside the company. Sometimes there were records of how they had deployed it and sometimes there were not. Later reviews would find that XCheck’s protections had been granted to “abusive accounts” and “persistent violators” of Facebook’s rules.
The job of giving a second review to violating content from high-profile users would require a sizable team of full-time employees. Facebook simply never staffed one. Flagged posts were put into a queue that no one ever considered, sweeping already once-validated complaints under the digital rug. “Because there was no governance or rigor, those queues might as well not have existed,” recalled someone who worked with the system. “The interest was in protecting the business, and that meant making sure we don’t take down a whale’s post.”
The stakes could be high. XCheck protected high-profile accounts, including in Myanmar, where public figures were using Facebook to incite genocide. It shielded the account of British far-right figure Tommy Robinson, an investigation by Britain’s Channel Four revealed in 2018.
One of the most explosive cases was that of Brazilian soccer star Neymar, whose 150 million Instagram followers placed him among the platform’s top twenty influencers. After a woman accused Neymar of rape in 2019, he accused the woman of extorting him and posted Facebook and Instagram videos defending himself—and showing viewers his WhatsApp correspondence with his accuser, which included her name and nude photos of her. Facebook’s procedure for handling the posting of “non-consensual intimate imagery” was simple: delete it. But Neymar was protected by XCheck. For more than a day, the system blocked Facebook’s moderators from removing the video. An internal review of the incident found that 56 million Facebook and Instagram users saw what Facebook described in a separate document as “revenge porn,” exposing the woman to what an employee referred to in the review as “ongoing abuse” from other users.
Facebook’s operational guidelines stipulate that not only should unauthorized nude photos be deleted, but people who post them should have their accounts deleted. Faced with the prospect of scrubbing one of the world’s most famous athletes from its platform, Facebook blinked.
“After escalating the case to leadership,” the review said, “we decided to leave Neymar’s accounts active, a departure from our usual ‘one strike’ profile disable policy.”
Facebook knew that providing preferential treatment to famous and powerful users was problematic at best and unacceptable at worst. “Unlike the rest of our community, these people can violate our standards without any consequences,” a 2019 review noted, calling the system “not publicly defensible.”
Nowhere did XCheck interventions occur more than in American politics, especially on the right.
When a high-enough-profile account was conclusively found to have broken Facebook’s rules, the company would delay taking action for twenty-four hours, during which it tried to convince the offending party to remove the offending post voluntarily. The program served as an invitation for privileged accounts to play at the edge of Facebook’s tolerance. If they crossed the line, they could simply take it back, having already gotten most of the traffic they would receive anyway. (Along with Diamond and Silk, every member of Congress ended up being granted the self-remediation window.)Sometimes Kaplan himself got directly involved. According to documents first obtained by BuzzFeed, the global head of Public Policy was not above either pushing employees to lift penalties against high-profile conservatives for spreading false information or leaning on Facebook’s fact-checkers to alter their verdicts.
An understanding began to dawn among the politically powerful: if you mattered enough, Facebook would often cut you slack. Prominent entities rightly treated any significant punishment as a sign that Facebook didn’t consider them worthy of white-glove treatment. To prove the company wrong, they would scream as loudly as they could in response.
“Some of these people were real gems,” recalled Harbath. In Facebook’s Washington, DC, office, staffers would explicitly justify blocking penalties against “Activist Mommy,” a Midwestern Christian account with a penchant for anti-gay rhetoric, because she would immediately go to the conservative press.
Facebook’s fear of messing up with a major public figure was so great that some achieved a status beyond XCheck and were whitelisted altogether, rendering even their most vile content immune from penalties, downranking, and, in some cases, even internal review.
Other Civic colleagues and Integrity staffers piled into the comments section to concur. “If our goal, was say something like: have less hate, violence etc. on our platform to begin with instead of remove more hate, violence etc. our solutions and investments would probably look quite different,” one wrote.Rosen was getting tired of dealing with Civic. Zuckerberg, who famously did not like to revisit decisions once they were made, had already dictated his preferred approach: automatically remove content if Facebook’s classifiers were highly confident that it broke the platform’s rules and take “soft” actions such as demotions when the systems predicted a violation was more likely than not. These were the marching orders and the only productive path forward was to diligently execute them.
The week before, the Wall Street Journal had published a story my colleague Newley Purnell and I cowrote about how Facebook had exempted a firebrand Hindu politician from its hate speech enforcement. There had been no question that Raja Singh, a member of the Telangana state parliament, was inciting violence. He gave speeches calling for Rohingya immigrants who fled genocide in Myanmar to be shot, branded all Indian Muslims traitors, and threatened to raze mosques. He did these things while building an audience of more than 400,000 followers on Facebook. Earlier that year, police in Hyderabad had placed him under house arrest to prevent him from leading supporters to the scene of recent religious violence.That Facebook did nothing in the face of such rhetoric could have been due to negligence—there were a lot of firebrand politicians offering a lot of incitement in a lot of different languages around the world. But in this case, Facebook was well aware of Singh’s behavior. Indian civil rights groups had brought him to the attention of staff in both Delhi and Menlo Park as part of their efforts to pressure the company to act against hate speech in the country.
There was no question whether Singh qualified as a “dangerous individual,” someone who would normally be barred from having a presence on Facebook’s platforms. Despite the internal conclusion that Singh and several other Hindu nationalist figures were creating a risk of actual bloodshed, their designation as hate figures had been blocked by Ankhi Das, Facebook’s head of Indian Public Policy—the same executive who had lobbied years earlier to reinstate BJP-associated pages after Civic had fought to take them down.
Das, whose job included lobbying India’s government on Facebook’s behalf, didn’t bother trying to justify protecting Singh and other Hindu nationalists on technical or procedural grounds. She flatly said that designating them as hate figures would anger the government, and the ruling BJP, so the company would not be doing it. ... Following our story, Facebook India’s then–managing director Ajit Mohan assured the company’s Muslim employees that we had gotten it wrong. Facebook removed hate speech “as soon as it became aware of it” and would never compromise its community standards for political purposes. “While we know there is more to do, we are making progress every day,” he wrote.
It was after we published the story that Kiran (a pseudonym) reached out to me. They wanted to make clear that our story in the Journal had just scratched the surface. Das’s ties with the government were far tighter than we understood, they said, and Facebook India was protecting entities much more dangerous than Singh.
“Hindus, come out. Die or kill,” one prominent activist had declared during a Facebook livestream, according to a later report by retired Indian civil servants. The ensuing violence left fifty-three people dead and swaths of northeastern Delhi burned.
The researcher set up a dummy account while traveling. Because the platform factored a user’s geography into content recommendations, she and a colleague noted in a writeup of her findings, it was the only way to get a true read on what the platform was serving up to a new Indian user.Ominously, her summary of what Facebook had recommended to their notional twenty-one-year-old Indian woman began with a trigger warning for graphic violence. While Facebook’s push of American test users toward conspiracy theories had been concerning, the Indian version was dystopian.
“In the 3 weeks since the account has been opened, by following just this recommended content, the test user’s News Feed has become a near constant barrage of polarizing nationalist content, misinformation, and violence and gore,” the note stated. The dummy account’s feed had turned especially dark after border skirmishes between Pakistan and India in early 2019. Amid a period of extreme military tensions, Facebook funneled the user toward groups filled with content promoting full-scale war and mocking images of corpses with laughing emojis.
This wasn’t a case of bad posts slipping past Facebook’s defenses, or one Indian user going down a nationalistic rabbit hole. What Facebook was recommending to the young woman had been bad from the start. The platform had pushed her to join groups clogged with images of corpses, watch purported footage of fictional air strikes, and congratulate nonexistent fighter pilots on their bravery.
“I’ve seen more images of dead people in the past three weeks than I’ve seen in my entire life, total,” the researcher wrote, noting that the platform had allowed falsehoods, dehumanizing rhetoric, and violence to “totally take over during a major crisis event.” Facebook needed to consider not only how its recommendation systems were affecting “users who are different from us,” she concluded, but rethink how it built its products for “non-US contexts.”
India was not an outlier. Outside of English-speaking countries and Western Europe, users routinely saw more cruelty, engagement bait, and falsehoods. Perhaps differing cultural senses of propriety explained some of the gap, but a lot clearly stemmed from differences in investment and concern.
This wasn’t supposed to be legal in the Gulf under the gray-market labor sponsorship system known as kafala, but the internet had removed the friction from buying people. Undercover reporters from BBC Arabic posed as a Kuwaiti couple and negotiated to buy a sixteen-year-old girl whose seller boasted about never allowing her to leave the house.Everyone told the BBC they were horrified. Kuwaiti police rescued the girl and sent her home. Apple and Google pledged to root out the abuse, and the bartering apps cited in the story deleted their “domestic help” sections. Facebook pledged to take action and deleted a popular hashtag used to advertise maids for sale.
After that, the company largely dropped the matter. But Apple turned out to have a longer attention span. In October, after sending Facebook numerous examples of ongoing maid sales via Instagram, it threatened to remove Facebook’s products from its App Store.
Unlike human trafficking, this, to Facebook, was a real crisis.
“Removing our applications from Apple’s platforms would have had potentially severe consequences to the business, including depriving millions of users of access to IG & FB,” an internal report on the incident stated.
With alarm bells ringing at the highest levels, the company found and deleted an astonishing 133,000 posts, groups, and accounts related to the practice within days. It also performed a quick revamp of its policies, reversing a previous rule allowing the sale of maids through “brick and mortar” businesses. (To avoid upsetting the sensibilities of Gulf State “partners,” the company had previously permitted the advertising and sale of servants by businesses with a physical address.) Facebook also committed to “holistic enforcement against any and all content promoting domestic servitude,” according to the memo.
Apple lifted its threat, but again Facebook wouldn’t live up to its pledges. Two years later, in late 2021, an Integrity staffer would write up an investigation titled “Domestic Servitude: This Shouldn’t Happen on FB and How We Can Fix It.” Focused on the Philippines, the memo described how fly-by-night employment agencies were recruiting women with “unrealistic promises” and then selling them into debt bondage overseas. If Instagram was where domestic servants were sold, Facebook was where they were recruited.
Accessing the direct-messaging inboxes of the placing agencies, the staffer found Filipina domestic servants pleading for help. Some reported rape or sent pictures of bruises from being hit. Others hadn’t been paid in months. Still others reported being locked up and starved. The labor agencies didn’t help.
The passionately worded memo, and others like it, listed numerous things the company could do to prevent the abuse. There were improvements to classifiers, policy changes, and public service announcements to run. Using machine learning, Facebook could identify Filipinas who were looking for overseas work and then inform them of how to spot red flags in job postings. In Persian Gulf countries, Instagram could run PSAs about workers’ rights.
These things largely didn’t happen for a host of reasons. One memo noted a concern that, if worded too strongly, Arabic-language PSAs admonishing against the abuse of domestic servants might “alienate buyers” of them. But the main obstacle, according to people familiar with the team, was simply resources. The team devoted full-time to human trafficking—which included not just the smuggling of people for labor and sex but also the sale of human organs—amounted to a half-dozen people worldwide. The team simply wasn’t large enough to knock this stuff out.
“We’re largely blind to problems on our site,” Leach’s presentation wrote of Ethiopia.Facebook employees produced a lot of internal work like this: declarations that the company had gotten in over its head, unable to provide even basic remediation to potentially horrific problems. Events on the platform could foreseeably lead to loss of life and almost certainly did, according to human rights groups monitoring Ethiopia. Meareg Amare, a university lecturer in Addis Ababa, was murdered outside his home one month after a post went viral, receiving 35,000 likes, listing his home address and calling for him to be attacked. Facebook failed to remove it. His family is now suing the company.
As it so often did, the company was choosing growth over quality. Efforts to expand service to poorer and more isolated places would not wait for user protections to catch up, and, even in countries at “dire” risk of mass atrocities, the At Risk Countries team needed approval to do things that harmed engagement.
Documents and transcripts of internal meetings among the company’s American staff show employees struggling to explain why Facebook wasn’t following its normal playbook when dealing with hate speech, the coordination of violence, and government manipulation in India. Employees in Menlo Park discussed the BJP’s promotion of the “Love Jihad” lie. They met with human rights organizations that documented the violence committed by the platform’s cow-protection vigilantes. And they tracked efforts by the Indian government and its allies to manipulate the platform via networks of accounts. Yet nothing changed.“We have a lot of business in India, yeah. And we have connections with the government, I guess, so there are some sensitivities around doing a mitigation in India,” one employee told another about the company’s protracted failure to address abusive behavior by an Indian intelligence service.
During another meeting, a team working on what it called the problem of “politicized hate” informed colleagues that the BJP and its allies were coordinating both the “Love Jihad” slander and another hashtag, #CoronaJihad, premised on the idea that Muslims were infecting Hindus with COVID via halal food.
The Rashtriya Swayamsevak Sangh, or RSS—the umbrella Hindu nationalist movement of which the BJP is the political arm—was promoting these slanders through 6,000 or 7,000 different entities on the platform, with the goal of portraying Indian Muslims as subhuman, the presenter explained. Some of the posts said that the Quran encouraged Muslim men to rape their female family members.
“What they’re doing really permeates Indian society,” the presenter noted, calling it part of a “larger war.”
A colleague at the meeting asked the obvious question. Given the company’s conclusive knowledge of the coordinated hate campaign, why hadn’t the posts or accounts been taken down?
“Ummm, the answer that I’ve received for the past year and a half is that it’s too politically sensitive to take down RSS content as hate,” the presenter said.
Nothing needed to be said in response.
“I see your face,” the presenter said. “And I totally agree.”
One incident in particular, involving a local political candidate, stuck out. As Kiran recalled it, the guy was a little fish, a Hindu nationalist activist who hadn’t achieved Raja Singh’s six-digit follower count but was still a provocateur. The man’s truly abhorrent behavior had been repeatedly flagged by lower-level moderators, but somehow the company always seemed to give it a pass.This time was different. The activist had streamed a video in which he and some accomplices kidnapped a man who, they informed the camera, had killed a cow. They took their captive to a construction site and assaulted him while Facebook users heartily cheered in the comments section.
Zuckerberg launched an internal campaign against social media overenforcement. Ordering the creation of a team dedicated to preventing wrongful content takedowns, Zuckerberg demanded regular briefings on its progress from senior employees. He also suggested that, instead of rigidly enforcing platform rules on content in Groups, Facebook should defer more to the sensibilities of the users in them. In response, a staffer proposed entirely exempting private groups from enforcement for “low-tier hate speech.”
The stuff was viscerally terrible—people clamoring for lynchings and civil war. One group was filled with “enthusiastic calls for violence every day.” Another top group claimed it was set up by Trump-supporting patriots but was actually run by “financially motivated Albanians” directing a million views daily to fake news stories and other provocative content.The comments were often worse than the posts themselves, and even this was by design. The content of the posts would be incendiary but fall just shy of Facebook’s boundaries for removal—it would be bad enough, however, to harvest user anger, classic “hate bait.” The administrators were professionals, and they understood the platform’s weaknesses every bit as well as Civic did. In News Feed, anger would rise like a hot-air balloon, and such comments could take a group to the top.
Public Policy had previously refused to act on hate bait
We have heavily overpromised regarding our ability to moderate content on the platform,” one data scientist wrote to Rosen in September. “We are breaking and will continue to break our recent promises.”
The longstanding conflicts between Civic and Facebook’s Product, Policy, and leadership teams had boiled over in the wake of the “looting/shooting” furor, and executives—minus Chakrabarti—had privately begun discussing how to address what was now unquestionably viewed as a rogue Integrity operation. Civic, with its dedicated engineering staff, hefty research operation, and self-chosen mission statement, was on the chopping block.
The group had grown to more than 360,000 members less than twenty-four hours later when Facebook took it down, citing “extraordinary measures.” Pushing false claims of election fraud to a mass audience at a time when armed men were calling for a halt to vote counting outside tabulation centers was an obvious problem, and one that the company knew was only going to get bigger. Stop the Steal had an additional 2.1 million users pending admission to the group when Facebook pulled the plug.Facebook’s leadership would describe Stop the Steal’s growth as unprecedented, though Civic staffers could be forgiven for not sharing their sense of surprise.
Zuckerberg had accepted the deletion under emergency circumstances, but he didn’t want the Stop the Steal group’s removal to become a precedent for a backdoor ban on false election claims. During the run-up to Election Day, Facebook had removed only lies about the actual voting process—stuff like “Democrats vote on Wednesday” and “People with outstanding parking tickets can’t go to the polls.” Noting the thin distinction between the claim that votes wouldn’t be counted and that they wouldn’t be counted accurately, Chakrabarti had pushed to take at least some action against baseless election fraud claims.Civic hadn’t won that fight, but with the Stop the Steal group spawning dozens of similarly named copycats—some of which also accrued six-figure memberships—the threat of further organized election delegitimization efforts was obvious.
Barred from shutting down the new entities, Civic assigned staff to at least study them. Staff also began tracking top delegitimization posts, which were earning tens of millions of views, for what one document described as “situational awareness.” A later analysis found that as much as 70 percent of Stop the Steal content was coming from known “low news ecosystem quality” pages, the commercially driven publishers that Facebook’s News Feed integrity staffers had been trying to fight for years.
Zuckerberg overruled both Facebook’s Civic team and its head of counterterrorism. Shortly after the Associated Press called the presidential election for Joe Biden on November 7—the traditional marker for the race being definitively over—Molly Cutler assembled roughly fifteen executives that had been responsible for the company’s election preparation. Citing orders from Zuckerberg, she said the election delegitimization monitoring was to immediately stop.
On December 17, a data scientist flagged that a system responsible for either deleting or restricting high-profile posts that violated Facebook’s rules had stopped doing so. Colleagues ignored it, assuming that the problem was just a “logging issue”—meaning the system still worked, it just wasn’t recording its actions. On the list of Facebook’s engineering priorities, fixing that didn’t rate.In fact, the system truly had failed, in early November. Between then and when engineers realized their error in mid-January, the system had given a pass to 3,100 highly viral posts that should have been deleted or labeled “disturbing.”
Glitches like that happened all the time at Facebook. Unfortunately, this one produced an additional 8 billion “regrettable” views globally, instances in which Facebook had shown users content that it knew was trouble. The company would later say that only a small minority of the 8 billion “regrettable” content views touched on American politics, and that the mistake was immaterial to subsequent events. A later review of Facebook’s post-election work tartly described the flub as a “lowlight” of the platform’s 2020 election performance, though the company disputes that it had a meaningful impact. At least 7 billion of the bad content views were international, the company says, and of the American material only a portion dealt with politics. Overall, a spokeswoman said, the company remains proud of its pre- and post-election safety work.
Zuckerberg vehemently disagreed with people who said that the COVID vaccine was unsafe, but he supported their right to say it, including on Facebook. ... Under Facebook’s policy, health misinformation about COVID was to be removed only if it posed an imminent risk of harm, such as a post telling infected people to drink bleach ... A researcher randomly sampled English-language comments containing phrases related to COVID and vaccines. A full two-thirds were anti-vax. The researcher’s memo compared that figure to public polling showing the prevalence of anti-vaccine sentiment in the U.S.—it was a full 40 points lower.Additional research found that a small number of “big whales” was behind a large portion of all anti-vaccine content on the platform. Of 150,000 posters in Facebook groups that were eventually disabled for COVID misinformation, just 5 percent were producing half of all posts. And just 1,400 users were responsible for inviting half of all members. “We found, like many problems at FB, this is a head-heavy problem with a relatively few number of actors creating a large percentage of the content and growth,” Facebook researchers would later note.
One of the anti-vax brigade’s favored tactics was to piggyback on posts from entities like UNICEF and the World Health Organization encouraging vaccination, which Facebook was promoting free of charge. Anti-vax activists would respond with misinformation or derision in the comments section of these posts, then boost one another’s hostile comments toward the top slot
Even as Facebook prepared for virally driven crises to become routine, the company’s leadership was becoming increasingly comfortable absolving its products of responsibility for feeding them. By the spring of 2021, it wasn’t just Boz arguing that January 6 was someone else’s problem. Sandberg suggested that January 6 was “largely organized on platforms that don’t have our abilities to stop hate.” Zuckerberg told Congress that they need not cast blame beyond Trump and the rioters themselves. “The country is deeply divided right now and that is not something that tech alone can fix,” he said.In some instances, the company appears to have publicly cited research in what its own staff had warned were inappropriate ways. A June 2020 review of both internal and external research had warned that the company should avoid arguing that higher rates of polarization among the elderly—the demographic that used social media least—was proof that Facebook wasn’t causing polarization.
Though the argument was favorable to Facebook, researchers wrote, Nick Clegg should avoid citing it in an upcoming opinion piece because “internal research points to an opposite conclusion.” Facebook, it turned out, fed false information to senior citizens at such a massive rate that they consumed far more of it despite spending less time on the platform. Rather than vindicating Facebook, the researchers wrote, “the stronger growth of polarization for older users may be driven in part by Facebook use.”
All the researchers wanted was for executives to avoid parroting a claim that Facebook knew to be wrong, but they didn’t get their wish. The company says the argument never reached Clegg. When he published a March 31, 2021, Medium essay titled “You and the Algorithm: It Takes Two to Tango,” he cited the internally debunked claim among the “credible recent studies” disproving that “we have simply been manipulated by machines all along.” (The company would later say that the appropriate takeaway from Clegg’s essay on polarization was that “research on the topic is mixed.”)
Such bad-faith arguments sat poorly with researchers who had worked on polarization and analyses of Stop the Steal, but Clegg was a former politician hired to defend Facebook, after all. The real shock came from an internally published research review written by Chris Cox.
Titled “What We Know About Polarization,” the April 2021 Workplace memo noted that the subject remained “an albatross public narrative,” with Facebook accused of “driving societies into contexts where they can’t trust each other, can’t share common ground, can’t have conversations about issues, and can’t share a common view on reality.”
But Cox and his coauthor, Facebook Research head Pratiti Raychoudhury, were happy to report that a thorough review of the available evidence showed that this “media narrative” was unfounded. The evidence that social media played a contributing role in polarization, they wrote, was “mixed at best.” Though Facebook likely wasn’t at fault, Cox and Raychoudhury wrote, the company was still trying to help, in part by encouraging people to join Facebook groups. “We believe that groups are on balance a positive, depolarizing force,” the review stated.
The writeup was remarkable for its choice of sources. Cox’s note cited stories by New York Times columnists David Brooks and Ezra Klein alongside early publicly released Facebook research that the company’s own staff had concluded was no longer accurate. At the same time, it omitted the company’s past conclusions, affirmed in another literature review just ten months before, that Facebook’s recommendation systems encouraged bombastic rhetoric from publishers and politicians, as well as previous work finding that seeing vicious posts made users report “more anger towards people with different social, political, or cultural beliefs.” While nobody could reliably say how Facebook altered users’ off-platform behavior, how the company shaped their social media activity was accepted fact. “The more misinformation a person is exposed to on Instagram the more trust they have in the information they see on Instagram,” company researchers had concluded in late 2020.
In a statement, the company called the presentation “comprehensive” and noted that partisan divisions in society arose “long before platforms like Facebook even existed.” For staffers that Cox had once assigned to work on addressing known problems of polarization, his note was a punch to the gut.
In 2016, the New York Times had reported that Facebook was quietly working on a censorship tool in an effort to gain entry to the Chinese market. While the story was a monster, it didn’t come as a surprise to many people inside the company. Four months earlier, an engineer had discovered that another team had modified a spam-fighting tool in a way that would allow an outside party control over content moderation in specific geographic regions. In response, he had resigned, leaving behind a badge post correctly surmising that the code was meant to loop in Chinese censors.With a literary mic drop, the post closed out with a quote on ethics from Charlotte Brontë’s Jane Eyre: “Laws and principles are not for the times when there is no temptation: they are for such moments as this, when body and soul rise in mutiny against their rigour; stringent are they; inviolate they shall be. If at my individual convenience I might break them, what would be their worth?”
Garnering 1,100 reactions, 132 comments, and 57 shares, the post took the program from top secret to open secret. Its author had just pioneered a new template: the hard-hitting Facebook farewell.
That particular farewell came during a time when Facebook’s employee satisfaction surveys were generally positive, before the time of endless crisis, when societal concerns became top of mind. In the intervening years, Facebook had hired a massive base of Integrity employees to work on those issues, and seriously pissed off a nontrivial portion of them.
Consequently, some badge posts began to take on a more mutinous tone. Staffers who had done groundbreaking work on radicalization, human trafficking, and misinformation would summarize both their accomplishments and where they believed the company had come up short on technical and moral grounds. Some broadsides against the company ended on a hopeful note, including detailed, jargon-light instructions for how, in the future, their successors could resurrect the work.
These posts were gold mines for Haugen, connecting product proposals, experimental results, and ideas in ways that would have been impossible for an outsider to re-create. She photographed not just the posts themselves but the material they linked to, following the threads to other topics and documents. A half dozen were truly incredible, unauthorized chronicles of Facebook’s dawning understanding of the way its design determined what its users consumed and shared. The authors of these documents hadn’t been trying to push Facebook toward social engineering—they had been warning that the company had already wandered into doing so and was now neck deep.
The researchers’ best understanding was summarized this way: “We make body image issues worse for one in three teen girls.”
In 2020, Instagram’s Well-Being team had run a study of massive scope, surveying 100,000 users in nine countries about negative social comparison on Instagram. The researchers then paired the answers with individualized data on how each user who took the survey had behaved on Instagram, including how and what they posted. They found that, for a sizable minority of users, especially those in Western countries, Instagram was a rough place. Ten percent reported that they “often or always” felt worse about themselves after using the platform, and a quarter believed Instagram made negative comparison worse.Their findings were incredibly granular. They found that fashion and beauty content produced negative feelings in ways that adjacent content like fitness did not. They found that “people feel worse when they see more celebrities in feed,” and that Kylie Jenner seemed to be unusually triggering, while Dwayne “The Rock” Johnson was no trouble at all. They found that people judged themselves far more harshly against friends than celebrities. A movie star’s post needed 10,000 likes before it caused social comparison, whereas, for a peer, the number was ten.
In order to confront these findings, the Well-Being team suggested that the company cut back on recommending celebrities for people to follow, or reweight Instagram’s feed to include less celebrity and fashion content, or de-emphasize comments about people’s appearance. As a fellow employee noted in response to summaries of these proposals on Workplace, the Well-Being team was suggesting that Instagram become less like Instagram.
“Isn’t that what IG is mostly about?” the man wrote. “Getting a peek at the (very photogenic) life of the top 0.1%? Isn’t that the reason why teens are on the platform?”
“We are practically not doing anything,” the researchers had written, noting that Instagram wasn’t currently able to stop itself from promoting underweight influencers and aggressive dieting. A test account that signaled an interest in eating disorder content filled up with pictures of thigh gaps and emaciated limbs.The problem would be relatively easy for outsiders to document. Instagram was, the research warned, “getting away with it because no one has decided to dial into it.”
He began the presentation by noting that 51 percent of Instagram users reported having a “bad or harmful” experience on the platform in the previous seven days. But only 1 percent of those users reported the objectionable content to the company, and Instagram took action in 2 percent of those cases. The math meant that the platform remediated only 0.02 percent of what upset users—just one bad experience out of every 5,000.“The numbers are probably similar on Facebook,” he noted, calling the statistics evidence of the company’s failure to understand the experiences of users such as his own daughter. Now sixteen, she had recently been told to “get back to the kitchen” after she posted about cars, Bejar said, and she continued receiving the unsolicited dick pics she had been getting since the age of fourteen. “I asked her why boys keep doing that? She said if the only thing that happens is they get blocked, why wouldn’t they?”
Two years of research had confirmed that Joanna Bejar’s logic was sound. On a weekly basis, 24 percent of all Instagram users between the ages of thirteen and fifteen received unsolicited advances, Bejar informed the executives. Most of that abuse didn’t violate the company’s policies, and Instagram rarely caught the portion that did.
nothing highlighted the costs better than a Twitter bot set up by New York Times reporter Kevin Roose. Using methodology created with the help of a CrowdTangle staffer, Roose found a clever way to put together a daily top ten of the platform’s highest-engagement content in the United States, producing a leaderboard that demonstrated how thoroughly partisan publishers and viral content aggregators dominated the engagement signals that Facebook valued most.The degree to which that single automated Twitter account got under the skin of Facebook’s leadership would be difficult to overstate. Alex Schultz, the VP who oversaw Facebook’s Growth team, was especially incensed—partly because he considered raw engagement counts to be misleading, but more because it was Facebook’s own tool reminding the world every morning at 9:00 a.m. Pacific that the platform’s content was trash.
“The reaction was to prove the data wrong,” recalled Brian Boland. But efforts to employ other methodologies only produced top ten lists that were nearly as unflattering. Schultz began lobbying to kill off CrowdTangle altogether, replacing it with periodic top content reports of its own design. That would still be more transparency than any of Facebook’s rivals offered, Schultz noted
...
Schultz handily won the fight. In April 2021, Silverman convened his staff on a conference call and told them that CrowdTangle’s team was being disbanded. ... “Boz would just say, ‘You’re completely off base,’ ” Boland said. “Data wins arguments at Facebook, except for this one.”
When the company issued its response later in May, I read the document with a clenched jaw. Facebook had agreed to grant the board’s request for information about XCheck and “any exceptional processes that apply to influential users.”...
“We want to make clear that we remove content from Facebook, no matter who posts it,” Facebook’s response to the Oversight Board read. “Cross check simply means that we give some content from certain Pages or Profiles additional review.”
There was no mention of whitelisting, of C-suite interventions to protect famous athletes, of queues of likely violating posts from VIPs that never got reviewed. Although our documents showed that at least 7 million of the platform’s most prominent users were shielded
by some form of XCheck, Facebook assured the board that it applied to only “a small number of decisions.” The only XCheck-related request that Facebook didn’t address was for data that might show whether XChecked users had received preferential treatment.
“It is not feasible to track this information,” Facebook responded, neglecting to mention that it was exempting some users from enforcement entirely.
“I’m sure many of you have found the recent coverage hard to read because it just doesn’t reflect the company we know,” he wrote in a note to employees that was also shared on Facebook. The allegations didn’t even make sense, he wrote: “I don’t know any tech company that sets out to build products that make people angry or depressed.”Zuckerberg said he worried the leaks would discourage the tech industry at large from honestly assessing their products’ impact on the world, in order to avoid the risk that internal research might be used against them. But he assured his employees that their company’s internal research efforts would stand strong. “Even though it might be easier for us to follow that path, we’re going to keep doing research because it’s the right thing to do,” he wrote.
By the time Zuckerberg made that pledge, research documents were already disappearing from the company’s internal systems. Had a curious employee wanted to double-check Zuckerberg’s claims about the company’s polarization work, for example, they would have found that key research and experimentation data had become inaccessible.
The crackdown had begun.
One memo required researchers to seek special approval before delving into anything on a list of topics requiring “mandatory oversight”—even as a manager acknowledged that the company did not maintain such a list.
The “Narrative Excellence” memo and its accompanying notes and charts were a guide to producing documents that reporters like me wouldn’t be excited to see. Unfortunately, as a few bold user experience researchers noted in the replies, achieving Narrative Excellence was all but incompatible with succeeding at their jobs. Writing things that were “safer to be leaked” meant writing things that would have less impact.
I really like the "non-goals" section of design docs. I think the analogous non-statements section of a doc like this is much less valuable because the top-level non-statements can generally be inferred by reading this doc, whereas top-level non-goals often add information, but I figured I'd try this out anyway.
when the WSJ looked at leaked internal Meta documents, they found, among other things, that Meta estimated that 100k minors per day "received photos of adult genitalia or other sexually abusive content". Of course, smart contrarians will argue that this is totally normal, e.g., two of the first few comments on HN were about how there's nothing particularly wrong with this. Sure, it's bad for children to get harassed, but "it can happen on any street corner", "what's the base rate to compare against", etc.
Very loosely, if we're liberal, we might estimate that Meta had 2.5B DAU in early 2021 and 500M were minors, or if we're conservative, maybe we guess that 100M are minors. So, we might guess that Meta estimated something like 0.1% to 0.02% of minors on Meta platforms received photos of genitals or similar each day. Is this roughly the normal rate they would experience elsewhere? Compared to the real world, possibly, although I would be surprised if 0.1% of children are being exposed to people's genitals "on any street corner". Compared to a well moderated small forum, that seems highly implausible. The internet commenter reaction was the same reaction that Arturo Bejar, who designed Facebook's reporting system and worked in the area, had. He initially dismissed reports about this kind of thing because it didn't seem plausible that it could really be that bad, but he quickly changed his mind once he started looking into it:
Joanna’s account became moderately successful, and that’s when things got a little dark. Most of her followers were enthused about a [14-year old] girl getting into car restoration, but some showed up with rank misogyny, like the guy who told Joanna she was getting attention “just because you have tits.”
“Please don’t talk about my underage tits,” Joanna Bejar shot back before reporting the comment to Instagram. A few days later, Instagram notified her that the platform had reviewed the man’s comment. It didn’t violate the platform’s community standards.
Bejar, who had designed the predecessor to the user-reporting system that had just shrugged off the sexual harassment of his daughter, told her the decision was a fluke. But a few months later, Joanna mentioned to Bejar that a kid from a high school in a neighboring town had sent her a picture of his penis via an Instagram direct message. Most of Joanna’s friends had already received similar pics, she told her dad, and they all just tried to ignore them.
Bejar was floored. The teens exposing themselves to girls who they had never met were creeps, but they presumably weren’t whipping out their dicks when they passed a girl in a school parking lot or in the aisle of a convenience store. Why had Instagram become a place where it was accepted that these boys occasionally would—or that young women like his daughter would have to shrug it off?
Much of the book, Broken Code, is about Bejar and others trying to get Meta to take problems like this seriously and making little progress and often having their progress undone (although, PR issues for FB seem to force FB's hand and drive some progress towards the end of the book):
six months prior, a team had redesigned Facebook’s reporting system with the specific goal of reducing the number of completed user reports so that Facebook wouldn’t have to bother with them, freeing up resources that could otherwise be invested in training its artificial intelligence–driven content moderation systems. In a memo about efforts to keep the costs of hate speech moderation under control, a manager acknowledged that Facebook might have overdone its effort to stanch the flow of user reports: “We may have moved the needle too far,” he wrote, suggesting that perhaps the company might not want to suppress them so thoroughly.
The company would later say that it was trying to improve the quality of reports, not stifle them. But Bejar didn’t have to see that memo to recognize bad faith. The cheery blue button was enough. He put down his phone, stunned. This wasn’t how Facebook was supposed to work. How could the platform care about its users if it didn’t care enough to listen to what they found upsetting?
There was an arrogance here, an assumption that Facebook’s algorithms didn’t even need to hear about what users experienced to know what they wanted. And even if regular users couldn’t see that like Bejar could, they would end up getting the message. People like his daughter and her friends would report horrible things a few times before realizing that Facebook wasn’t interested. Then they would stop.
If you're interested in the topic, I'd recommend reading the whole book, but if you just want to get a flavor for the kinds of things the book discusses, I've put a few relevant quotes into an appendix. After reading the book, I can't say that I'm very sure the number is correct because I'd have to look at the data to be strongly convinced, but it does seem plausible. And as for why Facebook might expose children to more of this kind of thing than another platform, the book makes the case that this falls out of a combination of optimizing for engagement, "number go up", and neglecting "trust and safety" work
[return]Only a few hours of poking around Instagram and a handful of phone calls were necessary to see that something had gone very wrong—the sort of people leaving vile comments on teenagers’ posts weren’t lone wolves. They were part of a large-scale pedophilic community fed by Instagram’s recommendation systems.
Further reporting led to an initial three-thousand-word story headlined “Instagram Connects Vast Pedophile Network.” Co-written with Katherine Blunt, the story detailed how Instagram’s recommendation systems were helping to create a pedophilic community, matching users interested in underage sex content with each other and with accounts advertising “menus” of content for sale. Instagram’s search bar actively suggested terms associated with child sexual exploitation, and even glancing contact with accounts with names like Incest Toddlers was enough to trigger Instagram to begin pushing users to connect with them.
Another reason, less reasonable, but the actual impetus for this post, is that when Zuckerberg made his comments that only the absolute largest companies in the world can handle issues like fraud and spam, it struck me as completely absurd and, because I enjoy absurdity, I started a doc where I recorded links I saw to large company spam, fraud, moderation, and support, failures, much like the list of Google knowledge card results I kept track of for a while. I didn't have a plan for what to do with that and just kept it going for years before I decided to publish the list, at which point I felt that I had to write something, since the bare list by itself isn't that interesting, so I started writing up summaries of each link (the original list was just a list of links), and here we are. When I sit down to write something, I generally have an idea of the approach I'm going to take, but I frequently end up changing my mind when I start looking at the data.
For example, since going from hardware to software, I've had this feeling that conventional software testing is fairly low ROI, so when I joined Twitter, I had this idea that I would look at the monetary impact of errors (e.g., serving up a 500 error to a user) and outages and use that to justify working on testing, in the same way that studies looking into the monetary impact of latency can often drive work on latency reduction. Unfortunately for my idea, I found that a naive analysis found a fairly low monetary impact and I immediately found a number of other projects that were high impact, so I wrote up a doc explaining that my findings were the opposite of what I needed to justify doing the work that I wanted to do, but I hoped to do a more in-depth follow-up that could overturn my original result, and then worked on projects that were supported by data.
This also frequently happens when I write things up here, such as this time I wanted to write up this really compelling sounding story, but, on digging into it, despite it being widely cited in tech circles, I found out that it wasn't true and there wasn't really any interesting there. It's qute often that when I look into something, I find that the angle of I was thinking of doesn't work. When I'm writing for work, I usually feel compelled to at least write up a short doc with evidence of the negative result but, for my personal blog, I don't really feel the same compulsion, so my drafts folder and home drive are littered with abandoned negative results.
However, in this case, on digging into the stories in the links and talking to people at various companies about how these systems work, the problem actually seemed worse than I realized before I looked into it, so it felt worth writing up even if I'm writing up something most people in tech know to be true.
[return]{kind=link}